Sommaire
- Comment nous avons classé les modèles de LLM
- ✨ Découvrez Muse – le LLM conçu pour les auteurs de fiction
- 1. Gemini (2.5 Pro)
- 2. Claude (Sonnet 4.5 / Opus 4.1)
- ChatGPT (GPT-5)
- 4. DeepSeek (V3.2-Exp / V3.1 / R1)
- 5. Grok (Grok 4 / Grok 4 Fast)
- 6. Qwen (Qwen 2.5-Max / Qwen 3)
- 7. Mistral (Medium 3 / Large 2.1)
- 8. Muse 1.5 (Sudowrite)
L’IA peut vous éviter de partir de zéro, mais mieux vaut choisir le meilleur grand modèle de langage (LLM).
Nous vous proposons ici le classement des LLM le plus fiable basé sur leur capacité d’écriture.
Nous vous fournissons également une analyse d’exemples sur sept tâches d’écriture, pour un aperçu concret de leur style rédactionnel.
Comment nous avons classé les modèles de LLM
Pour trouver les meilleurs modèles pour l’écriture, nous avons utilisé deux filtres : des données objectives et des tâches d’écriture réelles.
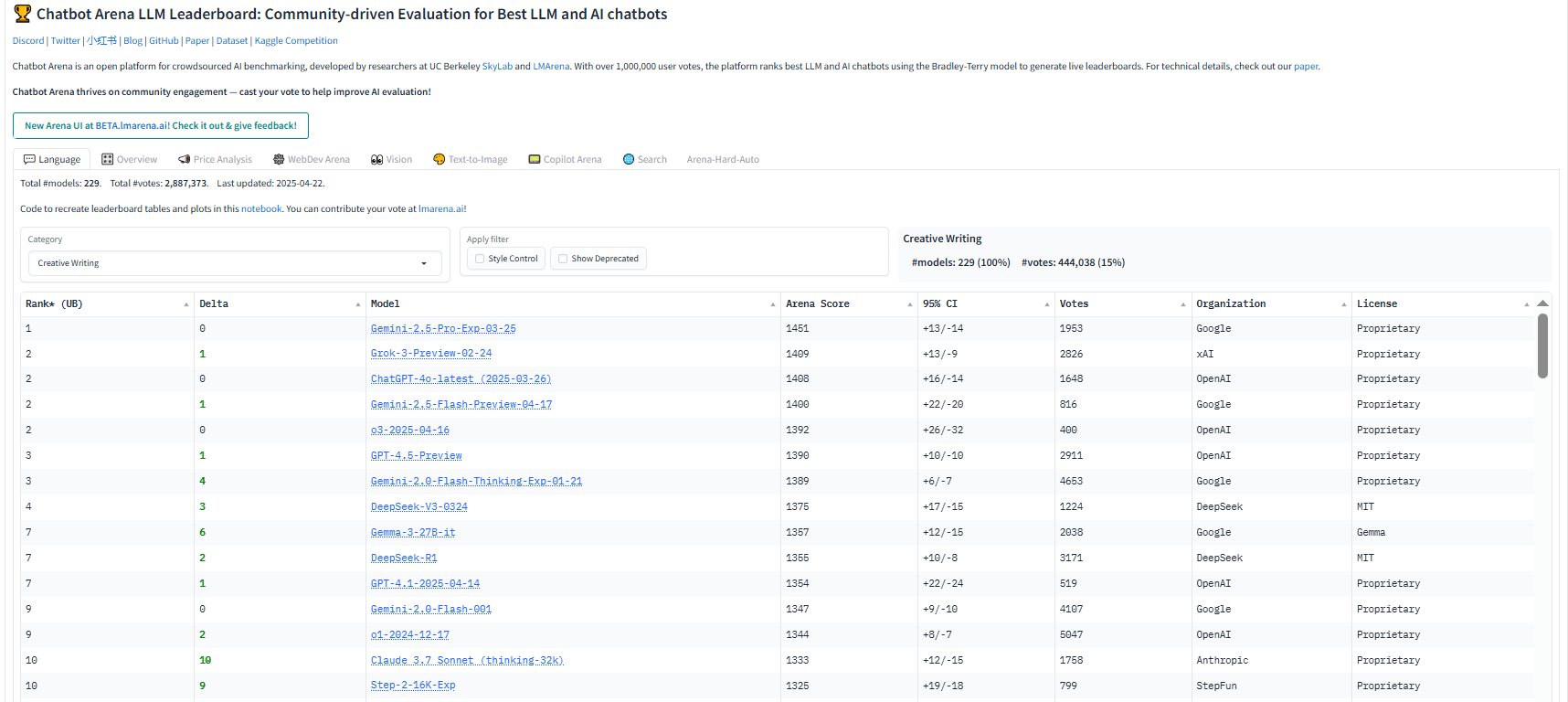
D’abord, nous avons regardé le Chatbot Arena
Chatbot Arena est un classement participatif (crowdsourcé) géré par LMSYS. Il compare les grands modèles de langage (LLM) en fonction des préférences des utilisateurs sur de nombreuses tâches, y compris l’écriture créative.
Nous avons extrait les modèles du classement « Creative Writing » (Écriture Créative). Cela nous a donné un point de départ équitable : quels LLM performent bien lorsque les utilisateurs votent réellement sur la qualité de l’écriture.
Ensuite, nous avons comparé ce classement à leur performance générale sur l’ensemble des tâches.
Si un modèle se classe beaucoup plus haut en écriture qu’en général, c’est un bon signe qu’il a une force particulière (surtout s’il s’agit d’un modèle plus petit).
