




Sommaire
Depuis le lancement de GPT-4, les opportunités offertes par l’IA dans la rédaction de contenu sont immenses.
Les content marketeurs, dont je fais partie, ont été poussés du jour au lendemain à implémenter l’IA dans leur process de contenu.
Mais, dans ce projet, on fait vite face à des limites importantes. Principal problème, les modèles d’IA fournissent des informations génériques, à la fiabilité variable et parfois inexactes.
Alors, comment configurer vos modèles d’IA de la bonne manière pour obtenir les bons résultats ?
Inspirés des techniques des ingénieurs d’OpenAI, voici un guide pour perfectionner votre LLM pour le contenu.
Quelles sont les limites actuelles du contenu généré par l’IA ?
Les LLM tels que GPT-4, Claude 2 et LLaMA 2 font preuve d’une capacité exceptionnelle à rédiger des contenus convaincants. Contrairement aux modèles d’IA précédents, ils peuvent rédiger des textes accrocheurs, cohérents et créatifs.
Cependant, ils admettent encore d’énormes limitations pour assurer un processus de contenu fiable pour les marketeurs :
- Leur fenêtre contextuelle est limitée. Plus vous leur fournissez de nouvelles informations, plus ils oublient les instructions passées. Ils ignorent également facilement les informations situées au milieu ou à la fin de votre message ou de votre document.
- Hallucination : ils inventent des faits, des références et des chiffres lorsque vous les interrogez sur des sujets qu’ils connaissent moins bien.
- Manque de connaissances spécialisées : ils fournissent des idées tirées d’une base de données de connaissances déjà largement connues et acceptées. Par défaut, ils n’entrent pas dans les détails, mais fournissent un matériel générique, peu original et hautement prévisible.
Les LLM n’atteignent donc pas encore le niveau de qualité des rédacteurs humains. Cependant, il existe des méthodes d’ingénierie qui peuvent aider à atteindre un certain seuil de qualité.
3 méthodes pour améliorer la qualité des contenus générés par le LLM
Les ingénieurs savent comment tirer le meilleur parti de leurs modèles. Les ingénieurs d’OpenAI ont par exemple révélé avoir affiné trois méthodes qu’ils utilisent pour adapter GPT-4 aux cas d’utilisation de leurs clients professionnels.
Ces 3 méthodes améliorent la recherche d’informations, la fiabilité des faits et la personnalisation. Vous trouverez donc de nombreux avantages à les utiliser dans votre processus de création de contenu :
1. Prompt-engineering
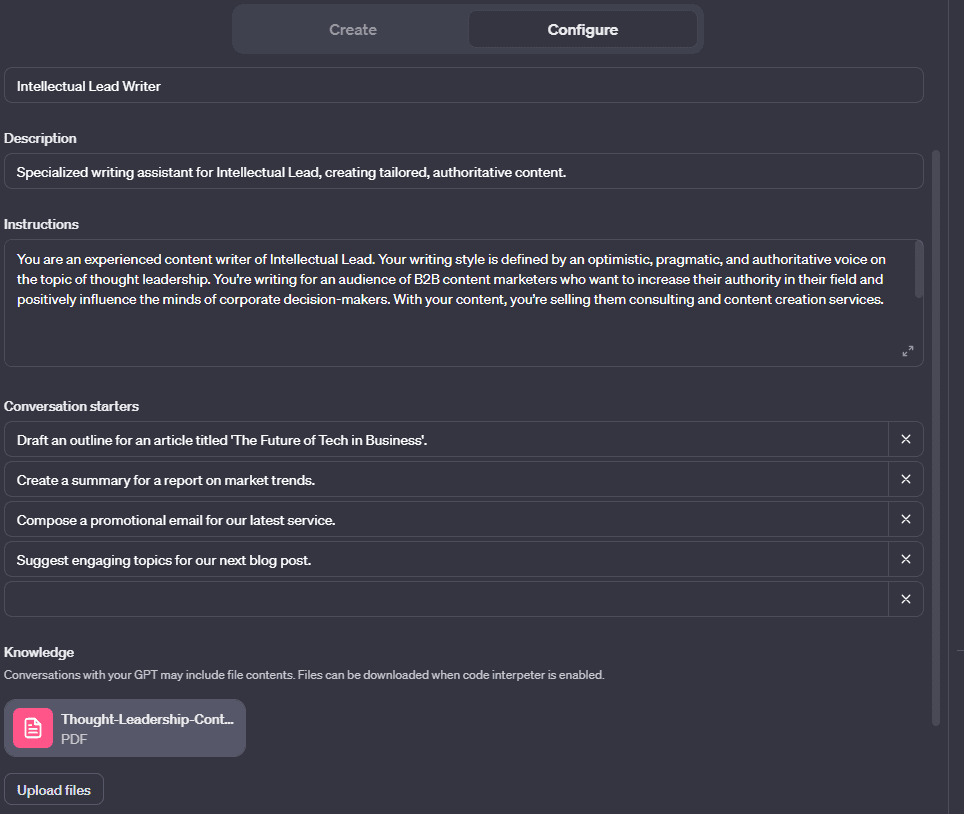
Vous savez peut-être déjà ce qu’est le prompt engineering. Il s’agit d’améliorer la structure de vos instructions pour vous rapprocher du résultat souhaité.
