Yes, and it is called hallucination. And it can quietly wreck your trust for LLMs.
This guide is your field manual to stop that from happening. You’ll get a clear, practical understanding of what hallucinations and how to prevent it.
What are ChatGPT hallucinations?
The definition of ChatGPT hallucination according to expert:a fluent statement that contradicts the provided source (intrinsic) or introduces unverifiable information not supported by the source (extrinsic), including fabricated citations or misattributions.
In simple terms ? When ChatGPT “hallucinates,” it writes something fluent and confident that isn’t backed by evidence. Sometimes it invents facts. Sometimes it misreads a source. Sometimes it fabricates a citation or URL.
The key signal is this: the text sounds right, but you can’t verify it. In research, this is called a “reliability failure in natural-language generation” (NLG).
You’ll see two primary types used in the literature :
Intrinsic hallucinations contradict the given source or context. Example: you paste a press release and the model rewrites a quote that never appeared.
Extrinsic hallucinations add content you can’t confirm from the source at hand—new numbers, names, or claims. Some extrinsic additions can even be true in the real world, but they’re still risky if your brief requires faithfulness to a specific document.
More broadly :
Factual hallucination: any statement that can’t be supported by your source set (or is flat-out wrong).
Attribution hallucination: a real fact paired with the wrong source, person, or brand.
Citation hallucination: nonexistent papers, fabricated URLs, or quotes with no traceable origin.
Logical hallucination: a fluent conclusion that doesn’t follow from the premises.
Academic work also sometimes notes “hallucinated but factual” additions—details that are true in general but not grounded in your provided text. That might read helpful, yet it still breaks faithfulness to the brief (e.g., a summary of a report should not introduce outside trivia).
Why does ChatGPT hallucinate?
Short answer: because it’s a next-token predictor, not a truth engine. It learns patterns from text and continues them. When the pattern points the wrong way—or your prompt leaves gaps—it will still produce something fluent. That’s the core failure mode researchers call hallucination.
There are a few root causes you should understand.
1) The training objective doesn’t reward truth. Language models are optimized to predict the next word, not to verify facts. With no built-in link to a database or sources, they can generate confident but unsupported claims—especially on niche or time-sensitive topics. Surveys of hallucination in NLG and LLMs make this point explicit.
2) Missing or stale knowledge. Parametric memory (what the model “remembers”) can be wrong, incomplete, or outdated. When the answer isn’t in that memory, the model guesses. Retrieval-augmented generation (RAG) was proposed to fix this by pulling evidence from external documents before writing; it consistently improves factuality on knowledge-intensive tasks. If you don’t ground the model, you invite invention.
3) The task pushes it off-distribution. When your input looks unlike what the model saw during training—specialized jargon, internal data, rare entities—the model extrapolates. That’s where “intrinsic” (contradicting the source) and “extrinsic” (adding unverifiable info) hallucinations appear most often, a split documented in summarization research and now used widely.
4) Long context is hard to use reliably. Even models that accept long prompts struggle to pick the right facts from the middle of a large context window. The “lost-in-the-middle” effect shows accuracy drops when evidence isn’t near the edges of the prompt. If the model can’t retrieve the key detail, it may fill the gap.
5) Human-feedback tuning can bias toward agreeableness. RLHF makes assistants more helpful and polite—but it can also teach sycophancy: agreeing with your stated belief over giving a correct answer. Studies show state-of-the-art assistants sometimes prefer a convincing but wrong response if that’s what humans upvoted. In practice, this turns soft prompts into confident nonsense.
6) Decoding and pressure to answer. Generation methods (e.g., sampling) favor fluency. When the model is uncertain, it rarely says “I don’t know” unless you allow that behavior. Classic work in abstractive summarization also showed that likelihood training plus approximate decoding can yield unfaithful content that looks great but isn’t grounded.
7) Imitation of human falsehoods. Models learn from human text, which includes myths and misconceptions. On the TruthfulQA benchmark, models often mimic common false answers unless explicitly guided otherwise. If your brief invites “general knowledge,” expect this failure mode.
Do the latest ChatGPT models still hallucinate?
Short answer: yes. Newer models hallucinate less in many cases, but not zero—and on some tests, more. You should plan for progress, not perfection.