Ensuite, nous les avons testés nous-mêmes
Nous avons créé sept tâches d’écriture qui reflètent ce que les professionnels comme vous font réellement :
- Une scène de fiction (avec des contraintes créatives strictes)
- Un poème (avec une métrique, des images et une chute)
- Un article de blog SEO (avec placement de mots-clés et structure)
- Un texte de page de destination (landing page) (avec hiérarchie et persuasion)
- Un essai court (avec une thèse claire et des références)
- Une note de recherche scientifique (avec citations et exactitude)

✨ Découvrez Muse – le LLM conçu pour les auteurs de fiction
Si vous avez déjà rêvé qu’une IA puisse écrire avec une vraie émotion, un rythme naturel et une voix humaine, Muse de Sudowrite est faite pour vous. C’est la seule IA formée exclusivement sur de la fiction et de la prose créative de qualité, afin que vos scènes, personnages et dialogues sonnent justes, vivants et inspirants.
Testé et recommandé par notre équipe !
🚀 Essayez Muse gratuitement ici*Aucune configuration ni carte bancaire requise – ouvrez simplement Sudowrite et laissez Muse donner vie à vos idées.*
1. Gemini (2.5 Pro)

Gemini 2.5 Pro est, à mon avis, le LLM le plus complet actuellement disponible pour les rédacteurs. Sa force réside dans la précision, le raisonnement et les résultats détaillés, en particulier pour le SEO, les essais et la rédaction de recherche.
Bien que ses performances en fiction ne soient pas les meilleures absolues, il produit tout de même des récits convaincants avec une cohérence logique et une narration solide.
Avec les ressources massives de Google derrière lui, je pense que la famille Gemini restera probablement un choix solide pour les rédacteurs.
Spécifications techniques
- Fenêtre de contexte (entrée) : 1 048 576 tokens (≈1M). Fenêtre de sortie : jusqu’à 65 535 tokens par réponse (limite par défaut).
- Options d’hébergement : Vertex AI (Model Garden / API), Google AI Studio (API développeur Gemini), et application grand public Gemini via les abonnements Google AI Pro/Ultra (contexte de 1M de tokens dans les niveaux d’application).
- Entrées multimodales natives (utiles pour extraire la structure de PDF, diapositives ou captures d’écran)
Classement (Leaderboard)
Il atteint la première place du classement texte de Chatbot Arena lors de son lancement et sur le classement de l’écriture créative. Sur les classements en direct d’OpenRouter, « Gemini 2.5 Pro » se situe généralement parmi les modèles les plus utilisés et les mieux notés (les classements d’utilisation fluctuent quotidiennement à mesure que de nouvelles variantes apparaissent).
Analyse des exemples
Sur nos tâches, Gemini 2.5 Pro a excellé là où la structure et la clarté comptaient le plus.
- Brief SEO → plan (torréfaction de café) : Gemini a constamment produit des hiérarchies H2/H3 propres, mappé les étapes à l’intention de recherche, et fait ressortir les entités que vous devez réellement couvrir. Il n’a pas déversé de conseils génériques ; il a séquencé les actions (température de charge, indices du premier crack, refroidissement) et signalé les précautions que vous vérifieriez une fois. Cette « sobriété procédurale » a réduit les réécritures par les éditeurs. Cela correspond au positionnement de Google autour du raisonnement et de la planification à long contexte.
- Format long & recherche : Sur les essais argumentatifs et les explications de style littéraire, la force de Gemini était la synthèse. Il a regroupé les affirmations, puis les a soutenues avec des notes de source concises (lorsque requis par notre kit de prompt). Le brouillon arrivait parfois un peu « fade », mais la clarté à la lecture à voix haute était élevée, et la distance d’édition restait faible. C’est un compromis que la plupart des équipes de contenu accepteront.
- Écriture créative : Pour la fiction avec une voix marquée et le copywriting lyrique, Claude l’a devancé en termes d’étincelle et d’imagerie. Gemini a tout de même produit des scènes cohérentes et suivi les contraintes, mais la prose penchait vers la sécurité, sauf si nous fournissions des exemples de style plus forts. Si la voix de votre marque est simple et pratique, cette « sécurité » devient une fonctionnalité. Si vous avez besoin de métaphores luxuriantes ou de sous-entendus dans les dialogues, vous associerez probablement Gemini à une passe de Claude.
Tarification
- Abonnements groupés : Si votre équipe a principalement besoin de rédiger à l’intérieur des applications Google, les plans Google One / AI incluent l’accès à Gemini Advanced (soutenu par 2.5 Pro) pour un forfait fixe par utilisateur. Vous ne microgérerez pas les tokens ; vous travaillerez dans Workspace (Docs, Gmail) et les outils associés.
- API Gemini (AI Studio) : Tarification basée sur les tokens pour 2.5 Pro. À titre indicatif, Google liste des tarifs d’entrée/sortie par million de tokens sur sa page de tarification ; vérifiez cette page avant de budgétiser car les tarifs changent. Si vous prototypez des prompts ou construisez un petit flux de travail, c’est le début le plus simple.
- Vertex AI (GCP) : Déploiement d’entreprise avec des contrôles au niveau de l’organisation, observabilité et gestion des quotas. La tarification est également basée sur les tokens et publiée sur la page Vertex AI de Google Cloud. Si vous avez besoin de gouvernance, de SSO et de VPC-SC, c’est généralement la bonne voie.
2. Claude (Sonnet 4.5 / Opus 4.1)

La famille Claude avec les derniers Sonnet 4.5 et Opus 4.1 sont définitivement les LLM avec le plus d’âme dans leur écriture. Ils excellent particulièrement pour créer des personnages vivants et maintenir une voix narrative cohérente et engageante, souvent plus naturellement que n’importe quel autre modèle.
Ils sont moins précis dans les tâches factuelles et méthodiques que Gemini, mais cela fait partie de leur charme : ils privilégient la créativité et la voix à la rigidité.
Spécifications techniques (Claude Opus 4.1)
- Fenêtre de contexte (entrée) : 200 000 tokens (listing Vertex AI).
- Fenêtre de sortie (réponse unique) : jusqu’à 32 000 tokens (Vertex AI).
