Table of Contents
- What Technically Defines AI Detectors Accuracy?
- The Building Blocks of Accuracy
- Thresholds and Confidence Levels
- Are Current AI Detectors Really Accurate?
- What Level of Accuracy Should You Expect?
- Comparison of Accuracy of the Best AI Detectors
- Originality.ai: Leading Overall + Strong Paraphrase Resistance
- GPTZero: Conservative, Resilient Under Attack, but Higher Miss Rate
- Winston: High Accuracy on Major Models, but Narrow Coverage
- Copyleaks
- Turnitin
You’ve seen the bold claims: “99% accurate AI detection.” “Unbeatable precision.” “Instantly spot ChatGPT writing.”
The truth is : AI Detectors don’t measure “truth”, they measure probability. And that probability depends on multiple factors.
In this article, we’ll break it down in plain language the real accuracy you can expect from detectors.
What Technically Defines AI Detectors Accuracy?

In simple terms, accuracy describes how frequently an AI detector correctly identifies a text as human or AI.
But the story doesn’t end there. Because the way accuracy is measured depends heavily on what data was tested, how decisions were labeled, and what thresholds the detector used.
Imagine you have 100 text samples — 50 human, 50 AI-generated. If your detector correctly classifies 90 of them, you’d say it’s 90% accurate. But what if all 10 mistakes are human pieces misflagged as AI?
Accuracy numbers promoted in the market only partially reflect how the detector performs in the real world.
They are often calculated in controlled lab conditions — long, clean paragraphs, clear examples of pure human or pure AI writing. Real-world text is messier: hybrid, edited, paraphrased, and tone-mixed.
That’s why we need to look at how detectors’ accuracy really work.
The Building Blocks of Accuracy
AI detectors work as classifiers. They take text and predict: “human” or “AI.” Their performance is tracked with a confusion matrix — a table showing how often they get each prediction right or wrong.
From that, we calculate:
- Accuracy = proportion of total correct decisions.
(For instance, 90 correct out of 100 = 90% accuracy.) - Precision = when the detector says “AI,” how often it’s right.
- Recall = how many AI texts the detector successfully catches.
Here’s why this matters:
- A detector with high precision rarely mislabels human text, but it might miss some AI-generated pieces.
- A detector with high recall catches most AI text but risks over-flagging humans.
Because of that trade-off, many researchers use the F1 score, a combined average of precision and recall, to better capture overall balance.
Thresholds and Confidence Levels
Most detectors don’t simply say “AI” or “Human.” They generate a probability (e.g. 0.84 AI-likelihood) and then apply a threshold — usually around 0.5 or 0.7. Anything above that is labeled AI; anything below, human.
Changing that threshold changes the accuracy balance:
- Lower thresholds catch more AI (higher recall) but raise false positives.
- Higher thresholds protect human text (higher precision) but miss subtle AI writing.
Well-calibrated detectors aim to make these probabilities match real likelihoods — an 80% score should mean “roughly 8 out of 10 times right.” Poor calibration is one reason similar detectors can disagree.
Are Current AI Detectors Really Accurate?
You see detector tools boasting 90 %+, 98 %, or even “over 99 %” accuracy. Those sound impressive—but in practice, do they deliver?
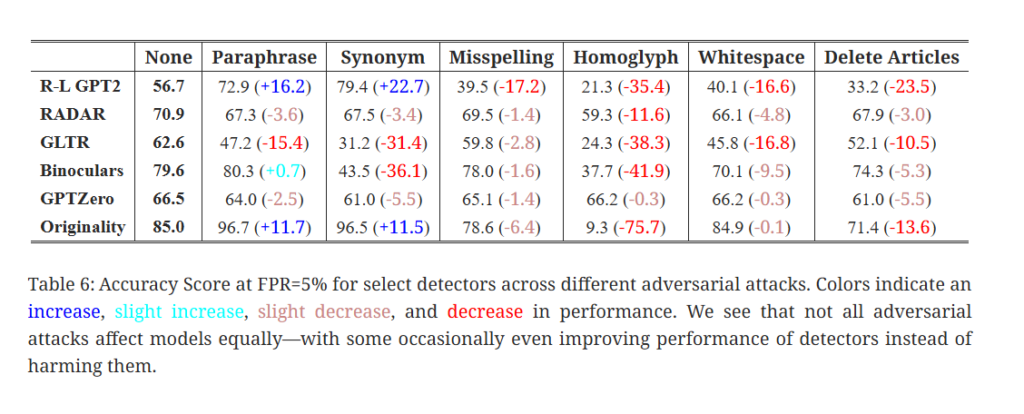
The RAID benchmark (“Robust AI Detection”) is one of the most ambitious, public evaluations to date. It covers over 6 million generated texts from 11 different LLMs, 8 content domains, 4 decoding strategies, and 11 adversarial attacks.
Key findings from RAID include:
- Many detectors that claim “99 % accuracy” fail dramatically under nonstandard conditions (e.g. alternate sampling, penalized repetition, unseen models).