OpenAI’s April 2025 system card for its reasoning models makes this plain. On SimpleQA (fact-seeking questions), o3 showed a 0.51 hallucination rate and o4-mini 0.79, compared with 0.44 for o1. On PersonQA (facts about real people), o3 hallucinated 33% of the time and o4-mini 48%, versus 16% for o1. OpenAI notes o3 “makes more claims overall,” which drives both more correct and more incorrect statements. The takeaway for you: newer ≠ uniformly safer; behavior depends on the task and the model.
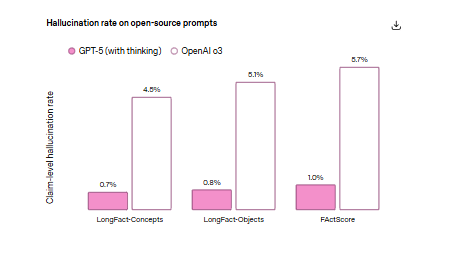
What about GPT-5? It’s clearly better on factuality, especially in “thinking” mode, but it still isn’t perfect. OpenAI reports that, on real-world traffic with web search enabled, GPT-5 responses are ~45% less likely to contain a factual error than GPT-4o.
With thinking enabled, GPT-5 is ~80% less likely to contain a factual error than o3, and “about six times” fewer hallucinations on open-ended factuality tests like LongFact and FActScore. Good news—but “less likely” isn’t “never.” You still need checks for claims, numbers, and citations.
Independent and academic signals back this caution. TruthfulQA—a benchmark designed to catch answers that echo common misconceptions—remains challenging for frontier models. Scores improve across vintages, but no model is immune to producing confident, wrong answers when a prompt taps folk beliefs or ambiguous facts.
Long-form copy is even trickier. Studies like LongFact and FActScore show that as outputs get longer, you accrue many small, checkable claims; a few unsupported atoms can compromise the whole piece. These papers formalize what you see in production: a great-sounding paragraph with one invented stat, one misattributed quote, and a dead link. That’s still a hallucination problem, just spread thin across sentences.
So, how should you set expectations with your team?
Assume non-zero hallucination risk on every model and release. Version bumps help, but they don’t eliminate risk. Use them to reduce edit time, not to skip editorial review. (The o3/o4-mini results are a useful slide for stakeholders who think “new = solved.”)
Treat improvements like GPT-5’s as an opportunity to tighten your workflow, not to relax it. Keep grounding, source citation, and refusal paths in place; you’ll just spend fewer minutes correcting.
Match the model to the job. If a task is people-focused or brand-sensitive, pick the model + workflow with the lowest observed hallucination profile for that task, and enforce source requirements.
Prompts to prevent ChatGPT hallucinations
Below are ready-to-paste prompts to reduce the likelihood of ChatGPT hallucinations. It’s not bullet proof, but it can help keep ChatGPT grounded.
Grounded answer (mini-RAG) You force the model to use only the sources you provide. The prompt:
Use only the sources below to answer. Quote exact lines and add inline citations like (Doc A, lines 12–18). If the sources don’t contain the answer, say: “I don’t have enough evidence.” Sources: [paste excerpts or links] Task: [your question]
Chain-of-Verification (CoVe) pass A built-in self-fact-check before the final draft. The prompt:
Step 1 — Draft the answer. Step 2 — List 3–5 verification questions that would prove or disprove key claims. Step 3 — Answer those questions using the provided sources only. Step 4 — Rewrite the final answer to include only claims supported by Step 3. Mark anything unsupported as “uncertain.”
Atomic facts checklist Break the draft into small, checkable statements. The prompt:
List every atomic fact in your answer as bullets. After each, attach a supporting quote + citation from the provided sources, or mark no support. Remove or revise any fact that lacks support.
Strict citation & abstention A hard rule: no source, no statement. The prompt:
Cite a source for every statistic, quote, or named entity. If a claim has no source, do not include it. If confidence <80% or sources conflict, answer: “I don’t know—need evidence.”
Evidence-first layout (beats “lost-in-the-middle”) Put key evidence at the top and point the model to it. The prompt:
Read the Evidence section first and use only those passages. Quote line numbers. Do not use information beyond this evidence. Evidence: [paste the 3–7 most important excerpts]
Post-generation self-check Force the model to rate the support for each sentence. The prompt:
Re-read your answer. For each sentence, rate factual support as Supported / Partially supported / No support using the provided sources only. Output a table and revise any “No support” items.
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.