- Disponibilité / hébergement : API Anthropic, Google Vertex AI, Amazon Bedrock
- Privé/local : Pas d’auto-hébergement local/hors ligne ; fourni en tant que services gérés via Anthropic/partenaires API. (Voir la documentation des modèles partenaires.)
Spécifications techniques (Claude Sonnet 4.5)
- Fenêtre de contexte (entrée) :
- Standard : 200 000 tokens.
- Long contexte (bêta) : 1 000 000 tokens pour les organisations/niveaux éligibles ; la tarification long contexte s’applique aux requêtes >200K tokens d’entrée.
- Fenêtre de sortie (réponse unique) : jusqu’à 64 000 tokens
- Disponibilité / hébergement : API Anthropic, Vertex AI, Amazon Bedrock ; la disponibilité du contexte 1M peut être limitée par région/niveau.
Classement (Leaderboard)
Opus 4.1 et Sonnet 4.5 se situent également à la première place du classement texte et écriture créative de Chatbot Arena. Ils sont bien placés sur les listes d’utilisation/classement d’OpenRouter et apparaissent en bonne place dans les aperçus de popularité hebdomadaires.
Analyse des exemples (de notre batterie de tests)
Voici comment Claude s’est comporté sur ces tâches précises :
- Écriture créative (nouvelle + sonnet). C’est là que Claude brille. Il a produit le dialogue le plus naturel, des images plus riches et un rythme plus propre dans le test du sonnet shakespearien. Le texte se lisait comme celui d’un humain avec des intentions, pas comme un plan avec des adjectifs. Si la voix de votre marque a besoin d’un élan narratif — scripts, lettres du fondateur, histoires de campagne — commencez par Sonnet 4.5. Lorsque vous avez besoin de plus de profondeur ou de planification en plusieurs étapes, passez à Opus 4.1, puis éditez pour la brièveté.
- Plan SEO + brouillon de section. Claude a bien suivi les instructions et est resté sur le sujet, mais son style par défaut peut devenir un peu lyrique. Pour le SEO, nous avons resserré le brief (phrases interdites, objectifs de longueur de phrase) et demandé une couverture d’entités et des guides pratiques étape par étape. Cela l’a aligné sur ce dont les éditeurs ont besoin. Attendez-vous à moins de réécritures si vous le cantonnez à des actions et des exemples concrets.
- Essai argumentatif + explication de style littéraire. Opus 4.1 a géré la structure à affirmations multiples et les contre-arguments avec le plus de contrôle. Il a regroupé les points logiquement, puis a cousu des transitions qui semblaient humaines. Lorsque notre prompt exigeait des notes de source sous le brouillon, Opus a maintenu une séparation plus nette entre les citations et la prose. Pour les longs articles de recherche, Opus → Sonnet est un passage de relais productif.
- Page de destination + variantes sociales. Le contrôle de la voix est fort, mais Claude peut occasionnellement sur-formater (trop de puces ou une ouverture fleurie). Résolvez cela en fournissant une fiche de style d’un écran (curseurs de ton, ouvertures interdites, modèles de CTA) et un budget de mots par bloc. Vous obtiendrez un texte prêt pour la conversion dès la première passe.
Tarification
- Abonnements Claude (Claude.ai) : Gratuit, Pro (~20 $/mois ou ~17 $/mois en annuel), niveaux Team/Enterprise pour des limites plus élevées et des contrôles d’organisation. Ces plans vous donnent accès via l’interface utilisateur à Sonnet 4.5 et, sur les niveaux supérieurs, à Opus 4.1. Vérifiez la page de tarification pour les dernières limites dans votre région.
- Tarification API (par million de tokens) :
- Sonnet 4.5 : ~3 $ en entrée / 15 $ en sortie. Prend en charge la mise en cache des prompts et les réductions par lot. Bon choix par défaut pour les tâches d’écriture en production.
- Opus 4.1 : ~15 $ en entrée / 75 $ en sortie. À utiliser lorsque vous avez vraiment besoin d’un raisonnement de pointe, puis repassez à Sonnet pour des itérations moins chères. Disponible via l’API Anthropic, Amazon Bedrock et Google Vertex AI.
- Haiku 4.5 (option budget) : ~1 $ / 5 $ et très rapide ; utile pour les brouillons que votre éditeur réécrira lourdement, ou pour les sous-agents.
ChatGPT (GPT-5)
ChatGPT 5 semble être une continuation de la tradition d’OpenAI en matière d’assistance à l’écriture conviviale et intelligente. Ce qui signifie qu’il est toujours inégal en créativité. Il reste excellent pour la non-fiction, la rédaction d’essais et l’optimisation SEO. Son accès aux fonctionnalités de recherche et de récupération lui donne un avantage certain pour produire du contenu riche en données et bien structuré.
Cependant, en fiction et en narration, il est assez inconstant. Certaines histoires montrent des lueurs de génie, tandis que d’autres manquent de cohésion ou d’impact émotionnel. Il abuse parfois des tropes littéraires ou produit un texte chargé de métaphores sans direction narrative claire. L’« étincelle » créative de GPT-4.5, qui avait plus d’originalité et de diversité stylistique, nous manquera certainement.
Spécifications techniques
- Fenêtre de contexte (entrée) : jusqu’à ~272K tokens d’entrée, associés à ~128K tokens de sortie/raisonnement pour une longueur de contexte totale de ~400K sur GPT-5 dans l’API. C’est suffisant pour charger des guides de style, des paragraphes de référence, des briefs, des notes de recherche et un plan de travail sans élagage constant.
- Fenêtre de sortie (réponse unique) : jusqu’à ~128K tokens sur GPT-5. Utile pour les longs brouillons, les briefs structurés et la génération de variantes par lot.
- Privé / local : Il n’y a pas d’auto-hébergement local/hors ligne pour GPT-5. Vous vous connectez via les services gérés d’OpenAI ou les fournisseurs de cloud approuvés. Utilisez les contrôles d’entreprise si vous avez besoin d’une gouvernance plus stricte ; les spécifications et les limites se trouvent dans la documentation officielle du modèle.
