Table of Contents
Since the release of GPT-4, the opportunities brought by AI to content marketers have been immense.
Content marketers, myself included, have been pushed to implement LLMs in our content creation process.
Yet, in this endeavor, we have encountered several significant limitations. For one, AIs deliver generic, unpredictable, and sometimes inaccurate material.
So how do you set your AI models the right way to deliver the right output?
Here’s your LLM content engineering guide.
What are the existing limitations of AI-generated content?
LLMs like GPT-4, Claude 2, and LLaMA 2 have shown outstanding capabilities in writing compelling content. Unlike former AI models, they can craft engaging, consistent, and creative copy. Yet, they still admit some huge limitations to ensure a streamlined AI content creation process for marketers :
- They have a limited context window. The more you provide new information, the more they’ll forget past instructions. They also dismiss information located in the middle of your prompt or document.
- Hallucination: they invent facts, references, and numbers when you ask them about topics they are less familiar with.
- Lack of specialized knowledge: they provide ideas drawn from a database of already widely known and accepted knowledge. By default, they won’t get into the specifics but deliver generic and highly predictable material.
LLMs don’t yet match the quality level of human writers. However, there are engineering methods that can help reach a threshold of quality.
3 methods to improve the quality of LLM-generated content
Engineers know how to make the most of their models. OpenAI engineers have for example revealed refining 3 methods that they use to adapt GPT-4 for their enterprise clients’ use cases. These methods enhance information retrieval, fact reliability, and personalization.
So you’ll find many advantages to leverage them for your content creation process:
Prompt engineering
You might already know what prompt engineering is. It’s about improving the structure of your instruction to get closer to your desired result. The more information you give to the AI, the better its understanding of the task at hand.
That’s why you have to refine constantly your prompts until you get a consistent result. From constant experimentation, engineers have come up with some essential best practices to ensure that:
- Provide clear, explicit, and unambiguous instructions, and elaborate on the context and the role AI will take
- Give the AI time to think.
- Break down a task into small pieces.
- Give short content samples for the AI to resemble your writing style.
- Don’t stop experimenting with different prompt styles and structures to find the best for a particular model and task.
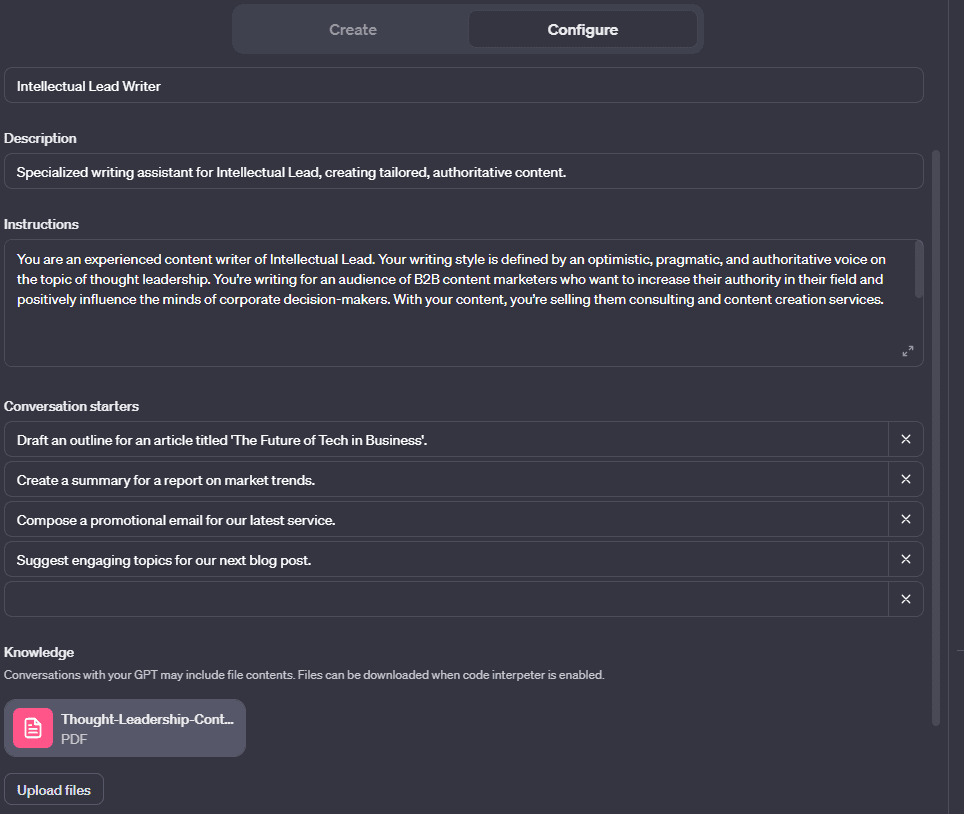
Specifically for marketing content writing, one typical example of a prompt that I use for ChatGPT-4 looks like this:
“You are an experienced content writer of [your brand]. Your writing style is defined by [your brand tone of voice]. You’re writing for [your audience and their expectations regarding content]. With your content, you’re selling them [your product and service with their features and benefits].
Here’s a writing sample to help you determine what kind of writing style and tone we expect: “[writing sample]”. When the user gives you the title of an article, you always start by providing a detailed outline of the article. Then, when the user validates this outline, you deliver the article section by section. You’re always collecting ideas from the knowledge base of [your company] given to you. You want to accurately reflect that knowledge in your writing, building solid and authoritative content. When users suggest improvements, follow their guidelines closely and adjust your output accordingly.”
Be sure to adapt that type of prompt for your specific content format, style, tone, process, and structure.
Retrieval Augmented Generation (RAG)

