Table of Contents
The latest academic evaluation & benchmark of AI detectors often reveal that simple obfuscation techniques can significantly degrade their performance.
Yet, among the solutions evaluated, some tools differentiate themselves in their accuracy, false positive rate and resistance against adversarial attacks.
In this article, we rank and compare the best AI detectors (free and paid) based on these objective studies.
| Rank | Tool | Best For | Key Differentiators | Accuracy & Robustness | Pricing |
| 1 | Pangram Labs | Enterprise & Experts (Highest Accuracy) | Uses “Active Learning” to catch humanized text. Handles adversarial attacks better than any other tool. | 99.3% Accuracy (RAID). The only tool to match human experts in the UMD study. | Subscription: Free trial (5/day); Individual $20/mo. |
| 2 | Originality.ai | Content Marketing & SEO | Turbo 3.0 model specifically targets paraphrased content (Quillbot). Detects “spinning” effectively. | High. Excellent against paraphrasing (96.7%) but vulnerable to Homoglyph attacks. | Credit/Sub: $30 PAYG or $14.95/mo. |
| 3 | GPTZero | Education & Students (Safety First) | Focuses on Perplexity & Burstiness. Prioritizes low false positives (<1%) to protect students. | Moderate. Robust against Homoglyphs but vulnerable to paraphrasing tools. | Freemium: Free limited use; Paid starts at $10/mo. |
| 4 | Copyleaks | LMS Integrations | Multilingual detection (30+ languages) and sentence-level analysis. | Mixed. High accuracy on raw GPT text, but accuracy drops (~50%) against paraphrasing. | Page-based: Starts at $9.99/mo for 100 pages. |
| 5 | Turnitin | Academic Institutions | Massive student paper database. Uses a high suppression threshold (<20%) to avoid false alarms. | Conservative. High false positive rate for ESL students; vulnerable to “spinning.” | Institutional Only: No individual plans. |
| 6 | Winston AI | Docs with Handwriting | Built-in OCR allows scanning of handwritten or printed physical essays. | Basic. Good for standard GPT-4 text (90%) but fails against open-source models (Llama/Mistral). | Credit-based: Free trial; Starts at $12/mo. |
Evaluation Criteria
Before talking about the ranking, I’d like to disclose how I’ve evaluated these AI detectors.
My evaluation has been based mostly on the most reliable & recent studies at this time :
1.1 The RAID Benchmark
The RAID (Robust AI Detection) benchmark (arXiv:2409.14285) represents the current gold standard in detection evaluation. Developed by a consortium of researchers including those from the University of Pennsylvania, and utilized in research associated with the University of Houston, UC Berkeley, and Esperanto AI, RAID addresses the “easy data” problem that plagued earlier studies.
The dataset’s scale is unprecedented, containing over 6.2 million generations. However, its true value lies in its diversity. RAID evaluates detectors across three critical dimensions: Generative Model Diversity, Domain Variance and Adversarial Attacks.
1.2 The COLING 2025 Shared Task
Building upon the RAID dataset, the GenAI Content Detection Task 3 at the 2025 International Conference on Computational Linguistics (COLING) provided a blinded, competitive environment for detectors. Unlike static benchmarks where developers might overfit to the test set, the COLING task required systems to detect AI text from a fixed set of domains and models, including those unseen during training.
1.3 The University of Maryland & Microsoft Study: The Human Factor
While RAID focuses on software-vs-software, the study titled “People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text“ (arXiv:2501.15654) reintroduces the human element into the equation.
this study benchmarked commercial detectors against these human experts. The findings revealed that most commercial detectors failed to match human performance on “humanized” text, with the notable exception of certain tools.
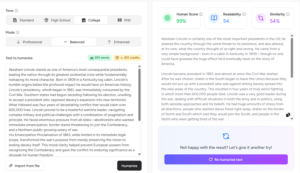
1. Pangram Labs
Unlike competitors that pivoted from plagiarism detection, Pangram leverage advanced research in what it callls “active learning”. This makes it the most accurate detectors for AI and human-modified AI texts.
Try Out Pangram Detection For Free Here
How It Works
The core of Pangram’s efficacy lies in its Active Learning framework, a methodology detailed in their winning submission to the COLING 2025 Shared Task.
