Table of Contents
AI can fill your blank page, but better pick the right large-language model (LLM).
Here, we give you the most reliable LLM ranking based on their writing capability.
We also provide you with a sample analysis across seven writing tasks, for a concrete overview of their writing style.

✨ Meet Muse — The LLM Built for Storytellers
If you’ve ever wished your LLM could write with real emotion, rhythm, and voice – Muse by Sudowrite was created exactly for that. It’s the only AI trained purely on outstanding fiction and creative prose, so your scenes, characters, and dialogue sound vivid and human.
Tested & Recommended by us!
🚀 Try Muse For Free Here*No setup or credit card needed – just open Sudowrite and try Muse.*
How We Ranked the LLM Models
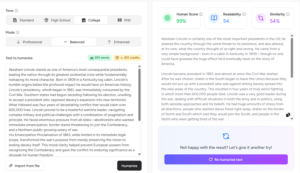
To find the best models for writing, we used two filters: objective data and real-world writing tasks.
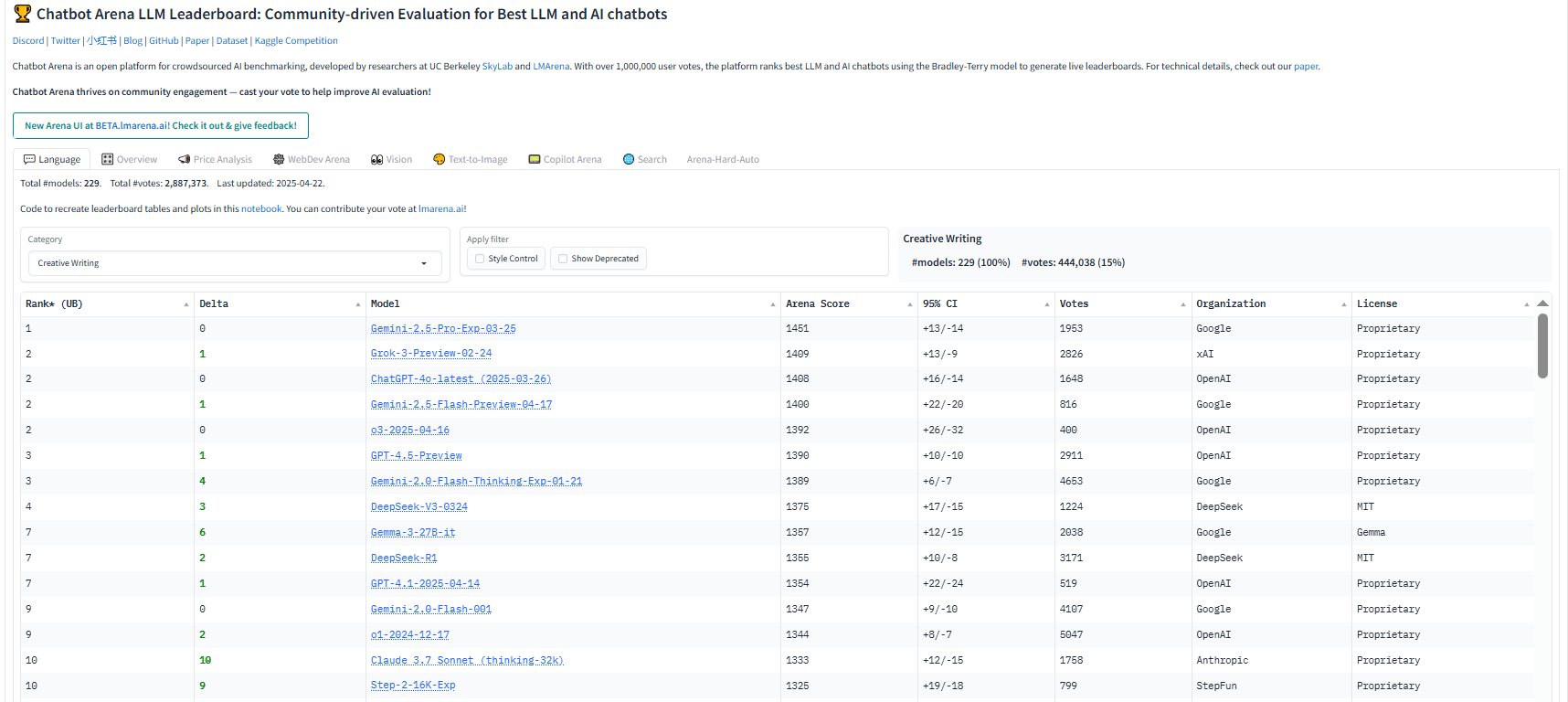
First, we looked at the Chatbot Arena
Chatbot Arena is a crowdsourced leaderboard run by LMSYS. It compares large language models (LLMs) based on user preferences across many tasks—including creative writing.