Plus vous donnez d’informations à l’IA, mieux elle comprendra la tâche à accomplir. C’est pourquoi vous devez constamment affiner vos prompts jusqu’à ce que vous obteniez un résultat cohérent. Grâce à une expérimentation constante, les ingénieurs ont mis au point quelques bonnes pratiques essentielles pour y parvenir :
- Fournir des instructions claires, explicites et sans ambiguïté, et préciser le contexte et le rôle que l’IA va jouer.
- Donnez à l’IA le temps de réfléchir.
- Décomposez une tâche en petits morceaux.
- Donnez de courts exemples de contenu pour que l’IA se rapproche de votre style d’écriture.
- Ne cessez pas d’expérimenter différents styles et structures d’invite afin de trouver ce qui convient le mieux à un modèle et à une tâche donnés.
En ce qui concerne la rédaction de contenu marketing, voici un exemple typique de prompt que j’utilise pour le ChatGPT-4 :
« Tu es un rédacteur de contenu expérimenté de [votre entreprise]. Ton style d’écriture est défini par [le ton de votre marque]. Tu écris pour [votre public et ses attentes en matière de contenu]. Avec ton contenu, tu veux vendre [votre produit et votre service avec leurs caractéristiques et leurs avantages].
Voici un exemple de rédaction pour t’aider à déterminer le style et le ton que nous attendons de toi : « [échantillon d’écriture] ». Lorsque l’utilisateur te donne le titre d’un article, tu commences toujours par fournir un plan détaillé de l’article. Ensuite, lorsque l’utilisateur valide ce plan, tu lui livres l’article section par section. Tu recueilles toujours des idées à partir de la base de connaissances de [votre entreprise] qui t’a été remise. Tu veux pouvoir refléter fidèlement ces connaissances dans tes écrits, afin de créer un contenu solide et faisant autorité. Lorsque les utilisateurs suggèrent des améliorations, tu suis attentivement leurs directives et adapte ta rédaction en conséquence ».
Veillez à adapter ce type de prompt au format, au style, au ton, au processus et à la structure de votre contenu.
2. Extraction de données à partir de documents (RAG)

Lorsqu’il s’agit de fournir des connaissances détaillées, le prompt engineering peut vite admettre des limites. En effet, plus l’instruction est longue, plus on perd de l’information en cours de route.
Le Retrieval Augmented Generation (RAG) est une technique d’ingénierie qui aide les LLM à récupérer plus d’informations à partir d’un format de données structurées. Elle consiste à donner aux LLM un document qui contient des données précisément formatées. Grâce au RAG, le LLM peut aller extraire plus efficacement des informations externes pertinentes pour améliorer sa réponse.