Most deep learning detectors suffer from “chronic undertraining”—they converge quickly on easy examples (like raw GPT-3 text) but fail to learn the subtle patterns of adversarial examples. Pangram addresses this through a two-stage training procedure:
- Initial Training: A base model is trained on a massive, diverse corpus of human and AI-generated text.
- Hard Example Mining: This model is then used to inference over the training set again, specifically identifying “hard examples”—instances where the model’s confidence was low or the prediction was incorrect (e.g., high-quality “humanized” text).
- Targeted Retraining: The model is retrained with a heavy weighting on these hard examples. This forces the neural network to learn the deep, invariant features of AI generation that persist even after paraphrasing or obfuscation, rather than relying on superficial surface-level artifacts.
Furthermore, Pangram treats “humanization” (the use of tools to bypass detection) not as a separate domain but as a form of data augmentation. By incorporating the outputs of 19 different humanizer tools into its training pipeline as “transforms” (similar to how computer vision models use image rotation or cropping), Pangram learns to recognize the underlying “AI-ness” regardless of the surface-level noise added by the humanizer.
Detection Performance
The empirical data from 2024 and 2025 positions Pangram as the current performance leader, particularly in high-stakes, adversarial environments.
- RAID Benchmark & COLING Shared Task Results:
- Overall Accuracy (Non-Adversarial): In the COLING Shared Task utilizing the RAID dataset, Pangram (competing as Team Pangram) achieved the highest overall performance score. The system attained a 99.3% accuracy rate on machine-generated text across varied domains without adversarial attacks.
- Adversarial Robustness: This is the defining metric for Pangram. While other detectors saw performance drops of 20-40% when faced with attacks, Pangram maintained an accuracy of 97.7% in the adversarial subtask. This explicitly validates the efficacy of their active learning approach in countering techniques like homoglyph substitution and paraphrasing.
- False Positive Rate (FPR): The COLING task enforced a strict 5% False Positive Rate threshold for evaluation. Pangram achieved its high True Positive Rate (TPR) within this constraint.6 Independent audits and the company’s own whitepapers suggest that for long-form text (e.g., essays), the optimized FPR can be driven as low as 0.01% (1 in 10,000), significantly lower than the industry standard of 1-2%.
- University of Maryland Human-Expert Study:
- In the UMD study, Pangram was the only automated detector to match the performance of expert human annotators. In tests involving “humanized” text (text rewritten to evade detection), open-source detectors like Binoculars achieved a TPR of only 6.7%, and Fast-DetectGPT scored 23.3%. In stark contrast, Pangram achieved a TPR of 100%, effectively parity with the expert human consensus. This result indicates that Pangram has successfully encoded the high-level stylistic intuitions (the “AI-ese” detection) that human experts use.
Pricing
Pangram Labs targets the professional, enterprise, and institutional markets, reflected in a pricing structure that discourages casual use but offers high volume for organizations.
- Free Tier: A limited offering of 5 credits per day (approximately 5 document checks), designed for trial and verification rather than sustained personal use.
- Individual Plan: Priced at $20 per month (or $12/month if billed annually). This tier provides 600 credits per month, suitable for freelance editors or individual educators.
- Professional Plan: Priced at $65 per month (or $36/month annually) for 3,000 credits. This tier targets content agencies and smaller educational departments.
- Institutional/Enterprise: Custom pricing models are available, often structured around per-student licensing (approx. $5/month/student in bulk) or API usage volume, providing unlimited checks for large-scale deployments.
2. Originality.ai

Originality.ai has carved out a dominant position in the content marketing and SEO sectors. It prioritizes accuracy above all else, minimizing false negatives in the detriment of false positives.
Try Out Originality.AI Detection For Free Here
How It Works
Originality.ai utilizes a modified BERT/RoBERTa-based classification architecture, fine-tuned on a proprietary and continuously updated dataset. The company’s key differentiator is its “Turbo” model series (e.g., Turbo 3.0), which is explicitly engineered to detect paraphrased content.
Unlike detectors that look for “burstiness” (a natural variation in sentence length), Originality.ai’s model appears to learn the semantic and structural fingerprints left behind by paraphrasing tools like QuillBot.
Detection Performance
Originality.ai is exceptionally effective at finding AI text, but also leads to higher false positive rates than its competitors.
