



Inhaltsverzeichnis
KI kann dir helfen, das leere Blatt zu füllen, aber dafür musst du das richtige Large Language Model (LLM) wählen.
Hier zeigen wir dir das zuverlässigste LLM-Ranking, basierend auf den tatsächlichen Schreibfähigkeiten der Modelle.
Außerdem liefern wir dir eine Praxisanalyse anhand von sieben verschiedenen Schreibaufgaben, damit du einen konkreten Eindruck von ihrem Schreibstil bekommst.

✨ Lerne Muse kennen — Das LLM für Storyteller
Wenn du dir jemals gewünscht hast, dass deine KI mit echter Emotion, Rhythmus und einer eigenen Stimme schreibt – genau dafür wurde Muse von Sudowrite entwickelt. Es ist die einzige KI, die ausschließlich auf herausragende fiktionale und kreative Texte trainiert wurde. So klingen deine Szenen, Charaktere und Dialoge lebendig und menschlich.
Von uns getestet & empfohlen!
*Keine Einrichtung oder Kreditkarte erforderlich – öffne einfach Sudowrite und probiere Muse aus.*
Wie wir die LLM-Modelle bewertet haben
Um die besten Modelle fürs Schreiben zu finden, haben wir zwei Kriterien angesetzt: objektive Daten und praxisnahe Schreibaufgaben.
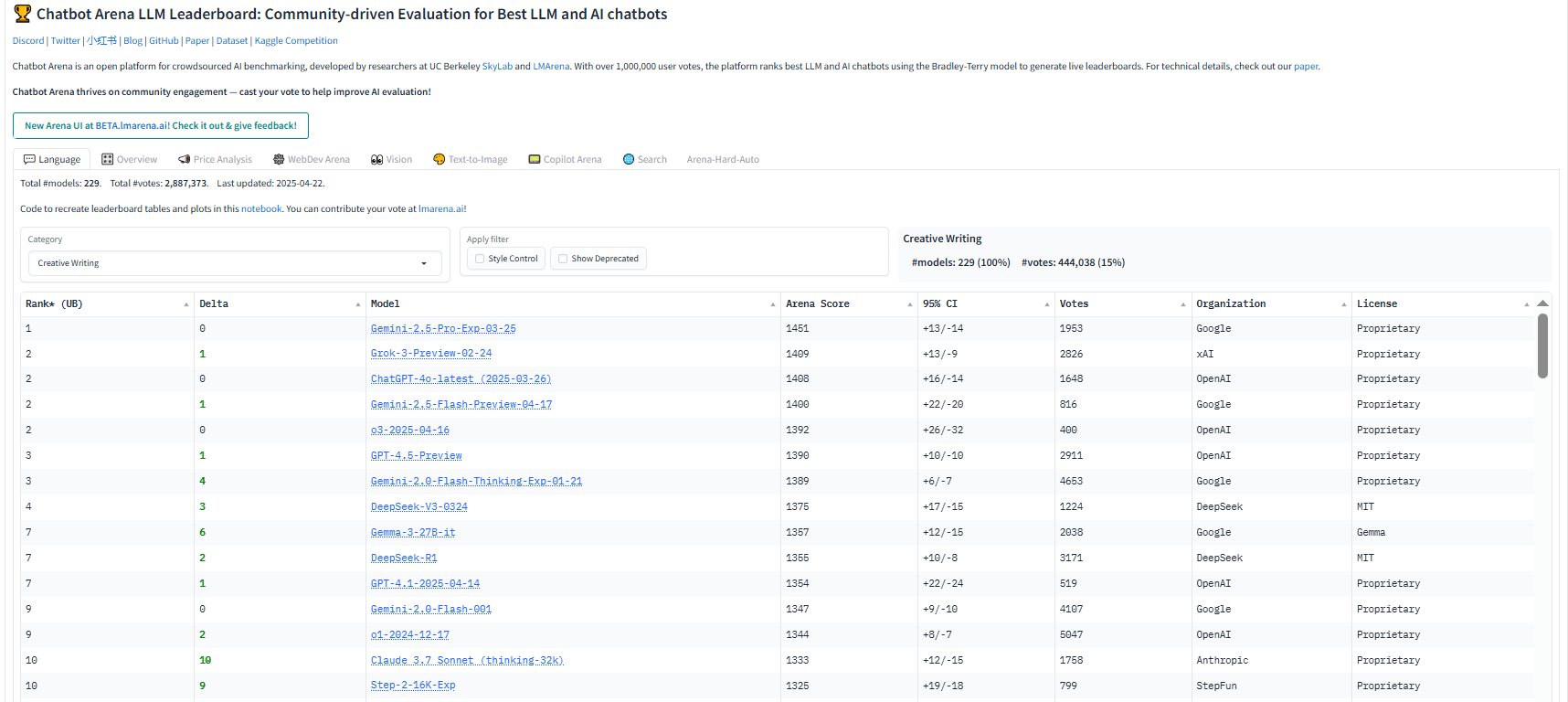
Zunächst ein Blick auf die Chatbot Arena
Die Chatbot Arena ist eine von LMSYS betriebene, auf Crowdsourcing basierende Rangliste. Sie vergleicht Large Language Models (LLMs) anhand von Nutzerpräferenzen bei vielen verschiedenen Aufgaben – einschließlich kreativem Schreiben.
Wir haben uns die Modelle aus der Kategorie Kreatives Schreiben (Creative Writing) angesehen. Das bot uns eine faire Ausgangsbasis: Welche LLMs schneiden gut ab, wenn Nutzer tatsächlich über die Textqualität abstimmen.
Anschließend haben wir dieses Ranking mit ihrer allgemeinen Leistung verglichen.
Wenn ein Modell beim Schreiben deutlich besser abschneidet als in der Gesamtwertung, ist das ein gutes Zeichen für eine besondere Stärke (insbesondere bei kleineren Modellen).
Anschließend haben wir sie selbst getestet
Wir haben sieben Schreibaufgaben entworfen, die den echten Alltag von Profis wie dir widerspiegeln:
- Eine fiktionale Szene (mit engen kreativen Vorgaben)
- Ein Gedicht (mit Metrum, Bildsprache und einem Twist)
- Ein SEO-Blogbeitrag (mit Keyword-Platzierung und Struktur)
- Landingpage-Texte (mit klarer Hierarchie und Überzeugungskraft)
- Ein Kurzessay (mit klarer These und Belegen)
- Eine wissenschaftliche Forschungsnotiz (mit Zitaten und Fakten)
1. Claude (Opus 4.6)

Wenn ich momentan eine LLM-Familie für das Schreiben ganz oben auf die Liste setzen müsste, dann wäre es Claude Opus 4.6.
