Table of Contents
Pangram positions itself as a high-accuracy, adversarially robust system designed for situations where being wrong can cause a lot of damage.
And crucially, it backs that positioning with peer-reviewed benchmarks and studies.
In this article, you’ll get a clear, evidence-based look at Pangram.
How Pangram’s Detection Algorithm Works
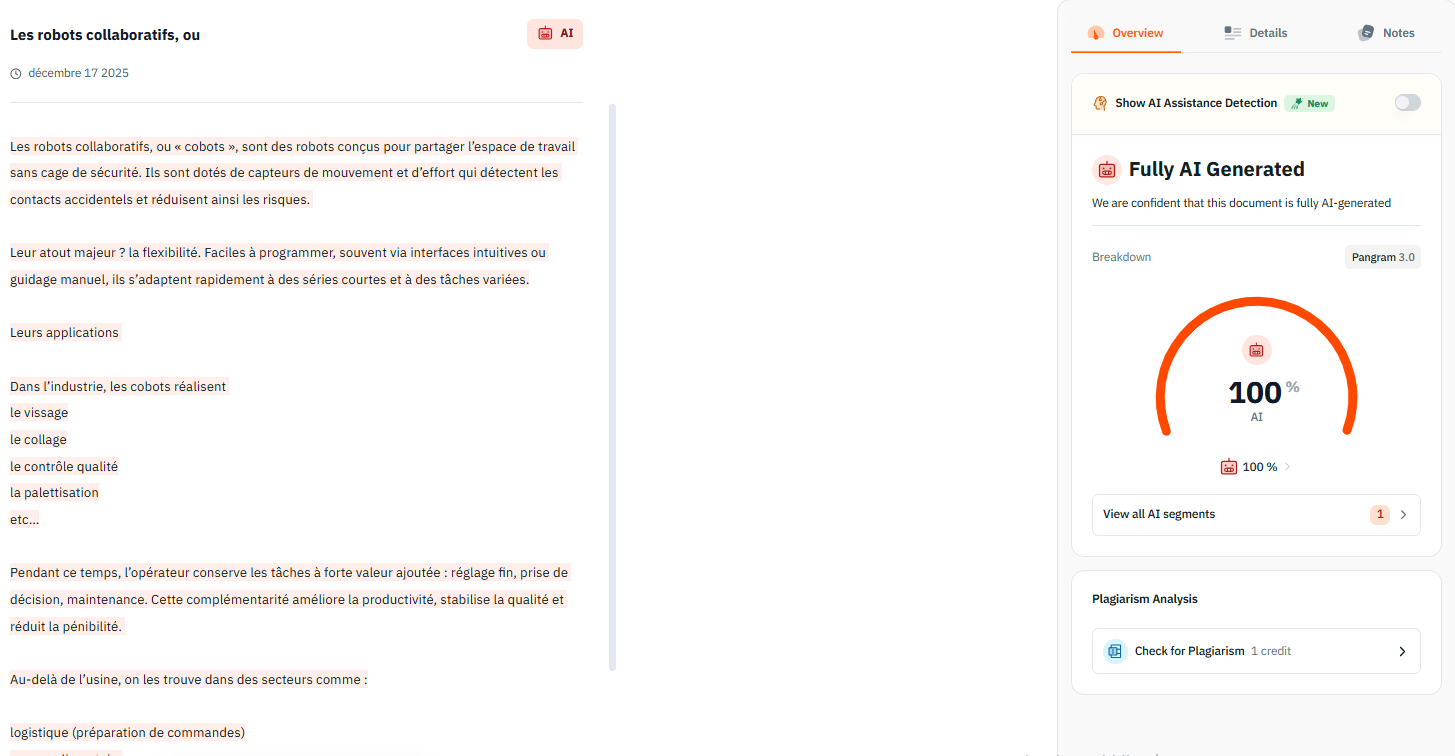
At its core, Pangram uses a transformer-based neural network classifier that’s trained to differentiate human-written text from AI-generated text.
The model first breaks the input text into tokens—small pieces of language that represent words or word fragments. Each token is then converted into a numerical vector (an embedding) that captures its meaning. Those embeddings are passed through the neural network, and a final classifier layer produces a prediction indicating whether the text is likely human or AI authored.
This is fundamentally different from older “AI detectors” that relied heavily on perplexity, burstiness, or shallow statistical measures—methods that simply look for how predictably a language model would produce a piece of text. Those approaches often fail when confronted with polished AI outputs or paraphrased human writing because they don’t actually learn the deeper stylistic patterns that distinguish one from the other.
Pangram further strengthens its model with active learning and hard negative mining during training. This means it doesn’t just train on obvious examples of human versus AI text; it also actively seeks out edge cases where the distinction is subtle and uses those harder examples to improve the classifier’s sensitivity.
Another important part of how the algorithm works is how it treats long documents. Rather than delivering a single blanket score, Pangram can segment longer texts and classify each segment separately. When the system encounters a document that contains both human-written and AI-assisted passages, it can identify the mix and provide more granular insight about what part of the text triggered the AI label.
This matters in real use cases—like editorial review or academic integrity checks—where a long document may be partially edited by AI rather than wholly generated.