Classement (Leaderboard)
Sur Chatbot Arena (LMSYS), les modèles GPT-5 se situent à la 10e place du classement texte et à la 9e pour l’écriture créative (plus bas que GPT-4o et GPT-4.5 !). Sur OpenRouter, les variantes de GPT-5 apparaissent dans les cohortes d’utilisation/notation les plus élevées (les classements fluctuent avec les nouvelles versions et les filtres de catégorie).
Analyse des exemples
Voici comment cela s’est passé :
- Brief SEO → plan → brouillon de section : GPT-5 a constamment produit des hiérarchies H2/H3 claires, mappé les étapes à l’intention de recherche, et fait ressortir les entités pertinentes. Lorsque nous avons activé ChatGPT Search ou Deep Research avant la rédaction, les notes de source étaient plus faciles à vérifier lors de l’édition. Si votre pipeline valorise la vitesse pour un premier brouillon ancré dans les faits, GPT-5 est un choix par défaut solide.
- Essai argumentatif & explication de style littéraire : GPT-5 a bien géré la structure à affirmations multiples, a cousu les transitions proprement et a gardé un ton neutre et professionnel. Il est particulièrement efficace lorsque vous avez besoin d’un texte soutenu par des données ou d’une passe de synthèse avant le polissage humain.
- Écriture créative : C’est là que les résultats ont semblé moins cohérents lors de nos tests. Certaines histoires fonctionnaient ; d’autres s’appuyaient sur des métaphores forcées ou des structures sûres. Si vous avez besoin d’images vives et de dialogues, nous associerions la passe de recherche/structure de GPT-5 à une passe créative dans Claude, puis ramènerions le brouillon à GPT-5 pour la vérification des faits et le resserrement.
- Friction éditoriale : Les brouillons de GPT-5 nécessitaient généralement des modifications mineures pour la structure et la factualité, avec des ajustements occasionnels pour la chaleur de la voix. Si la voix de votre marque est pragmatique et propre, il s’adapte rapidement ; si vous voulez du punch lyrique, fournissez des exemples « few-shot » plus forts (paragraphes de référence) ou effectuez une passe de « lifting » stylistique ailleurs.
Tarification
Choisissez en fonction de la manière dont vous l’utiliserez — UI vs API.
- API (famille GPT-5) : La tarification officielle liste GPT-5 à ~1,25 $ par 1M de tokens d’entrée et ~10 $ par 1M de tokens de sortie (plus des niveaux Mini/Nano à moindre coût). C’est la référence que vous utiliserez pour les charges de travail programmatiques, la mise en cache des prompts et les tâches par lot. Confirmez toujours les tarifs actuels sur la page de tarification avant de budgétiser.
- Abonnements ChatGPT (UI) :
- Gratuit : accès et limites d’utilisation restreints.
- Plus : limites étendues et accès aux outils avancés ; listé à 20 $/mois sur la page de tarification publique (la devise régionale peut varier). Pour la plupart des créateurs solo, c’est le début le plus simple.
- Team / Enterprise : limites plus élevées, contrôles administratifs et gouvernance. Vérifiez la page en direct pour les SKU et la disponibilité régionale ; l’utilisation de l’API est facturée séparément des plans ChatGPT.
4. DeepSeek (V3.2-Exp / V3.1 / R1)
DeepSeek V3.1 est le LLM open source le plus équilibré disponible. Il performe bien dans de nombreux genres – fiction, essais, poésie et SEO – sans être exceptionnel dans un seul domaine.
La nature open source est un avantage énorme : vous pouvez l’affiner (fine-tuner), l’héberger localement et personnaliser vos propres filtres, offrant une indépendance vis-à-vis des écosystèmes d’entreprise. Cela le rend particulièrement attrayant pour les rédacteurs qui apprécient le contrôle, la transparence ou veulent expérimenter avec le réglage des modèles.
Spécifications techniques
- Fenêtre de contexte (entrée) :
- DeepSeek-V3.2-Exp (API) : 128K tokens. Sortie max : 4K par défaut, jusqu’à 8K sur le modèle de chat non-pensant ; le chemin pensant (« reasoner ») prend en charge 32K par défaut / 64K max en sortie.
- DeepSeek-V3.1 (fournisseurs) : couramment exposé avec ~164K de contexte ; les limites exactes varient selon l’hôte.
- Checkpoints à poids ouverts (V3 / R1 / V3.1) : le contexte dépend de la version que vous exécutez et de la pile de service. Partez de la fiche du modèle et des limites de votre framework d’inférence.
- LLM privé/local :
- Oui (poids ouverts) : Vous pouvez auto-héberger les checkpoints V3 / R1 / V3.1 pour un contrôle total des données et l’affinage.
- Options gérées : Les variantes R1 et V3 sont également disponibles sur les principaux clouds et passerelles de modèles si vous voulez la gouvernance sans gérer vous-même les GPU.
- Vitesse / réactivité :
- Sur l’API, la génération est compétitive et bénéficie de la mise en cache des prompts (voir tarification ci-dessous). En local, le débit dépend de votre quantification, de la taille du lot et de la VRAM du GPU. (DeepSeek publie des noyaux optimisés et des dépôts d’infrastructure qui vous aident à réduire la latence.) a
- Modes que vous utiliserez :
- Chat (V3.x) pour l’écriture générale avec utilisation d’outils.
- Reasoner (R1 / V3.x modes « pensants ») pour une planification plus profonde et des tâches en plusieurs étapes. V3.1 ajoute un commutateur hybride entre la pensée et la non-pensée via un modèle de chat — pratique lorsque vous ne voulez « penser » que sur les passages difficiles.
Classement (Leaderboard)
- Sur LMSYS Chatbot Arena, DeepSeek-R1 se situe dans le peloton de tête dans les catégories générales et créatives.