We pulled models from the Creative Writing leaderboard. This gave us a fair starting point: which LLMs perform well when users actually vote on writing quality.
Then, we compared this ranking to their general performance across all tasks.
If a model ranks much higher in writing than overall, it’s a good sign it has a special strength (especially if it’s a smaller model).
Next, we tested them ourselves
We created seven writing tasks that mirror what professionals like you actually do:
- A fictional scene (with tight creative constraints)
- A poem (with meter, imagery, and a twist)
- An SEO blog post (with keyword placement and structure)
- A landing-page copy (with hierarchy and persuasion)
- A short-form essay (with clear thesis and references)
- A scientific research note (with citations and accuracy)
1. Claude (Opus 4.7)

If I had to put one LLM family at the top for writing right now, I would pick Claude Opus 4.7.
The reason is simple. Claude still has the most life in the sentence. It is better than most models at keeping a voice stable, writing dialogue that sounds intentional, and carrying emotional tone across a full piece instead of just a paragraph.
Claude is not always the most rigid or procedural writer. For strict how-to content, technical walkthroughs, or very factual SEO sections, Gemini can still feel more exact. But that is also the tradeoff that makes Claude so useful. It usually gives you stronger rhythm, more natural phrasing, and less of that flat “AI explainer” feel.
Technical specs (Claude Opus 4.6)
- Context window (input): 1,000,000 tokens. Output window (single response): up to 128,000 tokens. Anthropic’s Claude 4.6 API docs list Opus 4.6 with a 1M-token context window, extended thinking, and a doubled 128K output cap.
- Availability / hosting: Anthropic API, Google Vertex AI, Amazon Bedrock. Anthropic, Google Cloud, and AWS all list Opus 4.6 as available on their platforms.
- Private/local: No local or offline self-hosting. Claude is delivered as a managed model through Anthropic or partner clouds rather than as open weights.
Leaderboard ranking
Claude 4.6 sits in the very top tier of public leaderboards, even if it does not own every single board outright. In the current Chatbot Arena snapshot, Claude Opus 4.6 Thinking is the highest-ranked models overall in the text leaderboard, sitting just before Gemini 3.1 Pro in Arena Elo.
On OpenRouter’s live usage rankings, both Claude Sonnet 4.6 and Claude Opus 4.6 is the most-used models. EQ-Bench also actively tracks Claude 4.6 on its Creative Writing v3 benchmark, and Sonnet 4.6 is now used as the judge model for EQ-Bench’s Longform Writing benchmark.
Sample analysis (from our battery)
Here’s how Claude behaved on the tasks that matter to content teams.
- Creative writing (short story + sonnet). This is still Claude’s best lane. It gave us the most natural dialogue, the most believable character intent, and the cleanest rhythm in the sonnet test. The writing felt written, not assembled. If your content relies on storytelling, scripts, founder letters, or a more expressive brand voice, Claude is the easiest place to start.
- SEO outline + section draft. Claude followed instructions well, but its default style can drift a little lyrical. That is fine for narrative pieces, but not ideal when you need tight search-intent writing. We fixed that by giving it entity targets, banned phrases, and word-count limits by section. Once those rails were in place, the output became much more production-ready.
- Argumentative essay + literature-style explainer. This is where the Opus → Sonnet workflow works well. Opus 4.6 handled multi-claim structure, counter-arguments, and long reasoning chains with more control. Then Sonnet 4.6 was better for fast revisions and rewrites. If you write research-backed thought leadership, that handoff is a very practical setup.
- Landing page + social variants. Claude’s tone control is strong, but it can still over-format or open with a flourish that feels too decorative. A short style card solves most of that.
Pricing
Claude plans (Claude.ai): Free, Pro at $20/month or $17/month billed annually, and Max starting at $100/month. Anthropic’s pricing page says Pro includes more usage, access to more Claude models, and features like Research, Claude Code, and projects, while Max expands usage further.
API pricing (per million tokens):
Sonnet 4.6: $3 input / $15 output.
Opus 4.6: $5 input / $25 output.
Haiku 4.5: $1 input / $5 output. Anthropic also lists prompt caching discounts and batch-processing discounts, which can materially lower production costs.
2. Gemini (3,1 Pro)

Gemini 3.1 Pro is, in my opinion, a complete LLM model you can especially use for serious writing work. Its core strength is a mix of reasoning, long-context control, and factual consistency.
That makes it especially strong for SEO writing, essay writing, and research-heavy content where you need detailed structure without losing the thread.
