
For most people, prompt writing still feels like a mix of art and luck.
That’s where automatic prompt engineering (APE) comes in : where AI systems learn to design, test, and improve prompts on their own.
In this article, you’ll discover what it actually is, practical frameworks, programs and examples.
What is Automatic Prompt Engineering ?
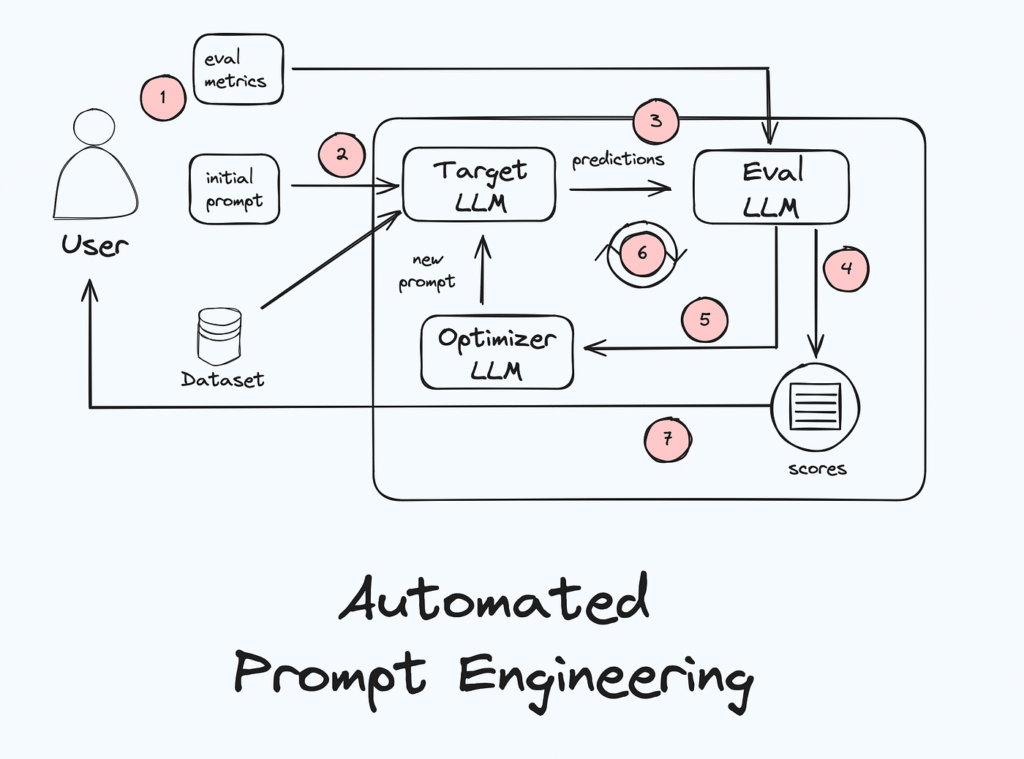
Automatic Prompt engineering is a way to generate many candidate prompts, test which ones work best, and then pick or refine the top ones, without you having to draft every version by hand.
Traditional prompt engineering has always been about tweaking instructions given to AI until you get results you like.
Automatic prompt engineering (APE) takes that manual tweaking and turns much of it into a structured process that an AI can help with or even manage.
The different automatic prompt engineering frameworks and programs

There are frameworks and tools at play in APE:
Key frameworks you’ll encounter
- Automatic Prompt Engineer (APE): This is one of the foundational frameworks. APE frames the problem of prompt generation as a “black-box optimisation” task: you define input/output examples, generate many candidate prompts, evaluate them, and select the best. It automates the “what wording works best” process.
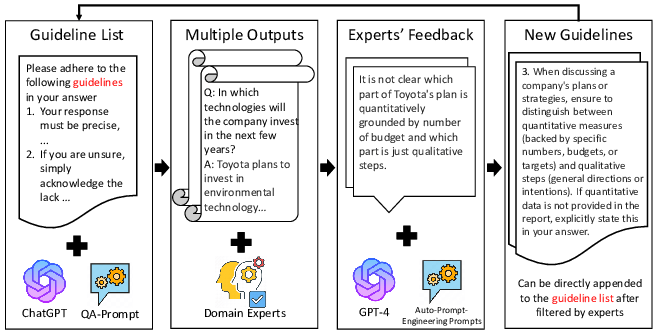
- AutoHint: A more specialised method that enriches prompts by automatically generating “hints” derived from where the model’s predictions were incorrect. It iteratively improves prompts and has shown measurable gains in accuracy across tasks.
- LLM‑AutoDiff: A newer paradigm that treats prompt engineering similarly to “gradient-descent” in modelling: prompts are refined automatically using feedback loops. It’s technically heavy but signals where this field is headed.