Der Grund ist simpel: Claude bringt immer noch das meiste Leben in einen Satz. Es ist besser als die meisten anderen Modelle darin, eine Stimme konstant zu halten, Dialoge zu schreiben, die absichtsvoll klingen, und emotionale Nuancen über den gesamten Text hinweg zu transportieren – nicht nur für einen einzigen Absatz.
Claude ist nicht unbedingt das strengste Modell, wenn es um strikte Vorgaben geht. Für reine Anleitungen, technische Erklärungen oder sehr faktenbasierte SEO-Texte kann sich Gemini oft präziser anfühlen. Aber genau das ist der Kompromiss, der Claude so nützlich macht: Es bietet einen besseren Rhythmus, natürlichere Formulierungen und klingt weit weniger nach einem typischen „KI-Erklärbär“.
Technische Daten (Claude Opus 4.6)
- Kontextfenster (Eingabe): 1.000.000 Token. Ausgabefenster (einzelne Antwort): bis zu 128.000 Token. Die API-Dokumentation von Anthropic für Claude 4.6 listet Opus 4.6 mit einem 1M-Token-Kontextfenster, „Extended Thinking“ und einem verdoppelten Ausgabe-Limit von 128K auf.
- Verfügbarkeit / Hosting: Anthropic API, Google Vertex AI, Amazon Bedrock. Anthropic, Google Cloud und AWS bieten alle Opus 4.6 auf ihren Plattformen an.
- Privat / Lokal: Kein lokales oder Offline-Hosting. Claude wird als Managed Model über Anthropic oder Partner-Clouds bereitgestellt und nicht als Open-Weights-Modell.
Platzierung in den Ranglisten
Claude 4.6 befindet sich in den öffentlichen Ranglisten in der absoluten Spitzenklasse, auch wenn es nicht jedes einzelne Board dominiert. In der aktuellen Momentaufnahme der Chatbot Arena ist Claude Opus 4.6 Thinking das bestplatzierte Modell insgesamt im Text-Leaderboard und liegt bei den Arena-Elo-Werten knapp vor Gemini 3.1 Pro.
In den Live-Nutzungsrankings von OpenRouter gehören sowohl Claude Sonnet 4.6 als auch Claude Opus 4.6 zu den am häufigsten genutzten Modellen. Auch EQ-Bench verfolgt Claude 4.6 aktiv auf seinem Benchmark für Creative Writing v3, und Sonnet 4.6 wird inzwischen als Judge-Modell für den Longform Writing-Benchmark von EQ-Bench eingesetzt.
Praxisanalyse (aus unseren Testreihen)
So hat sich Claude bei den Aufgaben geschlagen, die für Content-Teams wirklich zählen.
- Kreatives Schreiben (Kurzgeschichte + Sonett). Das ist immer noch die absolute Paradedisziplin von Claude. Es lieferte die natürlichsten Dialoge, die glaubwürdigsten Charakterintentionen und den saubersten Rhythmus im Sonett-Test. Der Text wirkte wirklich geschrieben, nicht bloß aus Bausteinen zusammengesetzt. Wenn dein Content von Storytelling, Skripten, Gründer-Newslettern oder einer ausdrucksstarken Markenstimme abhängt, ist Claude der einfachste Einstieg.
- SEO-Gliederung + Entwurf. Claude hat sich gut an die Anweisungen gehalten, neigt aber standardmäßig zu einem leicht lyrischen Stil. Das ist für erzählerische Stücke völlig in Ordnung, aber nicht ideal, wenn man Texte braucht, die exakt auf Suchintentionen zugeschnitten sind. Wir haben das gelöst, indem wir klare Entity-Ziele, verbotene Phrasen und Wortbegrenzungen pro Abschnitt vorgegeben haben. Mit diesen Leitplanken wurde das Ergebnis absolut produktionstauglich.
- Argumentativer Essay + literarischer Erklärtext. Hier funktioniert der Workflow von Opus zu Sonnet hervorragend. Opus 4.6 bewältigte Mehrfachbehauptungen, Gegenargumente und lange Argumentationsketten mit größerer Kontrolle. Anschließend eignete sich Sonnet 4.6 besser für schnelle Überarbeitungen und Umschreibungen. Wenn du recherchebasierten Thought-Leadership-Content schreibst, ist dieses Zusammenspiel sehr praktisch.
- Landingpage + Social-Media-Varianten. Claudes Ton-Kontrolle ist stark, aber es neigt manchmal dazu, den Text zu stark zu formatieren oder mit einer Einleitung zu beginnen, die zu blumig wirkt. Eine kurze Stil-Vorgabe (Style Card) löst dieses Problem in den meisten Fällen.
Preise
Claude-Abos (Claude.ai): Kostenlos, Pro für 20 $/Monat (oder 17 $/Monat bei jährlicher Abrechnung) und Max ab 100 $/Monat. Laut Anthropics Preisseite bietet Pro eine höhere Nutzung, Zugriff auf mehr Claude-Modelle sowie Funktionen wie Research, Claude Code und Projects, während Max die Nutzungslimits weiter erhöht.
API-Preise (pro Million Token):
Sonnet 4.6: 3 $ Eingabe / 15 $ Ausgabe.
Opus 4.6: 5 $ Eingabe / 25 $ Ausgabe.
Haiku 4.5: 1 $ Eingabe / 5 $ Ausgabe. Anthropic bietet auch Rabatte für Prompt-Caching und Batch-Verarbeitung an, was die Produktionskosten erheblich senken kann.
2. Gemini (3.1 Pro)

Gemini 3.1 Pro ist meiner Meinung nach ein äußerst vielseitiges LLM, das man besonders für seriöse Textarbeit nutzen kann. Seine Kernstärke ist eine Mischung aus logischem Denken, Kontrolle bei langen Texten und inhaltlicher Konsistenz.
Das macht es besonders stark für SEO-Texte, Essays und rechercheintensive Inhalte, bei denen man eine detaillierte Struktur benötigt, ohne den roten Faden zu verlieren.
Es ist nicht das lyrischste Modell für Fiktion. Claude bringt bei Dialogen und Bildsprache immer noch mehr natürlichen Funken hinein. Aber Gemini 3.1 Pro bleibt kohärent, befolgt Anweisungen hervorragend und verliert bei langen Entwürfen seltener die Kontrolle als die meisten anderen Modelle.
Technische Daten
- Kontextfenster (Eingabe): 1.048.576 Token. Ausgabefenster: 65.536 Token. Modell-Code:
gemini-3.1-pro-preview. - Hosting-Optionen: Vertex AI, Google AI Studio / Gemini API, Gemini App, Gemini Enterprise, NotebookLM, Gemini CLI und die agentenbasierten Entwicklertools von Google.