It is not the most lyrical model for fiction. Claude still has more natural spark in dialogue and imagery. But Gemini 3.1 Pro stays coherent, follows instructions well, and handles long drafts with less drift than most models.
Technical specs
- Context window (input): 1,048,576 tokens. Output window: 65,536 tokens. Model code:
gemini-3.1-pro-preview. - Hosting options: Vertex AI, Google AI Studio / Gemini API, Gemini app, Gemini Enterprise, NotebookLM, Gemini CLI, and Google’s agentic development tools.
- Native multimodal inputs: text, image, video, audio, and PDF. Output: text. That is useful when you want to pull structure from PDFs, slides, screenshots, reports, or long research files before drafting.
- Capabilities: thinking, function calling, code execution, structured outputs, search grounding, URL context, batch API, and caching are all supported.
Leaderboard ranking
Gemini 3.1 Pro is hitting #3 on Chatbot Arena text leaderboard just after Claude Opus 4,6 and #1 on the creative writing leaderboard. On OpenRouter’s live rankings, “Gemini 3 Pro” typically sits among the most-used and highest-rated models.
Sample analysis
On writing tasks, Gemini 3.1 Pro still looks like the “serious work” model.
- SEO brief → outline: It is very good at building clean H2/H3 structures, sequencing ideas logically, and staying close to search intent. This is where Gemini tends to save editing time. You get fewer vague jumps and more useful procedural steps. That fits Google’s own positioning of the model as stronger for complex reasoning and multi-step execution.
- Long-form and research writing: This is where 3.1 Pro becomes especially useful. It is built to synthesize large volumes of information, and the 1M-token context window gives it room to handle style guides, research notes, examples, and source material in one pass. In practice, that makes it a strong choice for essays, literature-style explainers, and research-backed articles.
- Factual consistency: Google explicitly says 3.1 Pro is more grounded and factually consistent than Gemini 3 Pro. For content marketers, that matters a lot more than a slightly prettier sentence. It means fewer risky claims slipping through your draft.
- Creative writing: It is capable, but not the first model I would pick for fiction-first work. The prose is usually coherent and well controlled, but it can still feel a bit safe unless you push it with stronger style examples. So if you want lush imagery or a more human-feeling narrative voice, you may still want a Claude pass after Gemini’s first draft. That said, for practical brand writing, this “safe” quality is often a benefit.
Pricing
Gemini API / AI Studio: Token-based pricing. For prompts up to 200K tokens, Google lists $1.25 per 1M input tokens and $10 per 1M output tokens. For prompts above 200K tokens, pricing rises to $2.50 input and $15 output per 1M tokens.
Context caching: $0.125 per 1M tokens for prompts up to 200K, and $0.25 per 1M above 200K, plus storage pricing. That matters if you reuse long style guides, product docs, or large research blocks across many drafts.
Grounding with Google Search: 1,500 grounded prompts per day free, then $35 per 1,000 grounded prompts.
Bundled subscriptions: Google AI Pro and Ultra plans include higher access to Gemini 3.1 Pro inside the Gemini app, alongside Deep Research and Workspace integrations. That is the easier route if your team mainly writes inside Google’s apps rather than through the API.
Vertex AI: Enterprise route for governance, quotas, and org-level controls. Pricing follows Google Cloud’s model-based billing. Use this lane when you need observability, security controls, or a more formal deployment path.
3. Grok (Grok 4,2)

If I had to put a third model on the podium for writing right now, I would put Grok 4.2 there.
Grok writes with more edge than most frontier models. It is quicker to take a stance, quicker to pull in unusual references, and less afraid of sounding opinionated. That makes it especially interesting for essays, op-eds, founder-led content, and any piece where you want a sharper point of view instead of a neutral explainer.
That said, Grok is not the most controlled writer in this ranking. Claude is still more graceful. Gemini is still more precise. Grok is the model you use when you want more personality.
Technical specs
- Context window (input): 2,000,000 tokens. Both the reasoning and non-reasoning versions of Grok 4.20 Beta are listed by xAI with a 2M-token context window. That gives you enough space for full transcripts, long research notes, multiple source documents, and a style guide in one prompt.
- Output window: xAI’s public model and pricing pages do not publish a separate max output-token cap for Grok 4.20 Beta. What they do publish is output pricing, and the API supports streaming responses. So the practical takeaway is that long responses are supported, but xAI does not currently expose a neat “max output window” number the way some vendors do.
- Availability / hosting: xAI API and the Grok app / Grok.com ecosystem. xAI also says Grok 4 is available to SuperGrok and X Premium+ subscribers.