- RAID Benchmark Performance:
- Base Accuracy: In the RAID benchmark’s non-adversarial dataset, Originality.ai was the top-performing commercial detector, achieving approximately 85% accuracy at the standardized 5% FPR threshold
- Paraphrase Detection (The “Killer Feature”): Originality.ai’s performance on the “paraphrase” split of RAID is unrivaled. It achieved 96.7% accuracy on text obfuscated by paraphrasing tools. To put this in perspective, the average accuracy for other detectors on this split was approximately 59%. Originality.ai ranked 1st in 9 out of 11 adversarial attack types in the RAID study, cementing its status as the most robust tool against “spinning”.
- Vulnerability to Homoglyphs: Despite its prowess with paraphrasing, Originality.ai showed significant vulnerability to Homoglyph attacks (character swapping). Because its classifier relies on token embeddings, the corruption of tokens via Cyrillic swaps caused its detection confidence to plummet, unlike perplexity-based tools which measure character-level probability.
- False Positive Rate (FPR):
- While the benchmark normalized FPR for comparison, real-world data and independent reviews highlight that Originality.ai has a “Moderate” FPR, often estimated around 2-3% on its Turbo models, and potentially higher for heavily edited human text.21 The tool is known for flagging false positives on “dense” writing styles (e.g., legal or historical texts) that naturally lack burstiness.
Pricing
Originality.ai operates on a credit-consumption model, which appeals to businesses with fluctuating volume needs.
- Pay-As-You-Go: A one-time purchase of $30 provides 3,000 credits (300,000 words), with a 2-year expiration. This is a popular option for users who do not need a monthly subscription.
- Base Subscription: $14.95 per month (or $12.95/month annually). This includes 2,000 credits per month (resetting monthly) and unlocks features like full site scanning and team management seats.
- Enterprise: $179 per month for 15,000 credits and API access, targeting high-volume SEO agencies and publishers.
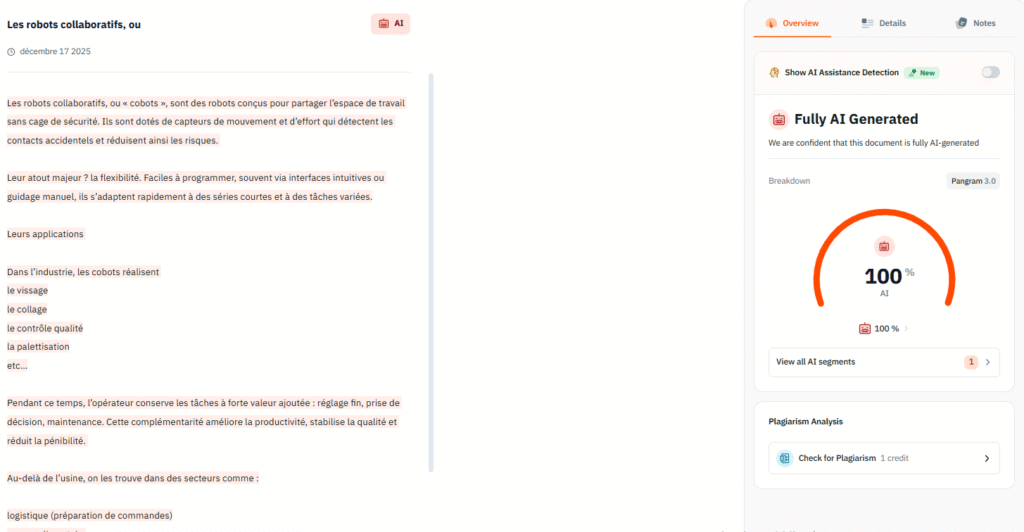
3. GPTZero
GPTZero centers on interpretability and fairness, prioritizing low false positives to protect students from wrongful accusations.
Try Out GPTZERO.AI Detection For Free Here
How It Works:
GPTZero’s foundational technology is based on two statistical metrics derived from the probability distributions of Large Language Models:
- Perplexity: A measurement of how “surprised” a model is by the text. An LLM generates text by selecting the most statistically probable next token, resulting in low perplexity (high predictability). Human writing, filled with idiosyncrasies and creative choices, has high perplexity (low predictability).
- Burstiness: This measures the variance of perplexity over time. Human writers naturally vary their sentence structure—following a long, complex sentence with a short, punchy one. This creates a “bursty” statistical profile.