- Native multimodale Eingaben: Text, Bild, Video, Audio und PDF. Ausgabe: Text. Das ist besonders praktisch, wenn man vor dem Schreiben Strukturen aus PDFs, Präsentationen, Screenshots, Berichten oder langen Recherchedateien extrahieren möchte.
- Fähigkeiten: Thinking (Denken), Function Calling, Codeausführung, strukturierte Ausgaben, Google Search Grounding, URL-Kontext, Batch-API und Caching werden unterstützt.
Platzierung in den Ranglisten
Gemini 3.1 Pro belegt im Text-Leaderboard der Chatbot Arena aktuell Platz 3 – direkt hinter Claude Opus 4.6 – und Platz 1 in der Kategorie Kreatives Schreiben. Auch in den Live-Rankings von OpenRouter gehört „Gemini 3 Pro“ für gewöhnlich zu den am häufigsten genutzten und bestbewerteten Modellen.
Praxisanalyse
Bei den Schreibaufgaben hat sich gezeigt, dass Gemini 3.1 Pro eher das Modell für die „ernsthafte Arbeit“ ist.
- SEO-Briefing → Gliederung: Es ist extrem gut darin, saubere H2/H3-Strukturen aufzubauen, Ideen logisch aneinanderzureihen und nah an der Suchintention zu bleiben. Hier spart Gemini oft viel Zeit bei der Bearbeitung. Man erhält weniger vage Gedankensprünge und mehr nützliche, prozessorientierte Schritte. Das passt perfekt zu Googles eigener Positionierung des Modells als Spezialist für komplexes Denken und mehrstufige Ausführung.
- Langform- und Recherchetexte: Hier glänzt 3.1 Pro besonders. Es wurde gebaut, um große Informationsmengen zu synthetisieren, und das 1M-Token-Kontextfenster bietet genug Platz, um Styleguides, Notizen, Beispiele und Quellmaterial in einem einzigen Durchlauf zu verarbeiten. In der Praxis macht es das zu einer starken Wahl für Essays, erklärende Literatur und recherchebasierte Artikel.
- Faktische Konsistenz: Google gibt explizit an, dass 3.1 Pro fundierter und inhaltlich konsistenter ist als Gemini 3 Pro. Für Content-Marketer ist das weitaus wichtiger als ein minimal hübscherer Satzbau. Es bedeutet schlichtweg, dass weniger riskante oder falsche Behauptungen im Entwurf landen.
- Kreatives Schreiben: Es ist absolut fähig, aber nicht das erste Modell, das ich für fiktionale Texte wählen würde. Die Prosa ist meist kohärent und gut kontrolliert, kann sich aber etwas „zu sicher“ anfühlen, es sei denn, man füttert es mit sehr starken Stil-Beispielen. Wer also üppige Bildsprache oder eine sehr menschliche Erzählstimme sucht, wird nach Geminis erstem Entwurf vielleicht noch einen Durchgang mit Claude machen wollen. Für sachliche Markentexte ist diese „sichere“ Qualität jedoch oft von Vorteil.
Preise
Gemini API / AI Studio: Token-basierte Preisgestaltung. Für Prompts bis zu 200K Token listet Google 1,25 $ pro 1M Eingabe-Token und 10 $ pro 1M Ausgabe-Token. Für Prompts über 200K Token steigen die Preise auf 2,50 $ für die Eingabe und 15 $ für die Ausgabe pro 1M Token.
Context Caching: 0,125 $ pro 1M Token für Prompts bis zu 200K und 0,25 $ pro 1M über 200K, plus Speichergebühren. Das ist wichtig, wenn du umfangreiche Styleguides, Produktdokumentationen oder riesige Rechercheblöcke für viele Entwürfe wiederverwenden willst.
Grounding mit Google Search: 1.500 gegroundete Prompts pro Tag kostenlos, danach 35 $ pro 1.000 gegroundete Prompts.
Abo-Pakete: Google AI Pro- und Ultra-Tarife beinhalten einen höheren Zugriff auf Gemini 3.1 Pro in der Gemini-App sowie Integrationen für Deep Research und Workspace. Das ist der einfachere Weg, wenn dein Team hauptsächlich in den Google-Apps und nicht über die API arbeitet.
Vertex AI: Die Enterprise-Lösung für Governance, Kontingente und unternehmensweite Kontrollen. Die Preisgestaltung orientiert sich am modellbasierten Abrechnungsmodell der Google Cloud. Nutze diesen Weg, wenn du Überwachung, Sicherheitsrichtlinien oder einen formelleren Bereitstellungsprozess benötigst.
3. Grok (Grok 4.2)

Wenn ich momentan noch ein drittes Modell auf das Treppchen fürs Schreiben stellen müsste, wäre es Grok 4.2.
Grok schreibt kantiger als die meisten Spitzenmodelle. Es bezieht schneller Stellung, nutzt ungewöhnlichere Referenzen und scheut sich nicht davor, meinungsstark aufzutreten. Das macht es besonders interessant für Essays, Kommentare, von Gründern verfasste Texte und eigentlich für jeden Beitrag, bei dem man einen klaren Standpunkt statt einer neutralen Erklärung haben möchte.
Allerdings ist Grok nicht das kontrollierteste Modell in diesem Ranking. Claude ist eleganter, Gemini präziser. Grok nutzt man, wenn man mehr Charakter im Text will.
Technische Daten
- Kontextfenster (Eingabe): 2.000.000 Token. Sowohl die Reasoning- als auch die Non-Reasoning-Version von Grok 4.20 Beta werden von xAI mit einem 2M-Token-Kontextfenster gelistet. Das gibt dir genug Platz für vollständige Transkripte, lange Recherche-Notizen, mehrere Quelldokumente und einen Styleguide in einem einzigen Prompt.
- Ausgabefenster: xAI hat auf den öffentlichen Modell- und Preisseiten kein separates Limit für die maximale Token-Ausgabe für Grok 4.20 Beta veröffentlicht. Veröffentlicht werden jedoch die Ausgabepreise, und die API unterstützt Streaming-Antworten. Die praktische Konsequenz ist also, dass lange Antworten unterstützt werden, xAI aber derzeit keine feste Zahl für ein „maximales Ausgabefenster“ angibt, wie es manche andere Anbieter tun.
- Verfügbarkeit / Hosting: xAI API und das Grok App / Grok.com-Ökosystem. xAI gibt außerdem an, dass Grok 4 für SuperGrok– und X Premium+-Abonnenten verfügbar ist.