- Sur OpenRouter, DeepSeek V3 / V3.1 sont constamment dans la cohorte à forte utilisation parmi les modèles ouverts.
- En face à face, Qwen 2.5-Max devance parfois DeepSeek sur certains scores de raisonnement et d’arène — mais DeepSeek reste l’option d’écriture ouverte la plus largement adoptée en raison de son profil qualité-coût.
Analyse des exemples (de notre batterie de tests)
Vous voulez un modèle qui est « bon à tout faire » et facile à contrôler. C’est l’ambiance DeepSeek.
- Brief SEO → plan → brouillon de section : DeepSeek a produit une structure solide et progressive et ne s’est pas égaré. Il avait besoin d’un léger coaching vocal pour éviter les formulations génériques, mais la couverture des entités et le séquençage des tâches étaient fiables. Si vous standardisez votre kit de prompt (curseurs de voix, phrases interdites), il rédige un texte propre avec une faible distance d’édition.
- Essai argumentatif & explication de style littéraire : Avec la pensée activée, DeepSeek a regroupé les affirmations de manière sensée et a gardé les transitions serrées. Les notes de source étaient utilisables ; vous effectuerez toujours une passe de vérification humaine, mais l’échafaudage tenait le coup.
- Écriture créative (nouvelle + sonnet) : R1/V3.1 a livré une fiction meilleure que prévu pour un modèle ouvert. Le sonnet tenait la métrique et la rime de manière convaincante ; la nouvelle était cohérente et parfois inventive, bien qu’un peu conservatrice dans l’imagerie par rapport à Claude. Si vous voulez plus de couleur, ajoutez des paragraphes de style « few-shot » plus forts.
- Page de destination + variantes sociales : Bonne clarté ; parfois chargé en listes. Nous avons freiné le sur-formatage et la dérive des emojis avec une fiche de style d’un écran et des budgets de mots plus stricts.
Tarification
- Tarification API officielle (V3.2-Exp) :
- Entrée : 0,28 $ par 1M de tokens (0,028 $ par 1M avec cache hit)
- Sortie : 0,42 $ par 1M de tokens
- Contexte : 128K ; limites de sortie notées ci-dessus (8K chat ; 64K reasoner).
Ces tarifs sont listés sur la propre page de tarification de DeepSeek.
- Hôtes tiers : Certains fournisseurs annoncent ~164K de contexte pour V3.1 et des prix tout aussi bas (parfois même des tarifs promotionnels inférieurs). Validez toujours le contexte et les limites par hôte avant de budgétiser.
- Poids ouverts (auto-hébergé) : Les fichiers du modèle sont gratuits à télécharger ; vos coûts sont calcul + opérations. Si vous possédez déjà des GPU (ou louez des instances spot), cela peut battre la tarification API pour un débit élevé — au détriment de la surcharge MLOps. Commencez par les dépôts et noyaux officiels.
5. Grok (Grok 4 / Grok 4 Fast)

Grok 4 est le modèle le plus provocateur et doté de personnalité de cette liste. Il est moins censuré et plus audacieux dans le ton. Le modèle démontre également un raisonnement solide et une intégration factuelle, en particulier dans les essais et les opinions.
Cependant, la créativité de Grok peut sembler imprévisible : parfois brillante, parfois brute. La même « liberté » qui le rend intéressant le rend aussi moins cohérent. Il est idéal pour les rédacteurs qui veulent explorer des tons controversés, non conventionnels ou très individualistes.
Spécifications techniques
- Fenêtre de contexte (entrée) : Grok 4 prend en charge ~256K tokens. Grok 4 Fast étend cela à ~2M tokens (deux variantes : raisonnement et non-raisonnement). Si vous complétez les briefs avec de longues notes de recherche ou des transcriptions, cette marge de manœuvre est pratique.
- Fenêtre de sortie : Correspond aux limites ci-dessus sur demande ; les longues réponses sont diffusées en streaming. (Les tokens de raisonnement — lorsqu’ils sont exposés via des passerelles — comptent comme sortie.)
- Privé/local : Pas de version locale/hors ligne. Vous accédez à Grok via l’API de xAI ou les passerelles prises en charge ; la recherche X (Twitter) en temps réel est native des applications grand public de Grok et peut être activée/désactivée dans le produit.
- Vitesse : Grok 4 Fast est le choix pour le débit (deux SKU : raisonnement et non-raisonnement) avec le contexte 2M. Utilisez Fast lorsque vous avez besoin d’itérations rapides ou que vous résumez de grands corpus.
- Positionnement des données / Ambiance : Grok penche vers des réponses « plus piquantes » et des flux en temps réel de X, ce qui peut donner des angles nouveaux — et nécessite vos garde-fous éditoriaux.
Classement (Leaderboard)
Grok 4 est listé comme le 11e au classement texte de Chatbot Arena et 8e au classement de l’écriture créative.
Analyse des exemples (de notre batterie de tests)
Vous avez demandé comment il écrit, pas seulement la taille de son contexte.
- Écriture créative : Grok était l’exception de manière utile. Il a pris des risques plus audacieux — des décors ou des références surprenants — et a parfois cherché des angles à contre-courant dans le thème et le personnage. Selon vos propres termes : « ambiance edgy ». Cela convient aux lettres de fondateurs, aux publicités narratives ou aux essais où vous voulez un point de vue. Vous ferez toujours de la relecture pour la sécurité de la marque, mais la ligne de base « voicey » (avec une voix marquée) est précieuse. (Cela correspond à la façon dont xAI commercialise le ton de Grok et son flux de culture en temps réel.)
- Essais / Opinions : Grok avait tendance à puiser dans des références alternatives ou historiques que d’autres modèles n’utilisaient pas (par exemple, des économistes ou des débats plus anciens). Cela crée de la texture. Votre éditeur devrait vérifier les citations et les attributions avant de publier — les extractions en temps réel peuvent être désordonnées.