- Private/local: There is no published local or offline self-hosted Grok release. xAI’s documented access paths are its own managed API, enterprise API, and consumer app subscriptions rather than open weights or downloadable local builds.
- Speed: This is one of Grok 4.20 Beta’s strongest selling points. xAI explicitly markets it as “industry-leading speed,” and its broader API lineup includes Grok Fast and Grok 4.1 Fast variants when you want cheaper or higher-throughput iterations.
- Data posture / vibe: Grok is tightly connected to xAI’s real-time search and tool stack. In practice, that means fresher references, more cultural texture, and sometimes a more aggressive tone than other models. That can be an advantage, but only if your editorial guardrails are in place.
Leaderboard ranking
In the current Chatbot Arena,, Grok-4.20 is ranked third in creative writing ranking, behind Gemini-3.1-Pro and Claude Opus 4.6 Thinking.
OpenRouter also lists Grok 4.20 Beta as xAI’s newest flagship model, with a 2M-token context window and high visibility in its model catalog.
Sample analysis (from our battery)
Here is how Grok behaved on the writing tasks that matter.
- Creative writing. Grok was the most unpredictable model in a useful way. It took bigger swings. It reached for stranger settings, sharper tonal turns, and more unconventional references. Sometimes that gave us the most memorable output in the batch. Sometimes it gave us something rougher than Claude. But even when it missed, it rarely felt boring.
- Essays and op-eds. This is where Grok became especially interesting. It often brought in references or angles that the other models skipped. In one essay sample, it reached for a more ideological frame instead of the safe middle-of-the-road one. That can be valuable when you want your content to sound like it has a spine.
- SEO outline → section draft. Grok was fine here, but not elite. It followed the brief, covered the entities, and stayed on topic. The problem is that it sometimes preferred sharp framing over steady step-by-step explanation. For practical SEO writing, that means you need a tighter brief: exact H2/H3 count, banned metaphors, sentence-length targets, and stricter formatting rules.
- Fact pattern and sourcing. Grok’s real-time search advantage cuts both ways. You get fresher references and more current texture. But you also need a stronger human fact-check process, because the model can surface sources that are interesting before they are authoritative.
Pricing
xAI API pricing:
Grok 4.20 Beta (reasoning): $2.00 / 1M input tokens and $6.00 / 1M output tokens.
Grok 4.20 Beta (non-reasoning): $2.00 / 1M input tokens and $6.00 / 1M output tokens. Both versions carry the same 2M-token context window.
Cheaper fast variants: xAI also lists Grok 4 Fast and Grok 4.1 Fast variants at $0.20 / 1M input and $0.50 / 1M output, also with 2M context. Those are the better choice when you want speed, summarization, or cheaper first drafts at scale.
Consumer access: xAI says Grok 4 is available to SuperGrok and X Premium+ users. On X’s public help page, Premium+ starts at $40/month or $395/year on web, with higher Grok limits included.
4. ChatGPT (GPT-5,5)
GPT-5.4 from OpenAI is still a solid choice for nonfiction, essay writing, SEO…
That said, I would still place it fourth for writing overall. The reason is not quality in general. It is creative texture. GPT-5.4 is more dependable than older GPT-5 variants, but in fiction and narrative writing, it can still feel a little too engineered. Some outputs are excellent. Others are polished but emotionally flat.
Technical specs
- Context window (input): 1,050,000 tokens. Output window (single response): up to 128,000 tokens. OpenAI’s model page lists GPT-5.4 with a 1.05M context window and a 128K max output length, which is a major jump over the earlier GPT-5 generation and gives you enough room for long briefs, source packs, style guides, and outline scaffolds in one session.
- Modalities: text and image input, text output. Audio and video are not supported on the model page. That is enough for most writing teams, especially if you are feeding screenshots, PDFs, charts, or visual references into the draft.
- Availability / hosting: ChatGPT, OpenAI API, and Codex. OpenAI released GPT-5.4 across ChatGPT, the API, and Codex on March 5, 2026.
- Private / local: No local or offline self-hosting. GPT-5.4 is delivered through OpenAI’s managed services rather than as downloadable weights.
- Tools: GPT-5.4 supports web search, file search, image generation, code interpreter, hosted shell, computer use, MCP, and tool search in the Responses API. This is one of the reasons it is so useful for research-backed content and complex editorial workflows.
Leaderboard ranking
On the current Text Arena leaderboard, the stronger writing-oriented variant GPT-5.4 High sits 6th overall in text, while base GPT-5.4 sits 16th overall. On the Creative Writing leaderboard, GPT-5.4 High is currently 9th. So GPT-5.4 is clearly a top-tier model, but it is not leading the writing boards the way Claude or Gemini 3.1 Pro currently are.