- Privat / Lokal: Es gibt keine offiziell veröffentlichte, lokal hostbare Version von Grok. Die dokumentierten Zugangswege von xAI sind die eigene verwaltete API, die Enterprise-API und Consumer-App-Abonnements, nicht aber offene Gewichte oder herunterladbare lokale Builds.
- Geschwindigkeit: Das ist eines der stärksten Verkaufsargumente für Grok 4.20 Beta. xAI bewirbt das Modell explizit mit „branchenführender Geschwindigkeit“, und das breitere API-Angebot umfasst auch Grok Fast- und Grok 4.1 Fast-Varianten für günstigere Durchläufe oder höheren Durchsatz.
- Datenlage / Vibe: Grok ist eng mit xAIs Echtzeit-Suche und Tool-Stack verbunden. In der Praxis bedeutet das frischere Referenzen, mehr kulturelle Tiefe und manchmal einen aggressiveren Ton als bei anderen Modellen. Das kann ein Vorteil sein – vorausgesetzt, deine redaktionellen Leitplanken sitzen fest.
Platzierung in den Ranglisten
In der aktuellen Chatbot Arena belegt Grok-4.20 den dritten Platz im Ranking für kreatives Schreiben, direkt hinter Gemini-3.1-Pro und Claude Opus 4.6 Thinking.
Auch OpenRouter listet Grok 4.20 Beta als das neueste Flaggschiffmodell von xAI, mit einem Kontextfenster von 2M Token und einer sehr hohen Sichtbarkeit im Modellkatalog.
Praxisanalyse (aus unseren Testreihen)
So verhielt sich Grok bei den entscheidenden Schreibaufgaben.
- Kreatives Schreiben. Grok war auf eine sehr nützliche Weise das unberechenbarste Modell. Es hat mehr riskiert. Es griff nach seltsameren Settings, schärferen tonalen Wendungen und unkonventionelleren Referenzen. Manchmal führte das zum einprägsamsten Text der gesamten Testreihe. Manchmal war das Ergebnis auch ungeschliffener als bei Claude. Aber selbst wenn es daneben lag, war es so gut wie nie langweilig.
- Essays und Meinungsartikel. Hier wurde Grok besonders interessant. Es brachte oft Referenzen oder Blickwinkel ein, die die anderen Modelle ignorierten. Bei einem Test für einen Essay wählte es beispielsweise einen eher ideologischen Rahmen anstelle des üblichen, sicheren Mittelwegs. Das kann extrem wertvoll sein, wenn man möchte, dass ein Text Profil und Rückgrat zeigt.
- SEO-Gliederung → Entwurf. Grok war hier in Ordnung, aber nicht auf Elite-Niveau. Es folgte dem Briefing, deckte die Entities ab und blieb beim Thema. Das Problem: Es zog oft eine scharfe Formulierung einer ruhigen, schrittweisen Erklärung vor. Für praktische SEO-Texte bedeutet das, dass man ein strikteres Briefing braucht: genaue Anzahl der H2/H3-Überschriften, verbotene Metaphern, Vorgaben zur Satzlänge und strengere Formatierungsregeln.
- Fakten und Quellen. Der Vorteil der Echtzeitsuche von Grok ist ein zweischneidiges Schwert. Man bekommt aktuellere Bezüge und mehr Zeitgeist. Aber man braucht auch einen strengeren menschlichen Faktencheck, denn das Modell zieht mitunter Quellen heran, die zwar interessant, aber (noch) nicht unbedingt autoritär oder verlässlich sind.
Preise
xAI API-Preise:
Grok 4.20 Beta (Reasoning): 2,00 $ / 1M Eingabe-Token und 6,00 $ / 1M Ausgabe-Token.
Grok 4.20 Beta (Non-Reasoning): 2,00 $ / 1M Eingabe-Token und 6,00 $ / 1M Ausgabe-Token. Beide Versionen haben dasselbe 2M-Token-Kontextfenster.
Günstigere Fast-Varianten: xAI listet auch die Varianten Grok 4 Fast und Grok 4.1 Fast für 0,20 $ / 1M Eingabe und 0,50 $ / 1M Ausgabe, ebenfalls mit 2M Kontext. Diese sind die bessere Wahl, wenn es um Geschwindigkeit, Zusammenfassungen oder günstigere Rohentwürfe in großem Maßstab geht.
Zugang für Endnutzer: xAI gibt an, dass Grok 4 für SuperGrok– und X Premium+-Nutzer verfügbar ist. Auf der öffentlichen Hilfeseite von X beginnt Premium+ im Web bei 40 $/Monat oder 395 $/Jahr, wobei höhere Grok-Limits inklusive sind.
4. ChatGPT (GPT-5.4)
GPT-5.4 von OpenAI ist weiterhin eine solide Wahl für Sachbücher, Essays und SEO…
Trotzdem würde ich es insgesamt auf den vierten Platz setzen. Der Grund ist nicht die allgemeine Qualität. Es ist die kreative Textur. GPT-5.4 ist zuverlässiger als ältere GPT-5-Versionen, aber bei fiktionalen und erzählerischen Texten kann es immer noch etwas zu konstruiert wirken. Manche Ergebnisse sind hervorragend, andere sind zwar poliert, wirken aber emotional flach.
Technische Daten
- Kontextfenster (Eingabe): 1.050.000 Token. Ausgabefenster (einzelne Antwort): bis zu 128.000 Token. Die Modellseite von OpenAI listet GPT-5.4 mit einem 1,05M-Kontextfenster und einer maximalen Ausgabelänge von 128K auf. Das ist ein großer Sprung gegenüber der früheren GPT-5-Generation und bietet genug Platz für lange Briefings, Quellmaterial, Styleguides und Gliederungen in einer einzigen Sitzung.
- Modalitäten: Text- und Bildeingabe, Textausgabe. Audio und Video werden auf der Modellseite nicht unterstützt. Für die meisten Schreibteams reicht das völlig aus, vor allem wenn man Screenshots, PDFs, Diagramme oder visuelle Referenzen in den Entwurf einfließen lässt.
- Verfügbarkeit / Hosting: ChatGPT, OpenAI API und Codex. OpenAI hat GPT-5.4 am 5. März 2026 in ChatGPT, der API und Codex veröffentlicht.
- Privat / Lokal: Kein lokales oder Offline-Hosting. GPT-5.4 wird über die Managed Services von OpenAI bereitgestellt und nicht als herunterladbare Gewichte.
- Tools: GPT-5.4 unterstützt in der Responses-API Websuche, Dateisuche, Bildgenerierung, Code Interpreter, Hosted Shell, Computer Use, MCP und Tool-Suche. Das ist einer der Gründe, warum es für recherchebasierten Content und komplexe redaktionelle Workflows so enorm nützlich ist.