Recent iterations of GPTZero have integrated “Deep Scans,” which overlay a neural classifier onto these statistical metrics to improve detection on newer models.
Detection Performance
GPTZero offers a distinct trade-off profile: it is safer for the accused but less effective at catching the sophisticated cheater.
- RAID Benchmark Performance:
- Overall Accuracy: GPTZero’s performance in the RAID benchmark is nuanced. Independent analysis of the full RAID table—which includes weaker open-source models—places its overall average accuracy lower, around 66.5%. This indicates that while GPTZero is excellent at detecting ChatGPT, it struggles to generalize to the broader ecosystem of LLMs (e.g., Llama 2, Mistral).
- Homoglyph Robustness: GPTZero is uniquely robust to Homoglyph attacks. Because homoglyphs do not fundamentally alter the statistical predictability of a sequence in the same way they confuse semantic embeddings, GPTZero’s accuracy dropped by only 0.3% under homoglyph attacks—the best performance among commercial tools in this specific category.
- Vulnerability to Paraphrasing: Conversely, GPTZero is highly vulnerable to paraphrasing. Tools like QuillBot work by swapping words for synonyms, which naturally increases the text’s perplexity. This artificial injection of “randomness” effectively mimics the statistical signature of a human, causing GPTZero’s detection rates to fall significantly compared to classifier-based tools like Originality.ai.
- False Positive Rate (FPR):
- GPTZero’s primary strength is its safety profile. In the RAID study and independent audits, it consistently demonstrated one of the lowest false positive rates, often <1%. This makes it the preferred tool for educators who are more concerned with avoiding wrongful accusations than catching every single instance of AI usage.
Pricing
GPTZero utilizes a “freemium” model that has driven its widespread adoption among individual students and teachers.
- Free Plan: Offers 10,000 words per month of basic scanning, with limited access to “deep” detection features.
- Essential Plan: $10 per month (billed annually) or $15 monthly. This tier increases the limit to 150,000 words per month.
- Premium Plan: $16 per month (billed annually) for 300,000 words. This tier includes plagiarism scanning and more detailed “writing feedback” reports.
- Professional: $23 per month (billed annually) for 500,000 words, targeting power users.
4. Copyleaks

Copyleaks is a heavyweight in the institutional market, serving as the backend detection engine for many Learning Management Systems (LMS) and enterprise platforms. It markets itself on multilingual capability and enterprise-grade security.
How It Works:
Copyleaks employs a proprietary AI-based classifier that analyzes text at the sentence and document level. Unlike simple perplexity checkers, Copyleaks claims to utilize a “fingerprinting” technology that analyzes the semantic context and logical structure of the text. A key differentiator is its multilingual support, capable of detecting AI content in over 30 languages—a feat that perplexity-based detectors (which are often English-centric) struggle to match. It provides a binary classification (“Human” or “AI”) accompanied by a confidence score.
Detection Performance
Copyleaks presents a paradox: high claims of accuracy in marketing and some controlled studies, contrasted with exclusion from or mixed results in major adversarial benchmarks.
- RAID Benchmark Status:
- Copyleaks is notably absent from the primary public leaderboards of the RAID benchmarkThis lack of transparency in the most rigorous public benchmark makes direct comparison difficult.
- Independent Studies & Robustness:
- In non-adversarial testing (e.g., standard ChatGPT output), Copyleaks performs exceptionally well, with studies citing 99.12% accuracy.
- However, its robustness is questionable. Independent testing indicates that its accuracy can drop to ~50% when text is processed through paraphrasing tools like QuillBot. This suggests that while effective against “lazy” cheating (copy-pasting), it is vulnerable to determined evasion.
- False Positive Rate: Copyleaks marketing claims a false positive rate of 0.2%. However, in broader academic contexts—particularly involving non-native English speakers—independent researchers have noted higher rates of false flagging, though generally lower than older iterations of detection technology. The tool’s binary nature (it typically flags text as “AI” or “Human” with high confidence) can also lead to a lack of nuance in “mixed” (hybrid) cases.
Pricing
Copyleaks utilizes a page-based credit system, where one page is defined as 250 words.
- AI Detector Only: Plans start at $9.99 per month for 100 pages (25,000 words).