Sample analysis
Here’s how it worked out in practice.
- SEO brief → outline → section draft: GPT-5.4 was very strong here. It produced clean H2/H3 hierarchies, followed search intent well, and handled long editorial inputs without losing structure. The big advantage is that the model now has both the context length and the tool support to combine source material, planning, and drafting in one workflow. That makes it a very efficient SEO model if your process depends on research before writing.
- Argumentative essay + literature-style explainer: This is one of its best lanes. GPT-5.4 is very good at multi-claim structure, synthesis, and transitions that stay readable without getting too ornate. The drafts usually come out clear and professional. You do not get the same lyrical lift as Claude, but you do get a lower risk of drift. That is often the better trade if your content has to be useful first and stylish second.
- Creative writing: This is where I would still keep it below the top three. GPT-5.4 is better than GPT-5.2, but it still feels uneven on storytelling. Some short stories are sharp and controlled. Others lean too hard on metaphor or polished surface effects without enough emotional force underneath. So I would still use GPT-5.4 for story structure, idea development, or factual tightening, then pass the draft to Claude if the goal is narrative spark.
- Editorial friction: In our testing logic, GPT-5.4 usually needed less editing for structure and factual organization than for tone. If your brand voice is clean, intelligent, and not too ornamental, that is a real strength. If you want more warmth or personality, you will still need stronger few-shot examples or a second stylistic pass.
Pricing
API pricing: GPT-5.4 is listed at $2.50 per 1M input tokens, $0.25 per 1M cached input tokens, and $15 per 1M output tokens. For prompts above 272K input tokens, OpenAI says GPT-5.4 sessions are billed at 2x input and 1.5x output rates across standard, batch, and flex processing.
ChatGPT subscriptions: OpenAI’s pricing pages say GPT-5.4 access is included across paid ChatGPT plans, with GPT-5.4 Pro reserved for Pro and flexible access on Business and Enterprise. OpenAI’s plan announcements list ChatGPT Plus at $20/month and ChatGPT Pro at $200/month.
5. DeepSeek (V3.2-Exp / V3.1 / R1)
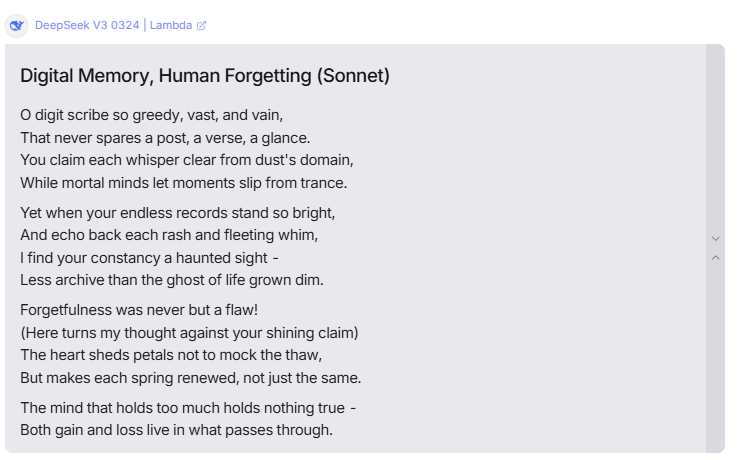
DeepSeek V3.1 is the most balanced open-source LLM available. It performs well across many genres – fiction, essays, poetry, and SEO – without being exceptional in just one area.
The open-source nature is a huge advantage: you can fine-tune, host locally, and customize your own filters, offering independence from corporate ecosystems. That makes it particularly appealing for writers who value control, transparency, or want to experiment with model tuning.
Technical specs
- Context window (input):
- DeepSeek-V3.2-Exp (API): 128K tokens. Max output: 4K by default, up to 8K on the non-thinking chat model; the thinking (“reasoner”) path supports 32K default / 64K max output.
- DeepSeek-V3.1 (providers): commonly exposed with ~164K context; exact limits vary by host.
- Open-weight checkpoints (V3 / R1 / V3.1): context depends on the build you run and the serving stack. Start from the model card and your inference framework’s limits.
- Private/local LLM:
- Yes (open-weight): You can self-host the V3 / R1 / V3.1 checkpoints for full data control and fine-tuning.
- Managed options: R1 and V3 variants are also available on major clouds and model gateways if you want governance without running GPUs yourself.
- Speed / responsiveness:
- On the API, generation is competitive and benefits from prompt caching (see pricing below). On local runs, throughput depends on your quantization, batch size, and GPU VRAM. (DeepSeek publishes optimized kernels and infra repos that help you squeeze latency.) a
- Modes you’ll use:
- Chat (V3.x) for general writing with tool use.