- Plan SEO → brouillon de section : « Correct, pas le meilleur » est juste. Grok a suivi le brief et a couvert les entités, mais il préférait parfois un cadrage provocateur à un guide pratique étape par étape. Si votre marque est pratique et minimaliste, gardez votre fiche de style serrée (métaphores interdites, objectifs de longueur de phrase, nombre exact de H2/H3) et il se comportera.
- Schéma factuel & sourcing : Lorsque la recherche en temps réel de Grok est activée, vous obtiendrez des mentions plus fraîches — plus la source non faisant autorité occasionnelle. Nous contournons cela avec notre règle de notes-de-source-sous-la-ligne et une passe de vérification humaine avant que quoi que ce soit ne soit expédié.
Tarification
- API xAI (prix catalogue) :
- Grok 4 : listé à 3,00 $ / 1M de tokens d’entrée et 15,00 $ / 1M de tokens de sortie ; contexte 256K. La tarification augmente pour les très grosses requêtes.
- Grok 4 Fast (raisonnement & non-raisonnement) : contexte 2M avec des tarifs bas affichés entre 0,20 $–0,50 $ par million de tokens (dépendant du SKU). Conçu pour une utilisation intensive en débit.
- Accès grand public (applications/abonnements) : Grok 4 est disponible dans les niveaux sur X (Premium/Premium+, SuperGrok, SuperGrok Heavy), avec les modèles phares débloqués aux niveaux supérieurs ; le site de xAI et les mises à jour notent la disponibilité et le positionnement. Utilisez ces plans si votre équipe écrit principalement dans l’application Grok.
6. Qwen (Qwen 2.5-Max / Qwen 3)

Qwen 2.3 est un concurrent sérieux dans la catégorie open source par rapport à DeepSeek.
Je le trouve particulièrement bon pour les essais, les revues de littérature et la non-fiction structurée. Les résultats du modèle sont souvent détaillés et bien organisés, bien que parfois trop formatés. En écriture créative, il performe décemment mais n’a pas l’instinct narratif de Claude.
Spécifications techniques
- Fenêtre de contexte (entrée). Il y a deux pistes à connaître :
- Versions à poids ouverts. Qwen a livré des modèles ouverts avec jusqu’à 1M de tokens de contexte (par exemple, Qwen2.5-7B/14B-Instruct-1M), vous pouvez donc auto-héberger la rédaction long contexte sans être verrouillé à un fournisseur.
- SKU hébergés/API. Les spécifications varient selon le fournisseur. Sur OpenRouter, Qwen-Max (basé sur Qwen 2.5) liste ~32K de contexte. Sur le Model Studio d’Alibaba Cloud, la famille Qwen Plus / 2.5 offre une tarification échelonnée jusqu’à 1M de tokens d’entrée par requête (avec des modes « pensant » vs « non-pensant » séparés). Vérifiez quel SKU vous appelez réellement avant de coller un méga-document.
- Fenêtre de sortie. Les limites de sortie suivent le SKU (et le mode « pensant »/raisonnement). Alibaba documente des prix/niveaux séparés pour les générations non-pensantes vs pensantes à mesure que le contexte augmente (≤128K, ≤256K, jusqu’à 1M).
- Privé / local. Qwen maintient des dépôts officiels à poids ouverts (Hugging Face, GitHub). Vous pouvez auto-héberger et affiner, ou exécuter en mode géré via Alibaba Cloud. C’est idéal si vous voulez un positionnement des données de type UE ou un contrôle sur site.
- Vitesse / modes. Attendez-vous à des SKU plus rapides et plus légers pour la rédaction et des modes de raisonnement (« pensants ») pour une planification plus profonde. Comme avec d’autres modèles MoE, le débit dépend de l’hôte et de vos choix de quantification/lot lors de l’auto-hébergement.
Classement (Leaderboard)
Les variantes de Qwen apparaissent toujours juste derrière DeepSeek dans le classement texte et écriture créative de Chatbot Arena.
Analyse des exemples
Voici la lecture pratique :
- Essais & non-fiction à forte composante de recherche (solide). Les modes de raisonnement de Qwen ont livré un regroupement clair des affirmations, des exemples à l’appui, et des transitions ordonnées. Sur les explications de style littéraire, il a empilé les citations proprement lorsque nous avons imposé « notes de source sous le brouillon ». Si votre calendrier penche vers les livres blancs, les explications et le « thought leadership », Qwen a tenu la comparaison avec DeepSeek.
- Brief SEO → plan → section. Sorti de la boîte, Qwen a bien suivi la structure et la couverture des entités. Il a parfois sur-formaté ou penché vers les emojis dans le texte de la page de destination. Nous avons corrigé cela avec une fiche de style d’un écran : emojis interdits, budgets de mots, nombre exact de H2/H3, et « pas de murs de puces ». Avec ces garde-fous, les brouillons étaient propres et rapides à éditer — très utilisables pour la production.
- Écriture créative. Compétent et occasionnellement inventif, mais pas aussi lyrique que Claude et pas aussi naturellement « voicey » que Grok. Les scènes de la nouvelle étaient cohérentes et conformes au brief ; le sonnet shakespearien était solide sur la rime/métrique. Si vous voulez plus de couleur, ajoutez des paragraphes de style « few-shot » plus forts ou routez un coup de poing final à un modèle axé sur la créativité.
Tarification
Le budget dépend de l’endroit où vous l’exécutez.
- Alibaba Cloud Model Studio (API). La famille Qwen Plus/2.5 utilise une tarification échelonnée par bande de contexte avec des tarifs séparés pour les générations non-pensantes et pensantes. Exemples de bandes documentées aujourd’hui : ≤128K, ≤256K, et (256K, 1M] entrées — avec des tarifs par million de tokens augmentant à chaque niveau. C’est votre référence si vous déployez à l’intérieur d’Alibaba Cloud.