D’une certaine manière, le RAG repose sur un prompt avancé, plus structuré. Il ne s’appuie pas uniquement sur du texte, mais utilise un format qui organise l’information pour en faciliter la recherche.
Quels types de documents peuvent être fournis aux IA pour améliorer la production de contenu ? En voici quelques exemples :
- Guide de style et d’identité de marque: ces documents garantissent que le contenu généré est conforme à la marque et au style de l’entreprise, en maintenant un ton cohérent.
- Guidelines SEO et listes de mots-clés: En incorporant des mots-clés ciblés pour le référencement, vous pouvez adapter le contenu pour qu’il soit mieux classé dans les requêtes des moteurs de recherche.
- Documents marketing existants: L’utilisation de ressources telles que des articles de blog, des mises à jour de médias sociaux, des livres électroniques et des présentations de vente aide le LLM à comprendre et à reproduire le ton et le style de votre marque.
- Documents techniques : Ils fournissent des informations approfondies sur les produits ou les services, ce qui permet au modèle IA de générer du contenu avec des descriptions de produits précises et détaillées.
- Documents issus d’experts métiers : l’intégration de transcription avec les experts métiers permet d’enrichir le contenu avec des connaissances et des informations spécifiques à l’industrie.
Les ingénieurs de LLM ont également tiré d’importantes leçons de l’utilisation des RAG pour améliorer la production de contenu. Voici quelques recommandations :
- Soyez conscient des limites de la fenêtre de contenu :
- Décomposez les documents volumineux en morceaux plus petits. Cela permet de s’assurer que les informations importantes ne sont pas perdues en raison des limites de la fenêtre contextuelle du LLM. Par exemple, si vous avez un long document technique, vous pouvez le diviser en sections basées sur des sujets ou des chapitres.
- Structurez les documents de manière à ce que les informations les plus importantes apparaissent en premier. Par exemple, si vous utilisez un manuel de produit, veillez à ce que les caractéristiques et avantages principaux soient résumés au début.
- Exploitez les techniques avancées de recherche de données :
- Utilisez les vector embeddings pour transformer le texte en représentations numériques, ce qui permet au LLM d’extraire plus facilement les informations pertinentes. Par exemple, l’intégration des commentaires des clients dans un espace vectoriel peut aider le LLM à extraire les sentiments et les thèmes les plus pertinents pour la création de contenu.
- Mettez en œuvre des algorithmes de recherche sémantique qui vont au-delà de la correspondance des mots clés, permettant au LLM de comprendre et d’extraire des informations sur la base de la signification et du contexte. Ceci est particulièrement utile pour créer un contenu qui doit être nuancé et profondément aligné sur des sujets spécifiques.
- Organisez la base de données de recherche en regroupant les informations similaires. Par exemple, regrouper toutes les recherches sur les PME liées à un sujet spécifique. Cette catégorisation peut aider le mécanisme d’apprentissage tout au long de la vie à obtenir des informations plus ciblées pour des éléments de contenu pertinents.
3. Fine-tuning

Lorsque le prompt engineering et la RAG ne suffisent pas à garantir des résultats parfaits, il est temps de recourir à des méthodes de fine-tuning.
Mais attention : le fine-tuning est un processus long et fastidieux qui n’est intéressant que pour les projets de contenu très ambitieux.
Par exemple, si vous souhaitez produire un contenu hautement spécialisé dans un domaine spécifique (par exemple, juridique, médical, technique), le réglage fin peut aider le modèle à comprendre le jargon et les concepts complexes propres à ce domaine. Si vous souhaitez lancer un projet de contenu programmatique, vous pouvez utiliser la mise au point pour vous assurer que le contenu produit reflète de manière cohérente la voix de votre marque, votre style et votre connaissance de l’entreprise.
Dans d’autres cas, il est conseillé de tirer le meilleur parti des autres techniques.