- Reasoner (R1 / V3.x “thinking” modes) for deeper planning and multi-step tasks. V3.1 adds a hybrid switch between thinking and non-thinking via chat template—handy when you only want “thinking” on hard passages.
Leaderboard ranking
- On LMSYS Chatbot Arena, DeepSeek-R1 sits in the leading pack across overall and creative categorie
- On OpenRouter, DeepSeek V3 / V3.1 are consistently in the high-usage cohort among open models
- In head-to-heads, Qwen 2.5-Max sometimes edges DeepSeek on certain reasoning and arena scores—but DeepSeek remains the most widely adopted open writing option because of its quality-per-cost profile.
Sample analysis (from our battery)
You want a model that’s “good at everything” and easy to control. That’s the DeepSeek vibe.
- SEO brief → outline → section draft: DeepSeek produced solid, step-wise structure and didn’t wander. It needed light voice coaching to avoid generic phrasing, but entity coverage and task sequencing were dependable. If you standardize your prompt kit (voice sliders, banned phrases), it drafts clean copy with low edit distance.
- Argumentative essay & literature-style explainer: With thinking enabled, DeepSeek grouped claims sensibly and kept transitions tight. Source notes were usable; you’ll still run a human verification pass, but the scaffolding held up.
- Creative writing (short story + sonnet): R1/V3.1 turned in better-than-expected fiction for an open model. The sonnet held meter and rhyme convincingly; the short story was coherent and occasionally inventive, if a bit conservative in imagery compared to Claude. If you want more color, add stronger few-shot style paragraphs.
- Landing page + social variants: Good clarity; sometimes list-heavy. We curbed over-formatting and emoji drift with a one-screen style card and stricter word budgets.
Pricing
- Official API pricing (V3.2-Exp):
- Input: $0.28 per 1M tokens ($0.028 per 1M with cache hit)
- Output: $0.42 per 1M tokens
- Context: 128K; output caps noted above (8K chat; 64K reasoner).
These rates are listed on DeepSeek’s own pricing page.
- Third-party hosts: Some providers advertise ~164K context for V3.1 and similarly low prices (sometimes even lower promotional rates). Always validate context and limits per host before you budget.
- Open-weight (self-hosted): Model files are free to download; your costs are compute + ops. If you already own GPUs (or rent spot instances), this can beat API pricing for heavy throughput—at the expense of MLOps overhead. Start with the official repos and kernels.
6. Qwen (Qwen 2.5-Max / Qwen 3)

Qwen 2.3 is a strong contender in the open-source category compared to DeepSeek.
I find it particularly good for essays, literature reviews, and structured nonfiction. The model’s outputs are often detailed and well-organized, though sometimes overly formatted. In creative writing, it performs decently but lacks the narrative instinct of Claude.
Technical specs
- Context window (input). There are two tracks to know:
- Open-weight releases. Qwen shipped open models with up to 1M-token context (e.g., Qwen2.5-7B/14B-Instruct-1M), so you can self-host long-context drafting without a vendor lock.
- Hosted/API SKUs. Specs vary by provider. On OpenRouter, Qwen-Max (based on Qwen 2.5) lists ~32K context. On Alibaba Cloud’s Model Studio, the Qwen Plus / 2.5 family offers tiered pricing up to 1M input tokens per request (with separate “thinking” vs “non-thinking” modes). Check which SKU you’re actually calling before you paste a megadoc.
- Output window. Output caps follow the SKU (and “thinking”/reasoning mode). Alibaba documents separate prices/tiers for non-thinking vs thinking generations as context grows (≤128K, ≤256K, up to 1M).
- Private / local. Qwen maintains official open-weight repos (Hugging Face, GitHub). You can self-host and fine-tune, or run managed via Alibaba Cloud. This is ideal if you want EU-style data posture or on-prem control.
- Speed / modes. Expect faster, lighter SKUs for drafting and reasoning (“thinking”) modes for deeper planning. As with other MoE models, throughput depends on the host and your quantization/batch choices when self-hosting.
Leaderboard ranking
Qwen variants always appear just behind DeepSeek in the Chatbot Arenatext and creative writing ranking.
Sample analysis
Here’s the practical read:
- Essays & research-heavy non-fiction (strong). Qwen’s reasoning modes delivered clear claim grouping, supporting examples, and orderly transitions. On literature-style explainers, it stacked citations neatly when we enforced “source notes below the draft.” If your calendar leans into white-papers, explainers, and thought-leadership, Qwen held its own with DeepSeek.