- OpenRouter (hébergé). Qwen-Max est listé autour de 1,60 $/M en entrée et 6,40 $/M en sortie avec ~32K de contexte (les fournisseurs peuvent varier). Bon pour des pilotes rapides et des tests de prompt chez différents fournisseurs.
- Auto-hébergé (poids ouverts). Les fichiers du modèle sont gratuits ; vous payez calcul + opérations. Si vous avez déjà des GPU (ou louez des instances spot), auto-héberger les versions ouvertes 1M-contexte peut être rentable à volume — à condition que vous soyez prêt pour le travail MLOps.
7. Mistral (Medium 3 / Large 2.1)
Mistral est le LLM open source le plus fiable d’Europe.
Il est idéal pour les rédacteurs et les organisations qui préfèrent les normes européennes de traitement des données ou veulent garder le contenu en local. En termes d’écriture, il est dans la moyenne : structuré, prévisible et clair, bien que parfois rigide ou stéréotypé.
La fiction de Mistral peut sembler un peu mécanique, avec moins de nuances émotionnelles que Claude ou DeepSeek. Cependant, son écriture de non-fiction et SEO est fiable, cohérente et bien structurée.
La force principale de Mistral réside dans son ouverture — vous pouvez l’affiner, l’héberger en privé et l’adapter à votre flux de travail exact.
Spécifications techniques
- Mistral Medium 3 : ~128k tokens (multimodal ; texte+vision). C’est le fleuron polyvalent actuel que Mistral pousse pour une utilisation en entreprise en 2025.
- Mistral Large 2.1 : également documenté à ~128k sur les listes de partenaires. Traitez Large comme l’alternative « plus lourde » si vous vous êtes standardisé dessus.
- Codestral 2 (axé code) : 32k de contexte sur Vertex AI (GA 2025-10-16). Utilisez-le lors de la rédaction ou de la refactorisation de code dans les documents/tutoriels.
- Fenêtre de sortie : Longues générations en streaming ; pratiquement la longueur d’un chapitre. En production, vous limiterez toujours par section pour le contrôle éditorial. (Les fournisseurs présentent la sortie comme faisant partie du même budget de 128k.)
- Options privées/locales : Mistral continue de publier des poids ouverts avec des guides d’auto-déploiement (vLLM, etc.). Si vous avez besoin d’un positionnement UE, d’une isolation VPC ou de tests sur site, c’est une raison clé pour laquelle les équipes choisissent Mistral.
- Où vous l’exécuterez : Directement via La Plateforme / Le Chat, ou via des clouds/marketplaces partenaires (Vertex, Azure).
Classement (Leaderboard)
Sur les classements de préférence publics, les modèles Mistral se situent généralement dans la moyenne — souvent en dehors du top 10 mais bien dans le top 20 pour les arènes textuelles uniquement, le placement changeant avec les nouvelles versions. Les pages produits d’OpenRouter montrent des aperçus d’utilisation/popularité pour Mistral Medium 3 chez différents hôtes.
Analyse des exemples (de notre batterie de tests)
Vous voulez savoir où Mistral vous aide réellement à livrer :
- Plan SEO → brouillon de section (assez solide). Mistral a livré des H2/H3 clairs, une bonne couverture d’entités sur la page, et une structure étape par étape sensée. Ce n’est pas le rédacteur le plus inventif, mais il s’est rarement égaré. Pour le SEO en production, c’est bien : les éditeurs se soucient plus de la spécificité et du suivi des instructions que de la prose fleurie.
- Essai argumentatif / explications (structure solide, ton sobre). Sur les essais et les explications de style littéraire, Mistral a regroupé les affirmations proprement et a gardé les transitions nettes. Comparé aux fleurons du « raisonnement », il peut sembler un peu procédural — mais si la voix de votre marque est simple et pratique, cela fonctionne bien.
- Écriture créative (juste correct). Votre avis correspond au nôtre : utilisable, pas le plus subtil. Le dialogue et l’imagerie sont compétents, mais la voix penche vers la sécurité et occasionnellement le sur-formatage (tendance aux listes). Si vous avez besoin d’un élan lyrique, faites une seconde passe dans Claude et ramenez le brouillon à Mistral pour le resserrage + la vérification des faits.
- Page de destination + variantes sociales (surveillez le formatage). Mistral abuse parfois des puces ou, selon le SKU/prompt, parsème des emojis. Résolvez cela avec une fiche de style d’un écran : emojis interdits, nombre maximum de puces, objectifs de longueur de phrase, et quotas H2/H3 fixes. Une fois bridé, il livre un texte propre avec une faible distance d’édition.
Tarification
La tarification de Mistral est simple et prévisible — et compétitive pour un modèle « premium ».
- Mistral Large 24.11 (API). Les listes publiques affichent 2,00 $ par 1M de tokens d’entrée et 6,00 $ par 1M de tokens de sortie, avec ~128K de contexte. C’est votre choix pour les articles longs et structurés et les flux de travail éditoriaux.
- Mixtral 8x22B Instruct (MoE). Souvent le choix valeur : couramment listé autour de 0,90 $/M pour l’entrée et la sortie sur certains hôtes, avec des variations selon le fournisseur. Si vous êtes sensible aux coûts et pouvez accepter une petite baisse de qualité par rapport à Large, ce SKU est attrayant pour le SEO en vrac.
- Pages de tarification officielles. La propre tarification et l’aperçu des modèles de Mistral documentent les plans, les SKU et les niveaux Le Chat. Confirmez toujours les tarifs en direct avant de vous engager sur un budget.
- Le Chat (application). Si vos rédacteurs préfèrent une application aux API, Le Chat propose des niveaux gratuits et payants avec des options d’entreprise ; la facturation de l’utilisation de l’API est distincte des abonnements à l’application. Bon pour les équipes qui veulent rédiger dans une interface utilisateur gérée avec un positionnement UE.