- AI + Plagiarism: The combined package starts at $16.99 per month for 100 pages, reflecting its dual utility
- Scale: High-volume plans are available, scaling up to $75.99/month for 1,000 pages.
- Education/Enterprise: Copyleaks’ primary revenue stream comes from custom institutional licensing based on student FTE counts, often bundled with LMS integrations.
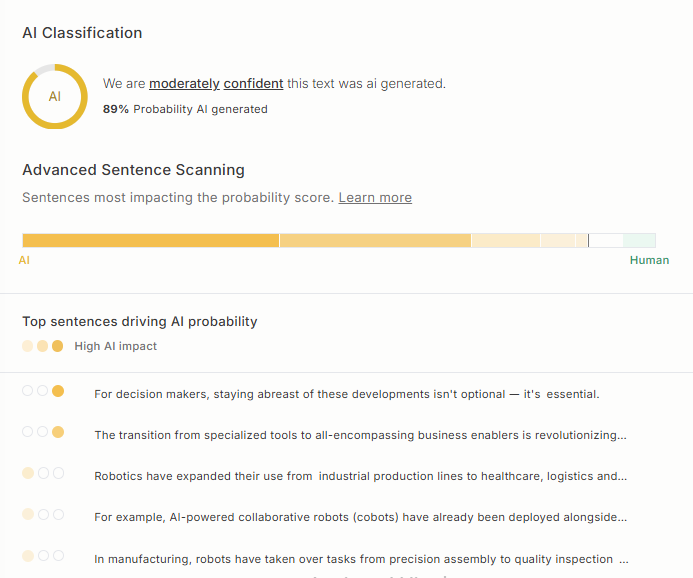
5. Turnitin
Turnitin is the incumbent hegemon of academic integrity, used by over 20,000 institutions worldwide. Its AI detector is not a consumer product but a feature embedded within its ubiquitous plagiarism detection suite.
How It Works:
Turnitin’s AI detection architecture is designed to be conservative. It focuses on identifying “Qualifying Text”—blocks of long-form prose—while ignoring lists, code, or short answers where detection is statistically unreliable.
The system breaks a document into segments (typically a few hundred words) and assigns a probability score (0 to 1) to each segment based on whether it matches the statistical signature of GPT-3/4. These scores are aggregated to produce an overall percentage. The model is a transformer-based classifier fine-tuned on Turnitin’s massive repository of student papers, giving it a unique training set of “authentic student writing” that competitors lack.
Detection Performance
Turnitin’s performance is defined by “safety-first” institutional tuning, which prioritizes low false positives at the expense of sensitivity.
- RAID Benchmark Status:
- Like Copyleaks, Turnitin is generally absent from public leaderboards like RAID due to its closed ecosystem. Public API access for benchmarking is not available.
- Accuracy & Robustness:
- Turnitin claims a <1% False Positive Rate (FPR) at the document level. To achieve this, they employ a high suppression threshold: if a paper detects less than 20% AI content, Turnitin often suppresses the score entirely or marks it with an asterisk to prevent professors from acting on weak signals.
- Vulnerability: Despite its dominance, Turnitin is not immune to adversarial attacks. Independent evaluations (e.g., Weber-Wulff 2023/2024) have shown that Turnitin is vulnerable to paraphrasing. In some adversarial tests, its accuracy dropped from >90% to ~30% when text was heavily rephrased or “spun”.
- The “False Positive” Reality: Despite the <1% claim, the sheer scale of Turnitin’s deployment means that even a 1% error rate affects thousands of students. Reports have highlighted that Turnitin struggles significantly with mixed content (hybrid human/AI writing) and non-native English writing (ESL). ESL writing often exhibits lower vocabulary diversity and simpler sentence structures, mimicking the “low perplexity” of AI, which has led to documented cases of bias and wrongful accusation.
Pricing
Turnitin does not sell to individuals.
- Institutional Licensing: Pricing is opaque and customized based on FTE (Full-Time Equivalent) student counts. Contracts typically run in the thousands to tens of thousands of dollars annually.
- Individual Access: Students cannot purchase Turnitin. The closest alternative is iThenticate (Turnitin’s product for researchers), which charges high fees (e.g., $100 per manuscript) and often lacks the exact same AI detection configuration as the institutional Feedback Studio.