- SEO brief → outline → section. Out of the box, Qwen followed structure and entity coverage well. It sometimes over-formatted or leaned into emoji in landing-page copy. We fixed that with a one-screen style card: banned emoji, word budgets, exact H2/H3 counts, and “no bullet walls.” With those rails, the drafts were clean and fast to edit—very workable for production.
- Creative writing. Competent and occasionally inventive, but not as lyrical as Claude and not as naturally “voicey” as Grok. The short story scenes were coherent and on-brief; the Shakespearean sonnet was solid on rhyme/meter. If you want more color, add stronger few-shot style paragraphs or route a final punch-up to a creative-first model.
Pricing
Budget depends on where you run it.
- Alibaba Cloud Model Studio (API). Qwen Plus/2.5 family uses tiered pricing by context band with separate rates for non-thinking and thinking generations. Example bands documented today: ≤128K, ≤256K, and (256K, 1M] inputs—with per-million token rates scaling at each tier. This is your reference if you’re deploying inside Alibaba Cloud.
- OpenRouter (hosted). Qwen-Max lists around $1.60/M input and $6.40/M output with ~32K context (providers may vary). Good for quick pilots and prompt testing across vendors.
- Self-hosted (open-weight). Model files are free; you pay compute + ops. If you already have GPUs (or rent spot instances), self-hosting the 1M-context open releases can be cost-effective at volume—provided you’re ready for MLOps work.
7. Mistral (Medium 3 / Large 2.1)
Mistral is Europe’s most dependable open-source LLM.
It’s ideal for writers and organizations who prefer European data handling standards or want to keep content local. In terms of writing, it’s middle-of-the-pack: structured, predictable, and clear, though occasionally rigid or formulaic.
Fiction from Mistral can feel a bit mechanical, with less emotional nuance than Claude or DeepSeek. However, its nonfiction and SEO writing are reliable, consistent, and well-structured.
Mistral’s main strength lies in its openness — you can fine-tune it, host it privately, and adapt it to your exact workflow.
Technical specs
- Mistral Medium 3: ~128k tokens (multimodal; text+vision). This is the current general-purpose flagship Mistral pushes for enterprise use in 2025.
- Mistral Large 2.1: also documented at ~128k on partner listings. Treat Large as the “heavier” alternative if you’ve standardized on it.
- Codestral 2 (code-first): 32k context on Vertex AI (GA 2025-10-16). Use it when drafting or refactoring code in docs/tutorials.
- Output window: Long, streamed generations; practically chapter-length. In production, you’ll still cap by section for editorial control. (Vendors present output as part of the same 128k budget.)
- Private/local options: Mistral continues to publish open weights with self-deployment guides (vLLM, etc.). If you need EU posture, VPC isolation, or on-prem testing, this is a key reason teams pick Mistral.
- Where you’ll run it: Direct via La Plateforme / Le Chat, or via partner clouds/marketplaces (Vertex, Azure).
Leaderboard ranking
On public preference boards, Mistral models generally sit mid-pack—often outside the top 10 but well within the top 20 for text-only arenas, with placement shifting as new releases land. OpenRouter product pages show usage/popularity snapshots for Mistral Medium 3 across hosts.
Sample analysis (from our battery)
You want to know where Mistral actually helps you ship:
- SEO outline → section draft (strong enough). Mistral delivered clear H2/H3s, good on-page entity coverage, and sensible step-by-step structure. It isn’t the most inventive drafter, but it rarely wandered. For production SEO, that’s fine: editors care more about specificity and instruction following than purple prose.
- Argumentative essay / explainers (solid structure, sober tone). On essays and literature-style explainers, Mistral grouped claims cleanly and kept transitions tidy. Compared with top “reasoning” flagships, it can feel a bit procedural—but if your brand voice is plain-English and practical, that lands well.
- Creative writing (just okay). Your take matches ours: usable, not the most subtle. Dialogue and imagery are competent, but the voice leans safe and occasionally over-formatted (listiness). If you need lyrical lift, run a second pass in Claude and bring the draft back to Mistral for tighten + fact-check.
- Landing page + social variants (watch formatting). Mistral sometimes overuses bullets or, depending on the SKU/prompt, sprinkles emoji. Solve this with a one-screen style card: banned emoji, max bullet count, sentence-length targets, and fixed H2/H3 quotas. Once clamped, it ships clean copy with low edit distance.
Pricing
Mistral’s pricing is simple and predictable—and competitive for a “premier” model.
- Mistral Large 24.11 (API). Public listings show $2.00 per 1M input tokens and $6.00 per 1M output tokens, with ~128K context. That’s your go-to for long, structured articles and editorial workflows.