8. Muse 1.5 (Sudowrite)
Muse est le seul LLM conçu spécifiquement pour la fiction. Le pipeline « d’ingénierie narrative » de Sudowrite l’aide à planifier, réviser et s’en tenir au brief, de sorte que les chapitres ne divaguent pas autant qu’ils le peuvent avec Claude ou GPT lorsque vous poussez pour la longueur. Il est également intentionnellement moins filtré sur les thèmes adultes et la violence, ce qui est important si vous écrivez des genres plus sombres.
Points faibles : il est exclusif à Sudowrite, donc vous n’avez pas la liberté de routage ouvert ; la cohérence interne peut encore être en retard par rapport à Claude sur des traditions (lore) très complexes ; et pour le travail factuel ou SEO pur, Gemini/ChatGPT restent plus forts.
ESSAYEZ LE LLM MUSE GRATUITEMENT ICI
Spécifications techniques
- Fenêtre de contexte (entrée). Sudowrite ne publie pas de nombre de tokens pour Muse. Pratiquement, vous travaillez au niveau de la scène/chapitre à l’intérieur des outils Draft/Write de Sudowrite, avec une sortie en streaming et des outils (Expand, Rewrite) qui gardent le contexte actif concentré. Si vous avez besoin de limites de tokens strictes, Muse n’est pas commercialisé de cette façon ; il est positionné comme un flux de travail de fiction plutôt que comme un modèle API général.
- Fenêtre de sortie. Les générations sont diffusées en streaming et peuvent être étendues (« continuer ») à l’intérieur de Draft/Write. Muse 1.5 annonce spécifiquement des scènes plus longues et un suivi des instructions plus strict par rapport aux versions précédentes.
- Privé/local. Pas d’auto-hébergement. Muse est exclusif à Sudowrite (application web). Sudowrite déclare que votre travail n’est pas utilisé pour entraîner Muse et met l’accent sur un ensemble de données de fiction éthiquement consenti. Si votre priorité est une promesse de données respectueuse des auteurs à l’intérieur d’un outil hébergé, c’est l’attrait.
- Filtres et ton. Muse est commercialisé comme « le plus non filtré » sur Sudowrite (peut gérer les thèmes adultes/violence) et comme activement dé-cliché pendant l’entraînement. Bon à savoir si vous écrivez des genres plus sombres — et tout aussi important si vous devez garder les brouillons « brand-safe » (sûrs pour la marque).
Classement (Leaderboard)
Muse est un modèle privé vertical — visant la fiction — donc vous ne le trouverez pas au sommet des classements généraux de LLM.
Analyse des exemples
Vous avez demandé comment il écrit — pas seulement comment il est commercialisé. Nous avons exécuté les mêmes tâches que nous donnons aux autres modèles, mais nous avons jugé Muse principalement sur des tâches axées sur la fiction, puis vérifié son utilité pour le texte marketing.
- Scène de nouvelle (dialogue + détails sensoriels). Muse a produit le dialogue le plus humain de notre ensemble. Les temps morts (beats) tombaient naturellement, le jeu de scène (stage business) semblait intentionnel, et la prose évitait le « vernis IA » évident (métaphores bateau, cadence répétitive). Sa voix par défaut était vive sans excès de « purple prose », et il répondait bien aux exemples de style (quelques paragraphes de votre voix). Cela correspond à l’affirmation de Sudowrite selon laquelle Muse est conçu pour réduire les clichés.
- Sonnet shakespearien. Étonnamment discipliné. La rime et la métrique tenaient tout en portant encore des images — comparable aux meilleurs modèles fermés de notre test. Le raffinement « scènes plus longues » de Muse 1.5 s’est également manifesté ici par un contrôle plus stable des strophes sur un poème complet.
- Brouillons d’essais/argumentations. Fait le travail, mais ce n’est pas le point fort de Muse. Il peut structurer un argument et garder un ton cohérent, mais il ne surpassera pas en raisonnement les généralistes de pointe. Si votre calendrier est rempli d’essais et de « thought leadership », vous préférerez toujours Gemini/GPT/Claude pour l’échafaudage, puis apporterez des passages dans Sudowrite pour le travail sur la voix.
- SEO/Page de destination. Muse générera des paragraphes propres et des lignes percutantes, mais il n’est pas conçu pour la couverture d’entités, le mappage SERP, ou les échafaudages H2/H3 rigides par défaut. Si vous êtes un romancier-marketeur, c’est une excellente « passe vocale » après qu’un modèle procédural ait défini la structure.
- Contrôle & sécurité. Parce que Muse est « moins filtré », nous recommandons une simple fiche de sécurité de marque (thèmes/phrases interdits, curseurs de ton) lorsque vous l’utilisez pour du texte destiné au public. Pour la fiction, cette ouverture est une fonctionnalité ; pour le marketing, fixez des rails.
Tarification
Sudowrite vend l’accès à Muse via des abonnements basés sur des crédits (application navigateur). Niveaux (facturation mensuelle indiquée sur la page de tarification en direct) :
- Hobby & Student — 10 $/mois pour ~225 000 crédits/mois.
- Professional — 22 $/mois (la page affiche 450 000 et 1 000 000 crédits ; traitez 1 000 000/mois comme le montant principal inclus actuel sur la page).
- Max — 44 $/mois pour ~2 000 000 crédits/mois avec report sur 12 mois des crédits non utilisés.
Tous les niveaux incluent l’application Sudowrite ; Muse est sélectionnable comme modèle par défaut dans Draft/Write. Confirmez toujours les inclusions actuelles et les réductions annuelles sur la page de tarification avant de budgétiser.

Prompts gratuits et Ebook pour humaniser votre texte
Télécharger Maintenant
Buchert Jean-marc
Expert confirmé en processus de contenu IA. Par ses méthodes, il a aidé ses clients à générer du contenu de qualité qui correspond à leurs exigences éditoriales et aux attentes de leur public.
Tous les Articles