6. Winston AI
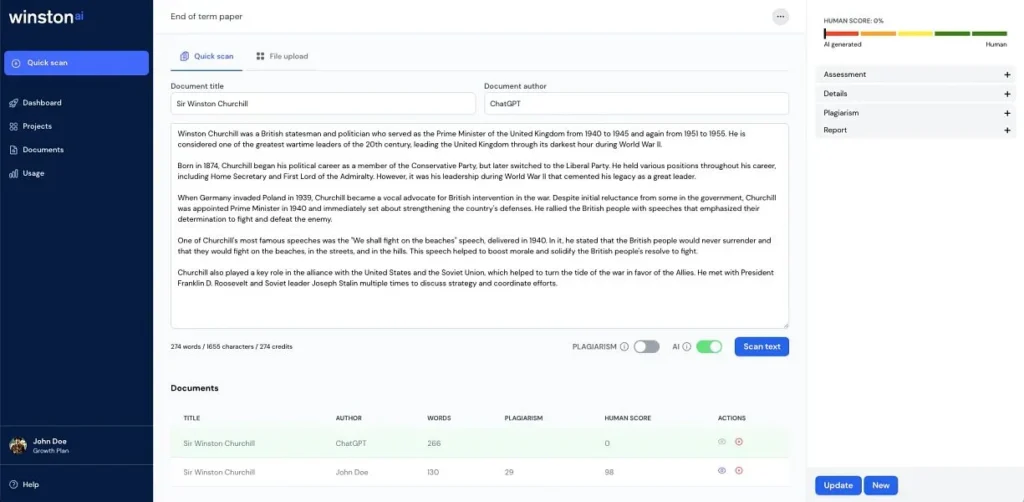
Winston AI positions itself as the “Gold Standard” of detection, emphasizing a user-friendly experience and specific features for educators, such as Optical Character Recognition (OCR) for physical papers.
How It Works:
Winston uses a multi-stage detection process trained on large datasets of AI and human text. Its primary technical differentiator is its integrated OCR (Optical Character Recognition) engine. This feature allows users to upload photos of handwritten essays or printed documents, which Winston converts to text before scanning. This addresses a specific “loophole” where students submit screenshots or photos to bypass text-based detectors. Winston provides a “probability map” that highlights specific sentences, similar to other tools.
Detection Performance
Winston AI’s marketing claims often diverge from the harsh reality of independent benchmarking.
- RAID Benchmark Performance:
- Independent analysis of Winston’s performance on the RAID dataset places its overall accuracy at approximately 71% across all models and domains.
- Strengths: Winston performs exceptionally well on standard GPT-4 and ChatGPT text—the most common tools used by students—achieving accuracy rates up to 90% in these specific subsets.
- Weaknesses: The tool struggles significantly with open-source models (like Llama 2 or Mistral) and heavily obfuscated text. Its performance on the RAID “paraphrase” split was notably lower than Originality.ai or Pangram.
- False Positives: While better than early-generation detectors, Winston has a documented issue with false positives on “dense” or technical human writing. Independent tests have shown it has lower specificity than GPTZero, meaning it is more likely to flag honest academic writing as AI.
Pricing
Winston AI offers a competitive, credit-based subscription model.
- Free Plan: A “trial” offering 2,000 credits (approx. 2,000 words) for 14 days, limited in functionality.
- Essential Plan: $12 per month (billed annually) or $18 monthly for 80,000 words.
- Advanced Plan: $19 per month (billed annually) for 200,000 words. This tier includes plagiarism checking and priority support.
- Elite Plan: $32 per month (billed annually) for 500,000 words, targeting heavy users.
Comparative Analysis & Best Choice
Pangram Labs’ dominance in the COLING task (97.7% adversarial accuracy) and the UMD study (matching human experts) suggests that the future of detection lies in Active Learning. By iteratively training on the “hard cases” that fool other detectors, Pangram has effectively inoculated its model against common evasion tactics like humanizers. This represents a generational leap over static classifiers.
The RAID benchmark reveals also a stark divide in handling paraphrased text. Originality.ai and Pangram are the only two tools that effectively neutralize the threat of “spinners” and humanizers. GPTZero and Turnitin, which rely heavily on statistical signatures (perplexity), are mathematically vulnerable to these attacks because paraphrasing tools function precisely by increasing the perplexity of the text.