Comment fonctionne le fine-tuning ? Il s’agit d’entraîner votre LLM sur un ensemble de données spécifique afin d’adapter sa production au style d’écriture, au ton et aux connaissances de votre marque.
La première étape consiste à rassembler et à sélectionner un ensemble de données représentatif du contenu que vous souhaitez produire. Il peut s’agir d’articles de marketing de haute qualité, de billets de blog, d’interactions avec les clients et d’autres documents pertinents. Ensuite, vous devez donner à votre modèle des paires d’entrées-sorties aléatoires provenant de l’ensemble de données et lui demander de prédire la sortie à partir de l’entrée.
De cette manière, vous ajustez les paramètres internes du modèle afin qu’il s’aligne mieux sur les modèles et les spécificités des nouvelles données. Une fois cette étape franchie, il convient de tester le modèle sur des données similaires mais inédites afin de s’assurer qu’il se généralise bien et qu’il ne se contente pas de mémoriser les données d’apprentissage.
Au cours de ce processus, les ingénieurs en IA souhaitent que vous gardiez à l’esprit certaines choses :
- Vous ne devez conserver que des données de haute qualité. Veillez à ce que l’ensemble de données de formation soit de grande qualité, pertinent et diversifié, et qu’il couvre les différents aspects du marketing de contenu conformément aux besoins de votre marque.
- Ajoutez dans vos données d’entraineemnt nombreux exemples qui reflètent la voix et le style uniques de votre marque.
- Trouvez un équilibre avec la créativité : Bien que le réglage fin contribue à la pertinence et à la précision, il est important de maintenir un équilibre pour s’assurer que le modèle peut toujours générer un contenu créatif et attrayant.
- Conformité et considérations juridiques : incluez dans les données d’entraînement du contenu qui aide le modèle à comprendre et à respecter les directives juridiques et de conformité propres à votre secteur d’activité.
Sur quels types de supports entraîner votre modèle d’IA pour la rédaction de contenu ?
- Ensembles de données spécifiques à un domaine : pour les contenus spécialisés tels que la rédaction médicale, juridique ou technique, vous pouvez utiliser des ensembles de données comprenant des articles, des revues, des documents et des rapports spécifiques à un secteur d’activité. Cela permet au modèle de comprendre et d’utiliser correctement le jargon et les concepts techniques.
- Contenu spécifique à la marque : vous pouvez inclure des ensembles de données de documents existants relatifs à la marque, tels que le contenu du site web, les articles de blog, les brochures de marketing et les messages sur les médias sociaux. Cela permet d’aligner le modèle sur la voix, le style et le message de la marque.
- Données sur les interactions avec les clients : les ensembles de données conversationnelles provenant des transcriptions du service client, des FAQ et des forums peuvent être utiles pour former les modèles à la rédaction de contenus qui suscitent l’intérêt des clients et répondent à leurs questions et préoccupations.
- Contenu destiné à votre audience : le contenu qui trouve un écho auprès du public visé, tel que les articles populaires, les discussions sur les forums et les messages sur les médias sociaux émanant du groupe démographique cible ou le concernant, peut aider à affiner le modèle en fonction de ses préférences et de son style de langage.
- Ressources SEO et marketing : pour le contenu axé sur le marketing numérique, les ensembles de données doivent inclure des articles optimisés pour le référencement, des campagnes de marketing réussies et des études de cas, qui peuvent former le modèle aux stratégies de référencement et aux techniques d’écriture persuasives.
Et voilà, à vous d’appliquer ces techniques pour perfectionner les résultats de rédaction de votre IA.

Prompts gratuits et Ebook pour humaniser votre texte
Télécharger Maintenant
Buchert Jean-marc
Expert confirmé en processus de contenu IA. Par ses méthodes, il a aidé ses clients à générer du contenu de qualité qui correspond à leurs exigences éditoriales et aux attentes de leur public.
Tous les Articles