Pangram Accuracy and Detection Performance
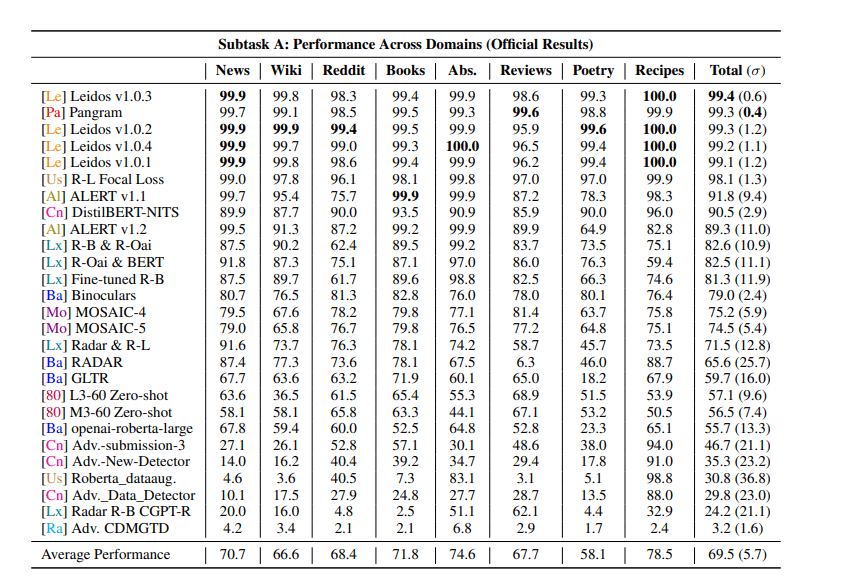
In the COLING Shared Task using the RAID dataset (biggest AI Detector performance benchmark right now, Pangram achieved the highest overall performance score among all competitors.
On standard, non-adversarial machine-generated text, Pangram reached 99.3% accuracy across multiple domains. That includes essays, news-style writing, and general prose—exactly the kinds of content most marketers, educators, and editors deal with day to day.
The COLING task also included an explicit adversarial subtask: text rewritten using common evasion techniques like paraphrasing, synonym swapping, homoglyph substitution, and sentence restructuring. What happens when people intentionally “humanize” AI output.
Here’s the key result:
- Many detectors lost 20–40% accuracy under adversarial conditions
- Pangram maintained 97.7% accuracy
In terms of false positives, independent audits and Pangram’s own whitepapers suggest that for long documents (essays, articles, reports), Pangram’s optimized false-positive rate can be driven as low as 0.01%—roughly 1 false flag per 10,000 documents.
For comparison, many widely used detectors operate in the 1–2% FPR range. That difference is not academic.
Pangram pricing
- Starter – includes more scan credits than the free tier, usually as part of a subscription.
- Premium – around $20 per month or $180 annually, with a larger monthly credit allowance for text checks.
- Pro – around $60 per month or $540 annually with even more credits for higher-volume usage.
- Developer / pay-as-you-go credit model – free sign-up with pay-per-use credits (about $0.05 per query) if you don’t need a standing subscription.
Practical pricing comparison and value
Independent evaluations suggest that Pangram is cost-efficient compared to many other detectors on a per-correctly-flagged basis. In one study, it cost about $0.0228 per correctly flagged passage, which is lower than many competitors like GPTZero or OriginalityAI.
Pangram’s best alternatives
Pangram is one of the most talked-about AI detectors right now, but it’s not the only option.
🧪 GPTZero – reliable all-purpose detector
Best for: educators, student work, and broad checks across major AI models
GPTZero is a detection tool built to flag AI-generated text from a wide range of models, including GPT-5, Gemini, Claude, and LLaMA-based tools. Its multi-step scoring method aims to minimize false positives while still giving a clear indication of AI likelihood.
Why it matters:
- Strong accuracy record and good balance between sensitivity and false positives.
- Designed to be straightforward for teachers and content reviewers who just want a reliable verdict.
- It’s often positioned as a go-to tool in academic settings where false accusations have real consequences.
When to choose it:
Choose GPTZero when you want clear scoring and minimal false flags, especially in scenarios where human writers should not be penalized accidentally.
🧠 Originality.ai – strong accuracy + plagiarism detection
Best for: professional content teams and publishers
Originality.ai combines AI detection with plagiarism scanning, making it a hybrid tool that checks both authorship and uniqueness. It reports high accuracy rates, including on paraphrased or subtly AI-edited text, and is often recommended for editorial workflows that can’t sacrifice quality.
Why it’s competitive:
- Combines plagiarism and AI detection in one interface—a practical advantage for content teams.
- Strong recall for AI and rewritten content recognizable by detectors.
When to choose it:
If your workflow integrates content quality and compliance—for example, SEO plus duplicate content checks—Originality.ai may save you time by catching both issues in one scan.
🔍 Copyleaks – high accuracy with broad model support
Best for: multilingual teams and everyday content checks
Copyleaks’ AI text detector claims over 99% accuracy even when AI writing is blended with human copy. It also supports many languages, which can matter if your editorial team works globally.
Why it’s notable:
- Good performance on hybrid content.
- Can be part of a larger content quality suite, including plagiarism checks.
When to choose it:
Copyleaks is a strong all-rounder when you need accuracy and language flexibility, for teams that work with multi-regional content.

Free Prompts and Ebook to Humanize Your Text
Download Now
Buchert Jean-marc
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.
All Posts