For educational institutions, the cost of a false positive (accusing an innocent student) is infinitely higher than a false negative. In this context, Turnitin (with its <20% suppression threshold) and GPTZero (with its <1% FPR focus) remain the “safest” choices, despite their lower robustness. However, for a web publisher trying to avoid a Google SEO penalty, a false negative is the primary risk. For this user, Originality.ai is the superior tool despite its aggression.
Honorable Mentions
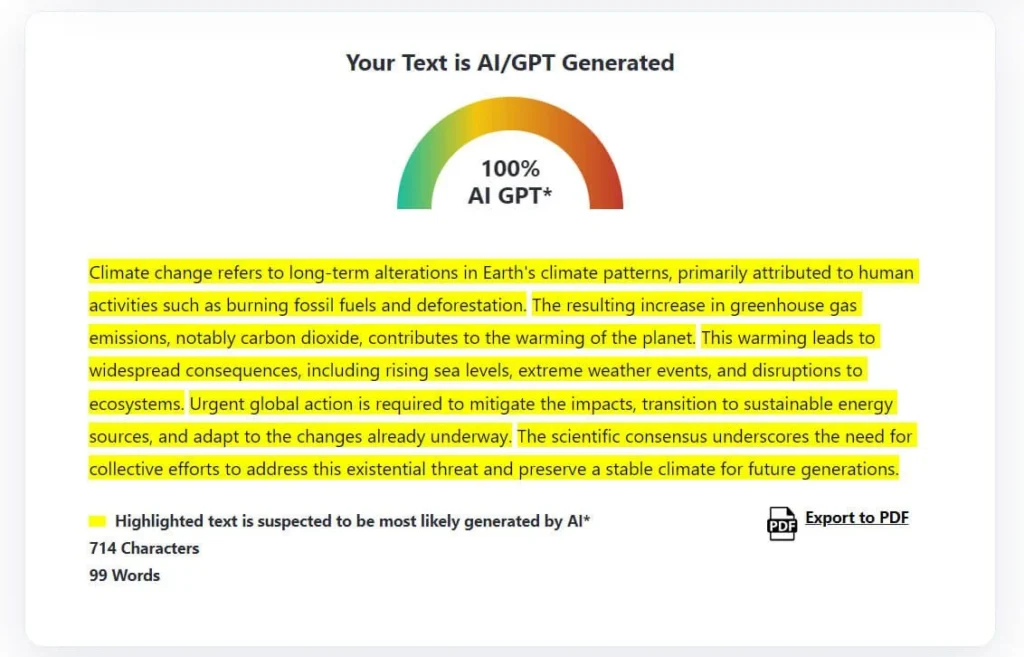
So there are all the most accurate AI detectors on the market. But there are many more, which some deserve honorable mentions.
ZeroGPT is one of the “OG” AI detection tools that became popular due to its simple interface and free access. Many casual users have tried ZeroGPT because it doesn’t require registration and allows fairly large text inputs (up to ~15,000 characters per check in the free version). It also offers a paid API and a Pro version for higher limits. ZeroGPT has a low accuracy and high positive rate, but maybe one of the best free AI tool you can find online.
There are several other AI detectors like Sapling AI detector, Crossplag, Content at Scale’s detector, Writer.com’s detector, etc. Some of these have niche strengths. However, none of these have outperformed the ones above across the board
Limitations and Challenges of AI Detectors
While AI detectors have advanced quickly, it’s crucial to understand their limitations and the challenges that remain. No detector is foolproof, and using them blindly can lead to mistakes. Here are some of the key issues with current AI detection methods:
- False Positives (Mislabeling Human Text as AI) – This is the most notorious problem. Detectors sometimes flag perfectly human-written prose as machine-generated. Non-native English writers are particularly at risk: one study showed over 60% of essays by ESL students were falsely tagged as AI by detectors, likely because simpler vocabulary and grammar can resemble AI output. Even sophisticated tools have had false positives on certain texts – for instance, scientific abstracts or formulaic writing can confuse detectors. A false positive can have serious consequences, from a student wrongly accused of cheating to an author’s original content being undermined. This is why many tool developers (Turnitin, GPTZero, etc.) aim to minimize false positives, even at the expense of catching every AI use.