Platzierung in den Ranglisten
Auf dem aktuellen Leaderboard der Text Arena liegt die für das Schreiben optimierte Variante GPT-5.4 High insgesamt auf Platz 6 bei Texten, während das Basismodell GPT-5.4 auf Platz 16 liegt. Auf dem Leaderboard für Kreatives Schreiben belegt GPT-5.4 High derzeit den 9. Platz. GPT-5.4 ist also zweifellos ein Top-Modell, dominiert die Writing-Boards aber nicht so sehr wie Claude oder Gemini 3.1 Pro derzeit.
Praxisanalyse
Und so sah das in der Praxis aus.
- SEO-Briefing → Gliederung → Entwurf: Hier war GPT-5.4 sehr stark. Es produzierte saubere H2/H3-Hierarchien, folgte der Suchintention extrem gut und verarbeitete lange redaktionelle Vorgaben, ohne die Struktur zu verlieren. Der große Vorteil ist, dass das Modell nun sowohl die Kontextlänge als auch die Tool-Unterstützung besitzt, um Quellenmaterial, Planung und das eigentliche Schreiben in einem einzigen Workflow zu vereinen. Das macht es zu einem sehr effizienten SEO-Modell, wenn dein Prozess stark von Vorabrecherche abhängt.
- Argumentativer Essay + literarischer Erklärtext: Das ist eine seiner besten Disziplinen. GPT-5.4 ist sehr gut darin, Behauptungen zu strukturieren, zu synthetisieren und Übergänge zu schaffen, die lesbar bleiben, ohne zu verschnörkelt zu wirken. Die Entwürfe sind meistens sehr klar und professionell. Man bekommt zwar nicht denselben lyrischen Schwung wie bei Claude, hat dafür aber ein geringeres Risiko, dass der Text vom Thema abdriftet. Das ist oft der bessere Tausch, wenn der Content in erster Linie nützlich und erst in zweiter Linie stilvoll sein soll.
- Kreatives Schreiben: Hier würde ich es weiterhin hinter den Top 3 einordnen. GPT-5.4 ist besser als GPT-5.2, wirkt beim Storytelling aber immer noch etwas ungleichmäßig. Einige Kurzgeschichten sind präzise und kontrolliert. Andere stützen sich zu sehr auf Metaphern oder polierte Oberflächeneffekte, ohne dass darunter genügend emotionale Kraft steckt. Ich würde GPT-5.4 also weiterhin für Story-Strukturen, Ideenentwicklung oder das faktische Straffen nutzen und den Text dann für den narrativen Feinschliff an Claude weiterreichen.
- Redaktioneller Reibungsverlust: In unseren Tests erforderte GPT-5.4 meist weniger Nachbearbeitung bei Struktur und Faktenorganisation als beim Tonfall. Wenn deine Markenstimme klar, intelligent und nicht zu verschnörkelt ist, ist das eine echte Stärke. Wenn du mehr Wärme oder Persönlichkeit möchtest, brauchst du stärkere Few-Shot-Beispiele oder einen zweiten stilistischen Durchgang.
Preise
API-Preise: GPT-5.4 wird mit 2,50 $ pro 1M Eingabe-Token, 0,25 $ pro 1M gecachte Eingabe-Token und 15 $ pro 1M Ausgabe-Token gelistet. Für Prompts über 272K Eingabe-Token berechnet OpenAI laut eigenen Angaben GPT-5.4-Sitzungen mit dem 2-fachen Eingabe- und dem 1,5-fachen Ausgabepreis (gilt für Standard, Batch und Flex).
ChatGPT-Abos: Die Preisseiten von OpenAI geben an, dass der Zugriff auf GPT-5.4 in den kostenpflichtigen ChatGPT-Tarifen enthalten ist. GPT-5.4 Pro ist für den Pro-Tarif reserviert und bietet flexiblen Zugriff auf Business und Enterprise. Laut den Ankündigungen von OpenAI liegt ChatGPT Plus bei 20 $/Monat und ChatGPT Pro bei 200 $/Monat.
5. DeepSeek (V3.2-Exp / V3.1 / R1)
DeepSeek V3.1 ist das ausgewogenste Open-Source-LLM, das derzeit verfügbar ist. Es liefert in vielen Genres gute Ergebnisse – ob Fiktion, Essays, Gedichte oder SEO – ohne in einem bestimmten Bereich völlig herauszuragen.
Der Open-Source-Charakter ist ein massiver Vorteil: Man kann es feinabstimmen, lokal hosten und eigene Filter anwenden, was Unabhängigkeit von großen Unternehmens-Ökosystemen bedeutet. Das macht es besonders attraktiv für Autoren, die Wert auf Kontrolle und Transparenz legen oder selbst mit der Modellabstimmung experimentieren wollen.
Technische Daten
- Kontextfenster (Eingabe):
- DeepSeek-V3.2-Exp (API): 128K Token. Maximale Ausgabe: Standardmäßig 4K, bis zu 8K im Non-Thinking-Chat-Modell; der Thinking-Pfad („Reasoner“) unterstützt standardmäßig 32K / maximal 64K Ausgabe.
- DeepSeek-V3.1 (Drittanbieter): Wird oft mit ~164K Kontext angeboten; genaue Limits variieren je nach Host.
- Open-Weight Checkpoints (V3 / R1 / V3.1): Der Kontext hängt von dem Build ab, den man ausführt, und von der genutzten Server-Infrastruktur.
- Privates / lokales LLM:
- Ja (Open-Weight): Man kann die Checkpoints von V3 / R1 / V3.1 für volle Datenkontrolle und Fine-Tuning selbst hosten.
- Managed Optionen: R1- und V3-Varianten sind auch bei großen Cloud-Anbietern und Modell-Gateways verfügbar, falls man Governance wünscht, ohne eigene GPUs zu betreiben.
- Geschwindigkeit / Reaktionszeit:
- Über die API ist die Generierung absolut konkurrenzfähig und profitiert stark vom Prompt Caching. Bei lokalen Ausführungen hängt der Durchsatz von der Quantisierung, der Batch-Größe und dem GPU-VRAM ab.
- Modi, die man nutzen wird:
- Chat (V3.x) für allgemeine Texte inklusive Tool-Nutzung.
- Reasoner (R1 / V3.x „Thinking“-Modi) für tiefere Planung und mehrstufige Aufgaben. V3.1 bietet einen hybriden Wechsel zwischen Denken und Nicht-Denken – sehr praktisch, wenn man das „Denken“ nur für knifflige Passagen aktivieren möchte.
Platzierung in den Ranglisten
- Auf der LMSYS Chatbot Arena hält sich DeepSeek-R1 sowohl in der Gesamtwertung als auch bei den kreativen Kategorien im vorderen Feld.