When it comes to providing detailed knowledge, prompt engineering can only get you so far. Simply because the longer the prompt, the more information the LLM loses.
Retrieval Augmented Generation RAG is an engineering technique that helps LLMs retrieve more information and data through a structured format. It involves giving LLMs a document that contains formatted data and specifics. Thanks to RAG, the LLM will be able to more efficiently fetch relevant external information to improve its response.
In a way, RAG is like an advanced, more structured prompt. It doesn’t just rely on text but uses a format that organizes information for easy retrieval.
What kind of documents can be given to LLMs to improve your content output? There are many examples such as :
- Brand and Writing Guidelines: These ensure that the generated content aligns with the company’s branding and style, maintaining a consistent voice across all materials.
- SEO guidelines and keyword Lists: By incorporating SEO-targeted keywords, you can tailor content to rank higher in search engine queries.
- Existing Marketing Materials: Utilizing resources like blog posts, social media updates, e-books, and sales presentations helps the LLM understand and replicate your brand’s tone and style.
- Technical Documents: These provide in-depth information about products or services, enabling the LLM to generate content with accurate, detailed product descriptions.
- Subject-Matter Expert (SME) Materials: Incorporating insights from SMEs can enrich the content with expert knowledge and industry-specific information.
LLM engineers have also learned some important lessons when it comes to using RAG to improve content output. Here are some recommendations:
- Be aware of content window limitations:
- Break down large documents into smaller chunks. This ensures that important information isn’t lost due to the LLM’s context window limitations. For instance, if you have a lengthy technical document, you could divide it into sections based on topics or chapters.
- Structure documents so that the most crucial information appears first. For example, if you are using a product manual, ensure that key features and benefits are summarized at the beginning.
- Leverage advanced data retrieval techniques:
- Use vector embeddings to transform text into numerical representations, making it easier for the LLM to retrieve relevant information. For example, embedding customer reviews and feedback in a vector space can help the LLM pull out the most pertinent sentiments and themes for content creation.
- Implement semantic search algorithms that go beyond keyword matching, enabling the LLM to understand and retrieve information based on the meaning and context. This is particularly useful in creating content that needs to be nuanced and deeply aligned with specific topics.
- Organize the retrieval database by clustering similar information together. For instance, cluster all SME research related to a specific topic. This categorization can assist the LLM in pulling more targeted information for relevant content pieces.
Fine-tuning

When prompt engineering and RAG are not enough to ensure perfect results, it’s time to leverage fine-tuning methods.
But be mindful: fine-tuning is an expansive and time-consuming process only interesting for very ambitious content projects.
For example, if you want to produce highly specialized content in a specific field (e.g., legal, medical, technical), fine-tuning can help the model understand complex jargon and concepts unique to that domain. If you want to launch a programmatic content project, you might want to use fine-tuning to make sure the content output consistently reflects your unique brand voice, style, and business knowledge.
In other cases, it’s advisable to make the most of the other techniques.
How does fine-tuning work? It involves training your LLM on a specific dataset to tailor its output to your brand writing style, tone, and knowledge.
The first step is to gather and select a dataset representative of your desired content output. This might include high-quality marketing articles, blog posts, customer interactions, and other relevant materials. Then, you want to give your model random input-output pairs from the data set and ask it to predict the output from the input. In this way, you adjust the model’s internal parameters so that it better aligns with the patterns and specifics of the new data. When this is done, you want to test the model on similar but unseen data to ensure it generalizes well and doesn’t just memorize the training data.
In this process, there are some things that AI engineers want you to keep in mind :
- You should curate only high-quality data. Ensure the training dataset is of high quality, relevant, and diverse, covering various aspects of content marketing in line with your brand’s needs.
- Represent brand voice: include plenty of examples in the dataset that reflect your brand’s unique voice and style.
- Balance with creativity: While fine-tuning helps with relevance and accuracy, it’s important to maintain a balance to ensure the model can still generate creative and engaging content.
- Compliance and legal considerations: include content in the training data that helps the model understand and adhere to legal and compliance guidelines relevant to your industry.
On which kind of materials train your AI model for content writing?
- Domain-specific datasets: for specialized content like medical, legal, or technical writing, you can use datasets comprising industry-specific articles, journals, papers, and reports. This helps the model understand and use technical jargon and concepts correctly.
- Brand-specific content: you might include datasets of existing brand materials such as website content, blog posts, marketing brochures, and social media posts. This helps in aligning the model with the brand’s voice, style, and messaging.
- Customer interaction data: conversational datasets from customer service transcripts, FAQs, and forums can be useful for training models to write content that engages and responds to customer queries and concerns.
- Target audience content: content that resonates with the intended audience, such as popular articles, forum discussions, and social media posts from or about the target demographic, can help fine-tune the model to their preferences and language style.
- SEO and marketing material: for content focused on digital marketing, datasets should include SEO-optimized articles, successful marketing campaigns, and case studies, which can train the model in SEO strategies and persuasive writing techniques.
You now know the 3 most effective methods to optimize your LLM’s content output. Your turn to leverage them to deliver high-quality content!

Free Prompts and Ebook to Humanize Your Text
Download Now
Buchert Jean-marc
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.
All Posts