- False Negatives (Missing AI-Generated Text) – The flip side is also an issue: detectors can fail to catch AI content, especially if the text has been modified or is from a model the detector wasn’t trained on. For example, Originality.ai performed well on GPT-4 text but struggled with detecting Claude-generated text in one study. As AI models diversify (with new systems like LLaMa, Bard, etc.), a detector might not recognize their style immediately. False negatives mean a detector can give a false sense of security – a student could pass AI-written content through a paraphraser and then the detector says “0% AI” (we observed exactly this with Hive and ZeroGPT, which output “0% AI” for some paraphrased passages that were indeed AI).
- Easy to Fool with Simple Tricks – Current detectors can often be defeated by surprisingly simple obfuscation techniques. Researchers from UPenn demonstrated that methods like paraphrasing text, using synonyms, inserting typos or extraneous spaces, and even replacing characters with lookalikes (homoglyphs) can dramatically lower detectors’ confidence. For instance, adding a few spelling mistakes or changing every tenth word to a synonym can make AI text slip past many detectors (because these methods raise the text’s perplexity, making it seem more “human”).
- Biases and Fairness – Beyond the native language bias, there are concerns about other biases. Some fear that detectors might disproportionately flag writing by certain demographic groups or in certain dialects as AI. For example, creative writing or poetry that breaks conventional rules might confuse detectors. Or writing by younger students (with simpler structure) could be unfairly flagged compared to that of an older student. One article noted the ethical minefield of detectors: false accusations could “increase educational inequities” and marginalize certain groups. While concrete evidence beyond the non-native study is limited, it’s an area to watch. The bias issue also extends to content domain – detectors trained mostly on Wikipedia/news might struggle with code, lists, or other formats of text.
- Reliability and Calibration – Many detectors, especially open-source ones, lack proper calibration by default. The UPenn RAID benchmark found some open detectors used thresholds that led to “dangerously high” false positive rates out-of-the-box. This means if one just grabs an AI model (like OpenAI’s old GPT-2 classifier) and uses it without careful threshold tuning, it might flag half of everything as AI. On the other hand, some companies calibrate their tools (e.g., setting a high threshold so that they only flag when very sure, like Turnitin’s 98% confidence needed). This difference in calibration partly explains why different tests get different results for the “same” tool. For instance, GPTZero set to high precision vs. high recall will behave differently. A challenge is that many tools don’t expose these settings to users, nor do they explain their operating threshold. So users are at the mercy of however the tool is tuned, which might not align with their needs.
- Evolving AI Models – AI text generators are rapidly improving and changing. A detector that worked well for GPT-3 may stumble on GPT-4, since GPT-4’s writing is more coherent and less predictable. Similarly, open-source models (like Vicuna, etc.) can be fine-tuned to have higher “randomness” or mimic human style, evading detectors. As new models come out, detectors need updates. For example, OpenAI’s own AI Text Classifier was withdrawn in 2023 because it was not accurate enough, especially as new models emerged and as people found ways around it. It had a mere 26% detection rate in OpenAI’s eval and a 9% false positive rate, leading OpenAI to acknowledge it was unreliable and discontinue it.
- Context and Partial AI Use – Current detectors mostly analyze a given text in isolation. They don’t know the context of its creation. If a human uses AI for an outline and then writes the rest themselves, detectors might see the human writing and not flag anything. Or if a human writes a draft and uses AI to polish a few sentences, many detectors will still label those sentences as human because the overall style is human. We’re reaching a point where human-AI collaboration in writing is common (e.g., a human writes and then asks ChatGPT to suggest improvements). Detecting partial AI assistance is a grey area. A high AI probability might technically be correct (some sentences are AI-tweaked) but the overall work is a blend. This raises the question: at what point does a document count as “AI-generated”?
- Lack of Standard Benchmarking – Until recently, each company was touting its own metrics often on self-selected data. We saw GPTZero citing figures like “no false positives at optimal threshold” and Winston AI claiming 99% accuracy, etc., but these are hard to compare. The RAID dataset from UPenn is a step toward a standard benchmark. It revealed how detectors fare across many conditions and made it clear that claims of “99% accuracy” often ignore adversarial cases or assume a perfect threshold.

Free Prompts and Ebook to Humanize Your Text
Download Now
Buchert Jean-marc
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.
All Posts