Table of Contents
- What Are AI Detectors?
- What Algorithmic Techniques AI Detectors Rely On
- Perplexity / Likelihood Scoring
- Burstiness / Variance in Predictability
- Stylometric & Linguistic Feature Extraction
- Watermarking / Hidden Signals
- Ensembles, Hybrid & Meta-Classifier Approaches
- Algorithmic Differences Between Common AI Detector Models
- GPTZero: The Statistical Starting Point + Deep Layers
- Turnitin’s AI Writing Detector: Hybrid & Embedded
- Originality AI: Holistic Classification + Pattern Recognition
- Copyleaks: Hybrid Methods + Explainability
- Are AI Detectors Really Reliable?
- How to Use AI Detectors Responsibly
Detectors are increasingly used in editorial workflows, academia, and brand compliance.
The problem? Explanations of how they work are often either vague or overloaded with jargon.
This guide gives you that clarity. You’ll learn what AI detectors really are and how they work concretely.
What Are AI Detectors?
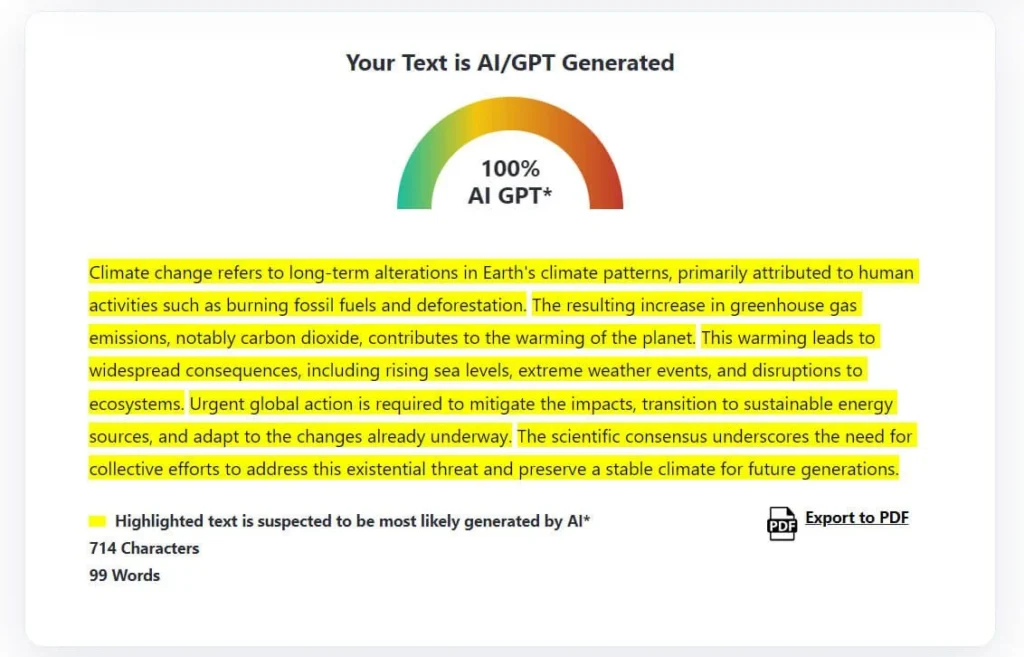
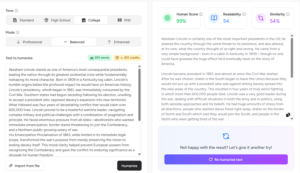
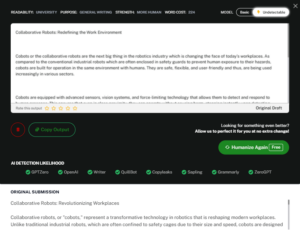
In simple terms, AI detectors are tools designed to estimate whether a given piece of text was generated (or heavily aided) by an AI model rather than written entirely by a human.