- Bei OpenRouter gehören DeepSeek V3 / V3.1 konstant zur Gruppe mit der höchsten Nutzung unter den offenen Modellen.
- Im direkten Vergleich schlägt Qwen 2.5-Max DeepSeek manchmal bei bestimmten Reasoning- und Arena-Werten – dennoch bleibt DeepSeek die am weitesten verbreitete offene Option für Autoren, was vor allem an seinem hervorragenden Preis-Leistungs-Verhältnis liegt.
Praxisanalyse (aus unseren Testreihen)
Du suchst ein Modell, das „alles gut kann“ und leicht zu kontrollieren ist? Das ist DeepSeek.
- SEO-Briefing → Gliederung → Entwurf: DeepSeek lieferte eine solide, schrittweise Struktur und schweifte nicht ab. Es brauchte etwas Nachhilfe bei der Stimme, um generische Phrasen zu vermeiden, aber die Abdeckung von Entities und die Aufgabenabfolge waren sehr verlässlich. Wenn man seine Prompts standardisiert (Voice-Slider, verbotene Phrasen), liefert es saubere Entwürfe, die kaum noch bearbeitet werden müssen.
- Argumentativer Essay & literarischer Erklärtext: Mit aktiviertem Thinking gruppierte DeepSeek Behauptungen sehr sinnvoll und hielt die Übergänge straff. Die Quellennotizen waren brauchbar; man muss zwar trotzdem noch einen menschlichen Faktencheck machen, aber das Gerüst hielt stand.
- Kreatives Schreiben (Kurzgeschichte + Sonett): R1/V3.1 lieferte bessere fiktionale Texte als erwartet für ein offenes Modell. Das Sonett hielt Metrum und Reim überzeugend; die Kurzgeschichte war kohärent und hin und wieder originell, wenn auch in der Bildsprache im Vergleich zu Claude etwas konservativ. Wenn man mehr Farbe will, muss man stärkere Few-Shot-Stilbeispiele hinzufügen.
- Landingpage + Social-Media-Varianten: Gute Klarheit; ab und zu etwas listenlastig. Wir konnten übermäßige Formatierungen und einen Überschuss an Emojis mit einer Stylecard und strengeren Wortlimits jedoch gut eindämmen.
Preise
- Offizielle API-Preise (V3.2-Exp):
- Eingabe: 0,28 $ pro 1M Token (0,028 $ pro 1M bei einem Cache Hit)
- Ausgabe: 0,42 $ pro 1M Token
- Kontext: 128K; Ausgabelimits wie oben beschrieben (8K Chat; 64K Reasoner). Diese Raten sind auf der eigenen Preisseite von DeepSeek gelistet.
- Drittanbieter (Hosts): Einige Anbieter bewerben ~164K Kontext für V3.1 und ähnlich niedrige Preise (manchmal sogar noch günstigere Aktionspreise). Validiert vor der Budgetplanung aber immer den Kontext und die Limits pro Host.
- Open-Weight (Selbst gehostet): Die Modelldateien können kostenlos heruntergeladen werden; deine Kosten bestehen aus Compute + Ops. Wenn du bereits GPUs besitzt (oder Spot-Instanzen mietest), kann das bei hohem Durchsatz die API-Preise schlagen – allerdings zum Preis des MLOps-Overheads.
6. Qwen (Qwen 2.5-Max / Qwen 3)

Qwen (Version 2.5/3) ist ein starker Konkurrent im Open-Source-Bereich und nimmt es direkt mit DeepSeek auf.
Ich finde es besonders stark bei Essays, Literaturrecherchen und strukturierten Sachbüchern. Die Ausgaben des Modells sind oft sehr detailliert und hervorragend organisiert, auch wenn sie manchmal übermäßig stark formatiert sind. Beim kreativen Schreiben schlägt es sich ordentlich, lässt aber das erzählerische Gespür eines Claude vermissen.
Technische Daten
- Kontextfenster (Eingabe). Hier gibt es zwei Varianten, die man kennen muss:
- Open-Weight Releases. Qwen liefert offene Modelle mit bis zu 1M-Token Kontext (z.B. Qwen2.5-7B/14B-Instruct-1M), sodass man Long-Context-Entwürfe selbst hosten kann, ohne sich an einen Anbieter zu binden.
- Hosted/API SKUs. Die Spezifikationen variieren je nach Anbieter. Bei OpenRouter listet Qwen-Max (basierend auf Qwen 2.5) einen Kontext von ~32K. Im Model Studio der Alibaba Cloud bietet die Qwen Plus / 2.5 Familie gestaffelte Preise für bis zu 1M Eingabe-Token pro Anfrage an (mit separaten Modi für „Thinking“ und „Non-Thinking“). Prüfe immer, welche Version du tatsächlich ansteuerst, bevor du ein riesiges Dokument einfügst.
- Ausgabefenster. Die Ausgabelimits richten sich nach der SKU (und dem gewählten „Thinking“-Modus). Alibaba dokumentiert separate Preise/Stufen für Generierungen ohne Denken und mit Denken (≤128K, ≤256K, bis zu 1M).
- Privat / Lokal. Qwen pflegt offizielle Open-Weight-Repos (Hugging Face, GitHub). Man kann sie selbst hosten und feinabstimmen oder gemanagt über die Alibaba Cloud ausführen. Das ist ideal, wenn man Datenhaltung auf EU-Niveau oder On-Premise-Kontrolle benötigt.
- Geschwindigkeit / Modi. Erwarte schnellere, leichtere SKUs für schnelle Entwürfe und Reasoning-Modi („Thinking“) für tiefere Planung.
Platzierung in den Ranglisten
Qwen-Varianten tauchen in der Chatbot Arena bei Texten und kreativem Schreiben meist kurz hinter DeepSeek auf.
Praxisanalyse
Hier ist unsere Einschätzung aus der Praxis:
- Essays & rechercheintensive Sachbücher (stark). Die Reasoning-Modi von Qwen lieferten eine klare Gruppierung von Behauptungen, stützende Beispiele und geordnete Übergänge. Bei literarischen Erklärtexten stapelte es Zitate sehr ordentlich, wenn wir anwiesen: „Quellennotizen unter den Entwurf“. Wenn dein Alltag aus Whitepapern, Erklärtexten und Thought-Leadership besteht, kann Qwen locker mit DeepSeek mithalten.