- Performance drops significantly when detectors face adversarially altered text (paraphrase, synonym substitution, structure change). Even small perturbations reduce accuracy.
- The RAID benchmark suggests that 85 % accuracy in broad settings is more realistic than “99 %+ everywhere. When facing adversarial or out-of-domain text, performance often falls into the 60 % range.
Several factors contribute to this discrepancy between claimed accuracy and actual performance:
- Edited or paraphrased AI output
Once a human touches a generated text—rephrasing, adding nuance, changing word order—key signals that detectors rely on (e.g. predictability, uniform phrasing) become blurred or erased. A large experiment in GenAI detection (Perkins et al. 2024) found baseline accuracy of ~39.5 % in standard AI detection tasks. When adversarial modifications were introduced (e.g. paraphrasing, slight edits), accuracy fell to ~17.4 %. - Domain mismatch and style variation
Detectors trained on generic academic or news data may struggle with marketing copy, poetry, slang, or niche domain vocabulary. If your content’s style diverges from the detector’s training set, accuracy suffers. - Short text or fragments
Most detectors require a minimum amount of textual context to make reasonable judgments. Short paragraphs or isolated sentences may not show enough pattern or signal. - False positives on “too polished” human writing
Highly edited, refined human writing (by professional writers or editors) may resemble AI output in its uniformity. Some detectors mistakenly flag such texts as AI. - Threshold and calibration issues
A detector’s “confidence” cutoff (e.g. 0.5, 0.7) is often tuned on lab data. That threshold may not generalize to your text, leading to misclassifications. Also, some detectors are overconfident: their internal probability does not match how often they’re correct in practice. - Non-english speaker bias: AI detectors can display bias, particularly against content produced by non-native English speakers, often misclassifying it as AI-generated. This can lead to situations where your genuine content is flagged incorrectly.
- Impact of model evolutions: the continuous advancement of LLM models makes AI detectors lose accuracy and reliability over time. For example, there’s still a huge gap of accuracy considering the detection of GPT-3,5 compared to GPT-4 and Claude 3. AI detectors need to constantly adapt to stay relevant.
What Level of Accuracy Should You Expect?
Given all these limitations, what’s a realistic expectation?
- In clean, unedited AI outputs (straight from models), many detectors may hit 70–90 % accuracy in controlled tests.
- But once you bring in editing, domain variance, paraphrasing, or short samples, accuracy often falls to 50–70 % or lower.
- When adversarial modifications are present, some detectors drop below 20–40 % accuracy.
- False positive rates are especially concerning: some detectors flag substantial portions of human writing incorrectly, especially when handling polished or formal text.
Thus, the “98 % accuracy” claim you see in ads should be read skeptically—and understood as reflecting ideal conditions, not your everyday content.
Comparison of Accuracy of the Best AI Detectors
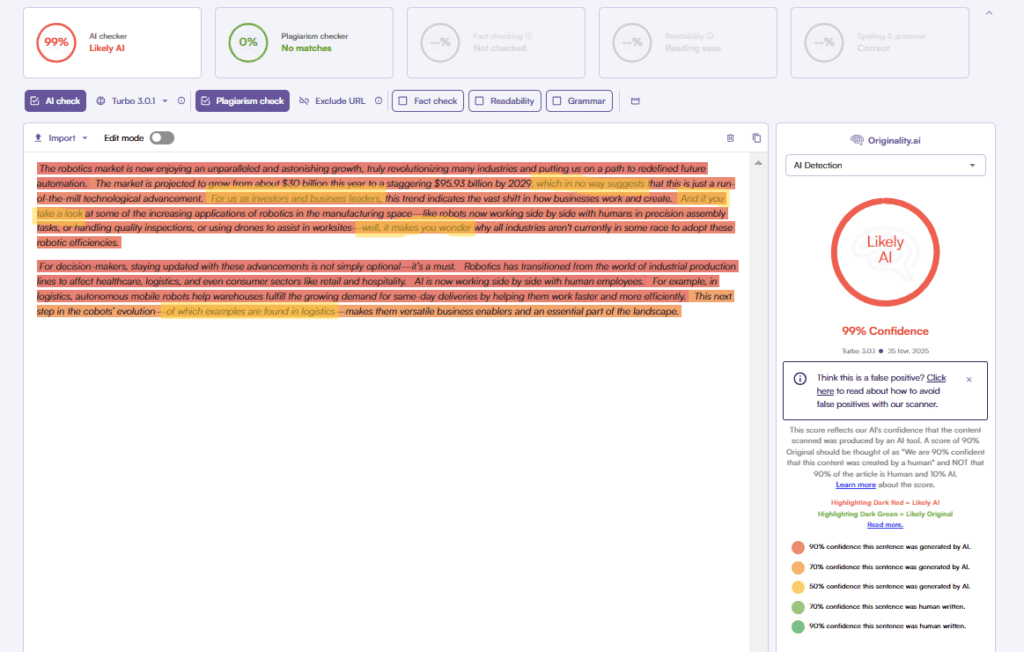
AI detectors’ accuracy vary from one tool to the other. Here we compare the actual accuracy rate of leading AI detectors tools on the market based on the RAID study and other papers (you can also check our ranking of the most reliable AI detectors here).