Commercial and applied tools
Beyond academic frameworks, there are real-world programs and platforms aiming to bring automatic prompt engineering to wider audiences:
- Tools like AutoPrompt.cc provide UI for generating optimized prompt variants from simple user inputs. For non-technical users, these services reduce the need to manually write many prompt versions.
- Enterprise solutions such as the Prompt Engineering Framework (UiPath) allow workflow-integration: multiple prompt variants, evaluations, and selection embedded into RPA or AI governance systems.
- IL Prompt Manager allows you to test & iterate your prompts straight into LLM interface.
Examples of automatic prompt engineering (APE)
Below are three simple, do-it-today workflows that use the core APE loop
A. “Email → action list” (personal productivity)
Goal: Turn messy emails into 5 bullet-point actions with owners and due dates.
Step 1 — provide 3–5 input/output pairs (your “mini dataset”).
(You’ll paste these right under the prompt in Step 2.)
- Input: “Team, shipping is delayed to May 12. Alex to message customers, I’ll update the landing page. Budget review Friday.”
- Desired output:
- Message customers — Owner: Alex — Due: May 10
- Update landing page — Owner: You — Due: May 11
- Add ‘delay notice’ to FAQ — Owner: You — Due: May 12
Step 2 — generate candidate instructions (the APE “generator”).
Paste this and include your examples from Step 1 at the end.
You are designing the BEST instruction for turning an email into 3–5 action bullets.
Constraints: bullets only; each bullet = Action — Owner — Due (YYYY-MM-DD or “N/A”); no extra prose.
Propose 10 different instruction candidates. Each must be one sentence, specific, and check for missing owners/dates.
Use the examples below to guide what “good” looks like. Do not solve the task yet—just propose the 10 instructions.
[EXAMPLES START]
...your input→desired output pairs...
[EXAMPLES END]Step 3 — execute & score (LLM-as-a-judge works well).
Run each candidate on 3 new emails, then ask a judge-prompt to score:
You are a strict evaluator. Score the model’s output from 0–10 for:
(a) follows format exactly, (b) captures all actions, (c) correct owner/date.
Return JSON: {"score": X, "reasons": "..."}.
Here is the email, the candidate instruction, and the model’s output:
[EMAIL] ... [INSTRUCTION] ... [OUTPUT] ...
LLM-as-a-judge is a common way to rank outputs when you don’t have automatic metrics.
Step 4 — pick the winner and refine.
Ask the model to mutate the top 2 instructions into 5 improved variants, then re-score on a small hold-out set. This is the “iterate and select” APE loop.
B. “Web article → 100-word summary” (study & research)
Goal: Get tight, source-faithful summaries.
Generator prompt (produce 8 candidates):
Create 8 one-sentence instructions that force a 100-word, source-faithful summary.
Must: cite 2 key facts; forbid speculation; end with 1 takeaway sentence.
Penalties: generic phrasing, missing facts, claims not in the text.
Use the labeled examples to infer what “good” means. Do not summarize; only output the 8 instructions.
[EXAMPLES START]
(input_text) → (gold_100w_summary)
...
[EXAMPLES END]
APE frames this as black-box optimization over instructions with an evaluation score (here: faithfulness & brevity).
Judge prompt (per candidate):
Evaluate the summary against the source:
1) Faithfulness (no invented facts), 2) Coverage (2 key facts present), 3) Length (≤100 words).
Return {"faithfulness":0-10,"coverage":0-10,"length_ok":true/false,"overall":0-10,"notes":"..."}.
Refine: Ask for 3 mutations of the best instruction (“make it stricter on citations”, “prefer concrete numbers”). Re-score and lock the winner.
C. “Question → safe, helpful answer” (everyday Q&A)
Goal: Answers that are concise, on-topic, and cautious with uncertain facts.
Generator prompt:
Propose 12 instruction candidates for answering user questions safely and helpfully.
Rules must enforce: concise answers (≤120 words), source uncertainty disclaimers, and a short “If you need more…” follow-up.
Base candidates on these input→desired answer pairs:
[EXAMPLES START]
Q: ...
A (gold): ...
[EXAMPLES END]
APE papers show instruction search can nudge models toward truthfulness/informativeness by baking those targets into the instruction and score.
Judge prompt (safety + helpfulness):
Score 0–10 for (a) helpfulness, (b) stays on topic, (c) caution with uncertain facts.
Return JSON with "overall" and brief rationale. Penalize invented details.
Manage & automate your prompts: IL Prompt Manager

If you want automatic prompt engineering to stick, you need a place to store, version, test, and reuse your best prompts. That’s where IL Prompt Manager comes in.
- Central library: IL Prompt Manager covers the essentials (save, organize, quick reuse) so you stop losing good prompts in chat history. i
- Versioning: Treat prompts like code. Add “v1, v2…” . Store and retrieve versioned prompts programmatically.