- SEO-Briefing → Gliederung → Abschnitt. Out of the box folgte Qwen der Struktur und der Entity-Abdeckung sehr gut. Es neigte manchmal zur Überformatierung oder zum exzessiven Einsatz von Emojis in Landingpage-Texten. Das haben wir mit einer Stylecard behoben: verbotene Emojis, Wortlimits, exakte H2/H3-Anzahl und „keine endlosen Listen“. Mit diesen Leitplanken waren die Texte extrem sauber und schnell zu redigieren.
- Kreatives Schreiben. Kompetent und gelegentlich auch einfallsreich, aber nicht so lyrisch wie Claude und nicht so natürlich in der „Stimme“ wie Grok. Die Kurzgeschichtenszenen waren kohärent und entsprachen dem Briefing; das Shakespeare-Sonett war in Reim und Metrum solide. Wer mehr Farbe möchte, sollte stärkere Few-Shot-Stilbeispiele verwenden.
Preise
Das Budget hängt stark davon ab, wo du es ausführst.
- Alibaba Cloud Model Studio (API). Die Qwen Plus/2.5-Familie nutzt gestaffelte Preise nach Kontextbandbreite mit separaten Tarifen für Non-Thinking und Thinking. Aktuell dokumentierte Stufen: ≤128K, ≤256K und (256K, 1M] Eingaben.
- OpenRouter (Hosted). Qwen-Max listet etwa 1,60 $ / 1M Eingabe und 6,40 $ / 1M Ausgabe bei einem Kontext von ~32K (Anbieter können variieren). Gut für schnelle Pilottests.
- Self-hosted (Open-Weight). Die Modelldateien sind kostenlos; du zahlst für Compute + Ops.
7. Mistral (Medium 3 / Large 2.1)
Mistral ist Europas zuverlässigstes Open-Source-LLM.
Es ist ideal für Autoren und Unternehmen, die europäische Datenschutzstandards bevorzugen oder ihre Inhalte gerne lokal verwalten wollen. Was das Schreiben angeht, liegt es im Mittelfeld: strukturiert, vorhersehbar und klar, manchmal aber etwas starr oder formelhaft.
Fiktion von Mistral kann sich mitunter ein wenig mechanisch anfühlen und besitzt weniger emotionale Nuancen als Claude oder DeepSeek. Bei Sachbüchern und SEO-Texten ist das Modell jedoch sehr zuverlässig, beständig und bestens strukturiert.
Die Hauptstärke von Mistral liegt in seiner Offenheit – man kann es feinabstimmen, privat hosten und es exakt an den eigenen Workflow anpassen.
Technische Daten
- Mistral Medium 3: ~128K Token (multimodal; Text+Bild). Das ist das aktuelle Flaggschiff für allgemeine Zwecke, das Mistral für den Unternehmenseinsatz 2025 forciert.
- Mistral Large 2.1: wird bei Partnern ebenfalls mit ~128K dokumentiert. Betrachte Large als die „schwerere“ Alternative, falls du dich darauf standardisiert hast.
- Codestral 2 (Code-Fokus): 32K Kontext auf Vertex AI. Ideal, wenn man Code in Dokumentationen/Tutorials entwerfen oder refaktorieren muss.
- Ausgabefenster: Lange, gestreamte Generierungen; praktisch auf Kapitel-Länge. In der Produktion limitiert man aus redaktionellen Gründen ohnehin meist nach Abschnitt.
- Private / lokale Optionen: Mistral veröffentlicht weiterhin Open Weights mit Anleitungen zur Selbst-Bereitstellung (vLLM etc.). Wenn man eine EU-Konformität, VPC-Isolierung oder On-Premise-Tests benötigt, ist das ein zentraler Grund, sich für Mistral zu entscheiden.
Platzierung in den Ranglisten
Auf öffentlichen Präferenz-Boards positionieren sich Mistral-Modelle im Allgemeinen im Mittelfeld – oft außerhalb der Top 10, aber gut innerhalb der Top 20 für reine Text-Arenen. Die Produktseiten von OpenRouter zeigen ebenfalls solide Nutzungszahlen für Mistral Medium 3.
Praxisanalyse (aus unseren Testreihen)
Du willst wissen, wo Mistral dir beim Schreiben tatsächlich weiterhilft:
- SEO-Gliederung → Entwurf (stark genug). Mistral lieferte klare H2/H3s, eine gute Entity-Abdeckung auf der Seite und eine sinnvolle schrittweise Struktur. Es ist nicht der erfinderischste Schreiber, schweift aber selten ab. Für die SEO-Produktion ist das völlig ausreichend: Redakteuren ist Genauigkeit und Befolgung von Anweisungen meist wichtiger als blumige Prosa.
- Argumentativer Essay / Erklärtexte (solide Struktur, nüchterner Ton). Bei Essays und Erklärtexten hat Mistral die Behauptungen sauber gruppiert und die Übergänge aufgeräumt gehalten. Verglichen mit den Top-Flaggschiffen kann es sich etwas prozedural anfühlen – aber wenn deine Markenstimme pragmatisch und „Plain English“ ist, passt das wunderbar.
- Kreatives Schreiben (geht so). Dialoge und Bildsprache sind kompetent, aber die Stimme bleibt stets im sicheren Bereich und wirkt gelegentlich überformatiert (zu viele Listen). Wenn du lyrischen Schwung brauchst, solltest du einen zweiten Durchgang in Claude machen und den Entwurf für Straffung und Faktencheck wieder zu Mistral bringen.
- Landingpage + Social-Media-Varianten (Achtung beim Formatieren). Mistral übertreibt es manchmal mit Aufzählungszeichen oder streut Emojis ein. Dieses Problem löst man mit einer kleinen Stylecard: Emojis verbieten, maximale Anzahl von Bullets festlegen und H2/H3-Quoten setzen.
Preise
Die Preisgestaltung von Mistral ist einfach und vorhersehbar – und für ein „Premier“-Modell absolut wettbewerbsfähig.
- Mistral Large 24.11 (API). Öffentliche Listungen zeigen 2,00 $ pro 1M Eingabe-Token und 6,00 $ pro 1M Ausgabe-Token, bei ~128K Kontext. Das ist dein Go-to für lange, strukturierte Artikel und redaktionelle Workflows.
- Mixtral 8x22B Instruct (MoE). Oft der absolute Preis-Leistungs-Tipp: Wird bei einigen Anbietern für ca. 0,90 $ / 1M für Eingabe und Ausgabe gelistet. Wenn du kostenbewusst bist und einen leichten Qualitätsabfall gegenüber ‚Large‘ in Kauf nehmen kannst, ist diese SKU attraktiv für Massen-SEO.
- Le Chat (App). Wenn deine Autoren eine App den APIs vorziehen, bietet Le Chat kostenlose und kostenpflichtige Stufen mit Unternehmensoptionen. Ideal für Teams, die innerhalb einer Managed UI mit EU-Datenhaltung arbeiten wollen.