Originality.ai: Leading Overall + Strong Paraphrase Resistance
Headline Performance
- In the base (non-adversarial) data of RAID, Originality.ai placed first overall with ~85 % accuracy at a 5 % false positive rate threshold.
- On paraphrased (obfuscated) AI content, it achieved 96.7 % accuracy, far above the average of ~59 % among other detectors in the benchmark.
- In adversarial tests (11 attack types), Originality.ai ranked 1st in 9 attacks, and 2nd in another, indicating robustness under many obfuscation strategies.
Strengths & caveats
- Its strength lies in detecting paraphrased AI text, a common evasion technique.
- However, it exhibited weaker robustness against some niche attacks: homoglyph (replacing characters with look-alikes) and zero-width character insertions.
- Its claims of very high accuracy (e.g. “98.2 % accuracy on ChatGPT content”) refer to a narrower subset (ChatGPT outputs specifically), not the full mix of models.
- Because the test is calibrated at a 5 % false positive rate threshold, its performance depends on that cutoff. If you push thresholds (allow more false positives), performance can change.
GPTZero: Conservative, Resilient Under Attack, but Higher Miss Rate
Headline Performance
- GPTZero’s reported accuracy across RAID (across all models) is significantly lower than Originality.ai’s — about 66.5 %, meaning it fails to detect ~33–35 % of AI output in that context. (Note: your data point aligning with 66.5 % is close to publicly discussed evaluations.)
- Against adversarial manipulations, GPTZero’s accuracy drops only slightly — e.g. under homoglyph attacks, it sees very little decline (sometimes ~0.3 % drop), showing resilience to character-level tricks that throw off other detectors.
Strengths & caveats
- It has a very low false positive rate at strict thresholds (i.e. it rarely mislabels clear human text as AI under low-FPR settings). It sometimes outperforms Originality.ai in minimizing false positives.
- Because GPTZero emphasizes perplexity and burstiness, minor edits or obfuscations that don’t change overall predictability may not easily trick it — that is one reason for its relative stability under adversarial attack.
- But its sensitivity is lower: it misses many AI texts, especially in difficult or obfuscated cases. Its overall accuracy is weaker.
- It also struggles with short texts or snippets — when you feed it very brief passages, it often returns “insufficient information” or low-confidence predictions. (This is known from how the tool is used broadly, though not always measured in RAID.)
- Because of its conservative design, GPTZero is safer in contexts where false positives (wrongly accusing human text) are costly (e.g. academia), but at the cost of missing AI content.
Winston: High Accuracy on Major Models, but Narrow Coverage
Headline Performance
- In RAID, Winston is reported to achieve high accuracy on GPT-3.5 / GPT-4 generated content, sometimes reaching ~90 % classification accuracy in those subsets (though not beating Originality.ai overall).
- However, across all AI models tested in RAID, Winston’s overall accuracy is lower (often cited ~71 %), because it performs weakly on open models or less common generation styles.
Strengths & caveats
- It is more optimized or “tuned” to patterns from mainstream models; when confronted with unfamiliar or less-represented models, it generalizes poorly.
- Its ability to catch well-known model output (particularly from GPT-3.5/4) is strong — good for many common use cases.
- It handles edited AI text reasonably well in some scenarios, meaning if you humanize AI content moderately, Winston still flags much of it.
- But Winston has higher false positive rates compared to GPTZero and Originality.ai, especially under looser thresholds (~1 % or more).
Copyleaks
Independent or critical findings
- A Webspero review found Copyleaks’ accuracy around 53.4 % in some mixed or edge-case tests, far lower than claimed. Webspero Solutions
- Some user reports and forum comments suggest Copyleaks may misclassify human text, especially where the writing is polished. Reddit
- In one review, Copyleaks’ accuracy dropped significantly (from 100 % to ~50 %) when passed through a paraphrasing tool like QuillBot. Winston AI
Turnitin
Independent & critical findings
- The Game of Tones study showed that faculty using Turnitin flagged 54.5 % of experimental submissions, underlining that detection is partial, not absolute.
- In the broader GenAI detection study, when detectors faced manipulated (adversarial) text, Turnitin-like tools’ accuracy dropped from ~39.5 % to ~17.4 %.
- Some reports suggest Turnitin’s detector is biased against non-native English speakers, as their simpler sentence patterns more often resemble AI in the detector’s lens.
Turnitin is widely used—especially in academia—and has robust infrastructure behind it. But its performance must be interpreted cautiously, especially in nuanced or adversarial cases. It’s not a substitute for faculty review.

Free Prompts and Ebook to Humanize Your Text
Download Now
Buchert Jean-marc
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.
All Posts