- Mixtral 8x22B Instruct (MoE). Often the value play: commonly listed around $0.90/M for input and output on some hosts, with variations by provider. If you’re cost-sensitive and can accept a small quality drop versus Large, this SKU is attractive for bulk SEO.
- Official pricing pages. Mistral’s own pricing and models overview document plans, SKUs, and Le Chat tiers. Always confirm live rates before you commit a budget.
- Le Chat (app). If your writers prefer an app over APIs, Le Chat offers free and paid tiers with enterprise options; billing for API usage is separate from app subscriptions. Good for teams that want drafting inside a managed UI with EU posture.
8. Muse 1.5(Sudowrite)
Muse is the only LLM purpose-built for fiction. Sudowrite’s “narrative engineering” pipeline helps it plan, revise, and stick to the brief, so chapters don’t meander as much as they can with Claude or GPT when you push for length. It’s also intentionally less filtered about adult themes and violence, which matters if you write darker genres.
Weak spots: it’s exclusive to Sudowrite, so you don’t get open routing freedom; internal consistency can still lag behind Claude on very intricate lore; and for hard factual or SEO work, Gemini/ChatGPT remain stronger.
TRY OUT MUSE LLM FOR FREE HERE
Technical specs
- Context window (input). Sudowrite doesn’t publish a token count for Muse. Practically, you work at the scene/chapter level inside Sudowrite’s Draft/Write tools, with streaming output and tools (Expand, Rewrite) that keep the active context focused. If you need hard token limits, Muse isn’t marketed that way; it’s positioned as a fiction workflow rather than a general API model.
- Output window. Generations stream and can be extended (“continue”) inside Draft/Write. Muse 1.5 specifically advertises longer scenes and tighter instruction following compared with earlier builds.
- Private/local. No self-hosting. Muse is exclusive to Sudowrite (web app). Sudowrite states your work isn’t used to train Muse and emphasizes an ethically consented fiction dataset. If your priority is author-friendly data promises inside a hosted tool, this is the draw.
- Filters and tone. Muse is marketed as “most unfiltered” on Sudowrite (can handle adult themes/violence) and as actively de-cliché’d during training. Good to know if you write darker genres—and equally important if you need to keep drafts brand-safe.
Leaderboard ranking
Muse is a vertical private model—aimed at fiction—so you won’t find it atop general LLM leaderboards.
Sample analysis
You asked how it writes—not just how it’s marketed. We ran the same tasks we give other models, but we judged Muse primarily on fiction-first duties and then checked its utility for marketing copy.
- Short story scene (dialogue + sensory detail). Muse produced the most human-sounding dialogue in our set. Beats landed naturally, stage business felt intentional, and the prose avoided the obvious “AI sheen” (stock metaphors, repetitive cadence). Its default voice was vivid without purple excess, and it responded well to style examples (few paragraphs of your voice). That lines up with Sudowrite’s claim that Muse is engineered to reduce clichés.
- Shakespearean sonnet. Surprisingly disciplined. Rhyme and meter held while still carrying imagery—comparable to top closed models in our test. Muse 1.5’s “longer scenes” refinement also showed up here as steadier stanza control across a full poem.
- Argumentative/essay drafts. Serviceable, but this isn’t Muse’s sweet spot. It can structure an argument and keep tone consistent, yet it won’t out-reason frontier generalists. If your calendar is essays and thought-leadership, you’ll still prefer Gemini/GPT/Claude for scaffolding, then bring passages into Sudowrite for voice work.
- SEO/landing page. Muse will generate clean paragraphs and punchy lines, but it’s not built for entity coverage, SERP mapping, or rigid H2/H3 scaffolds by default. If you’re a novelist-marketer, this is a great “voice pass” after a procedural model sets the structure.
- Control & safety. Because Muse is “less filtered,” we recommend a simple brand-safety card (banned themes/phrases, tone sliders) when you use it for public-facing copy. For fiction, that openness is a feature; for marketing, set rails.
Pricing
Sudowrite sells access to Muse via credit-based subscriptions (browser app). Tiers (monthly billing shown on the live pricing page):
- Hobby & Student — $10/mo for ~225,000 credits/month.
- Professional — $22/mo (page shows 450,000 and 1,000,000 credits copy; treat 1,000,000/month as the current headline included amount on the page).
- Max — $44/mo for ~2,000,000 credits/month with 12-month rollover of unused credits.
All tiers include the Sudowrite app; Muse is selectable as the default model in Draft/Write. Always confirm the current inclusions and yearly discounts on the pricing page before budgeting.

Free Prompts and Ebook to Humanize Your Text
Download Now
Buchert Jean-marc
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.
All Posts