8. Muse 1.5 (Sudowrite)
Muse ist das einzige LLM, das speziell für fiktionales Schreiben entwickelt wurde. Die „Narrative Engineering“-Pipeline von Sudowrite hilft dem Modell dabei, zu planen, zu überarbeiten und sich strikt an das Briefing zu halten, sodass Kapitel nicht so ziellos umherschweifen, wie es bei Claude oder GPT passieren kann, wenn man auf Textlänge drängt. Es ist auch absichtlich weniger gefiltert in Bezug auf Erwachsenenthemen und Gewalt, was sehr wichtig ist, wenn man in dunkleren Genres (Dark Romance, Thriller etc.) schreibt.
Schwachstellen: Es ist exklusiv bei Sudowrite verfügbar, sodass die Flexibilität offener Schnittstellen fehlt. Die interne Logik-Konsistenz (Lore) kann bei sehr komplexen Welten manchmal etwas hinter Claude zurückbleiben, und für rein sachliche oder SEO-fokussierte Arbeiten bleiben Gemini/ChatGPT ohnehin die stärkeren Modelle.
TESTE DAS MUSE LLM HIER KOSTENLOS
Technische Daten
- Kontextfenster (Eingabe). Sudowrite veröffentlicht keinen exakten Token Count für Muse. In der Praxis arbeitet man auf der Szenen-/Kapitel-Ebene innerhalb der Draft/Write-Tools von Sudowrite. Streaming-Ausgaben und Tools (Expand, Rewrite) halten den aktiven Kontext sehr fokussiert. Wenn du harte Token-Limits suchst: Als solches wird Muse nicht vermarktet; es ist eher als reiner Fiktions-Workflow positioniert, nicht als allgemeines API-Modell.
- Ausgabefenster. Generierungen werden gestreamt und können im Draft/Write-Tool erweitert („fortgesetzt“) werden. Muse 1.5 wirbt im Vergleich zu früheren Versionen speziell mit längeren Szenen und genauerer Befolgung von Instruktionen.
- Privat / Lokal. Kein Selbst-Hosting. Muse ist exklusiv in Sudowrite (Web-App) verfügbar. Sudowrite betont jedoch, dass deine Arbeit nicht zum Trainieren von Muse verwendet wird und hebt einen ethisch korrekten Fiktions-Datensatz hervor, bei dem alle Rechte vorab geklärt wurden. Wenn dein Fokus auf autorenfreundlichen Datenversprechen innerhalb eines gehosteten Tools liegt, ist das ein großer Pluspunkt.
- Filter und Tonfall. Muse wird als „am wenigsten gefiltert“ vermarktet (es kann mit Erwachsenenthemen/Gewalt umgehen) und wurde während des Trainings aktiv von gängigen Klischees befreit. Gut zu wissen, wenn man düstere Genres schreibt – und ebenso wichtig, wenn man Marken-konforme Copy texten muss (dann braucht es Leitplanken).
Platzierung in den Ranglisten
Muse ist ein vertikales privates Modell – das rein auf Fiktion abzielt – daher wirst du es nicht ganz oben auf allgemeinen LLM-Bestenlisten finden.
Praxisanalyse
Du hast gefragt, wie es wirklich schreibt – nicht nur, wie es vermarktet wird. Wir haben ihm dieselben Aufgaben gestellt wie den anderen Modellen, aber wir haben Muse in erster Linie nach seinen Fiktions-Fähigkeiten bewertet und erst danach den Nutzen für Marketing-Texte geprüft.
- Kurzgeschichtenszene (Dialoge + sensorische Details). Muse lieferte in unserem Test die am menschlichsten klingenden Dialoge. Die Rhythmik fühlte sich natürlich an, das „Stage Business“ (Handlungen während der Gespräche) wirkte absichtsvoll, und die Prosa vermied den offensichtlichen „KI-Glanz“ (Standard-Metaphern, repetitive Kadenzen). Seine Standardstimme war lebendig ohne violette Übertreibungen und es reagierte extrem gut auf Stil-Beispiele. Das deckt sich mit der Behauptung von Sudowrite, dass Muse so konzipiert ist, dass es Klischees reduziert.
- Shakespeare-Sonett. Überraschend diszipliniert. Reim und Metrum hielten stand, während es gleichzeitig die Bildsprache bewahrte – in unserem Test absolut vergleichbar mit den besten geschlossenen Modellen. Auch die Optimierung von Muse 1.5 auf „längere Szenen“ zeigte sich hier durch eine konstantere Strophenkontrolle über das gesamte Gedicht.
- Argumentative Texte / Essays. Brauchbar, aber das ist nicht die Kernkompetenz von Muse. Es kann eine Argumentation aufbauen und den Ton konsistent halten, aber es wird grenzüberschreitende Generalisten nicht bei der Logik übertrumpfen. Wenn dein Alltag aus Essays besteht, wirst du für das Gerüst weiterhin Gemini/GPT/Claude vorziehen und Passagen vielleicht in Sudowrite zur Überarbeitung der Stimme übertragen.
- SEO / Landingpages. Muse generiert saubere Absätze und knackige Zeilen, ist aber standardmäßig nicht für Entity-Abdeckung, SERP-Mapping oder starre H2/H3-Gerüste gebaut. Wenn du ein „romaneschreibender Marketer“ bist, ist das ein großartiger „Voice-Pass“ (letzter Feinschliff), nachdem ein prozedurales Modell die Grundstruktur festgelegt hat.
Preise
Sudowrite verkauft den Zugang zu Muse über Credit-basierte Abonnements (Browser-App). Die Stufen (monatliche Abrechnung, Stand aktueller Preisseite):
- Hobby & Student — 10 $/Monat für ~225.000 Credits/Monat.
- Professional — 22 $/Monat (ca. 1.000.000 Credits/Monat als Hauptangebot).
- Max — 44 $/Monat für ~2.000.000 Credits/Monat mit einer Übertragung ungenutzter Credits über 12 Monate.
Alle Stufen umfassen die Sudowrite-App; Muse ist als Standardmodell in den Draft/Write-Tools auswählbar. Bitte bestätige vor der Budgetierung immer die aktuellsten Inklusivleistungen und Jahresrabatte auf der Preisseite.

Kostenlose Prompts und Ebook zur Humanisierung Ihrer Texte
Jetzt herunterladen
Buchert Jean-marc
Bestätigter Experte für KI-Content-Prozesse. Mit seinen Methoden hat er seinen Kunden geholfen, LLM-basierten Content zu generieren, der ihren redaktionellen Standards und den Erwartungen ihres Publikums entspricht.
Alle Beiträge