Developers of AI Detectors assume that AI-generated text leaves statistical footprints. Usually, LLM output tends to be more uniform, less variable, or more “predictable”.
That’s why many detectors look at internal measures like perplexity (how surprising each word choice is) and burstiness (variation in style across sentences).
Who use AI detectors?
- Academic settings often use them to check for cheating or excessive AI use in student essays.
- Publishers, editors, and content platforms may use them to enforce quality, authenticity, or originality standards.
- Brands and marketers might employ them to validate that content creators or agencies produce “human-sounding” work.
AI detectors come in different shapes:
- Standalone web tools or dashboards — you paste text or upload a file and get a score, percentage, or label (e.g. GPTZero, Originality.ai).
- Integrated detectors — embedded inside platforms, LMS (learning management systems), content management systems, or editorial tools.
- Hybrid or ensemble systems — use multiple detection techniques together (statistical + feature classifiers + watermark detection).
- APIs / services — tools you can call programmatically within your content pipelines, so each generated output can be scanned.
What Algorithmic Techniques AI Detectors Rely On
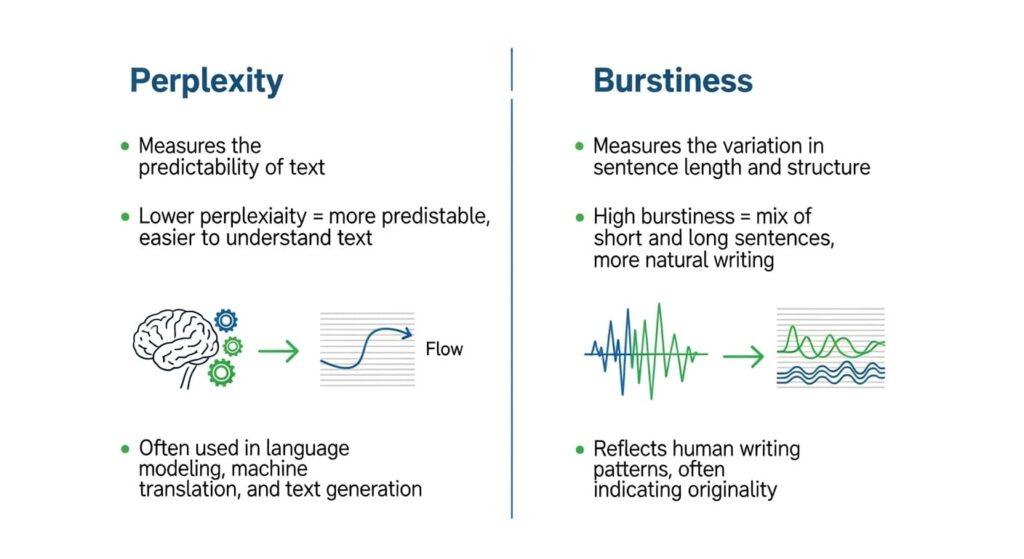
AI detector rely on a specific stack of algorithmic and statistical methods to assess your writing.
Perplexity / Likelihood Scoring
One of the core techniques in many detectors is perplexity (how surprising a writing sequence is).
- The detector (or a surrogate model) computes the probability for each token given its context. It then sums the negative log probability across tokens (or averages over sentences) to compute a score. Lower average surprise → lower perplexity.
- Text that is too predictable (i.e. a language model finds it easy to guess) often gets flagged as more “AI-like.”
- Many detectors also break down scores at the sentence level. They measure per-sentence perplexity, then derive statistics (mean, variance) across the document.
- Some detectors also use negative log-likelihood curvature as a refined measure: how rapidly the likelihoods change across small perturbations of the text. That can help identify sensitive points where the model is overly confident.
Burstiness / Variance in Predictability
A second technique complements perplexity: burstiness — measuring how much variation there is across a text in terms of predictability, structure, or complexity.
- After computing sentence- or chunk-level perplexity, detectors look at variance (e.g. standard deviation, coefficient of variation). If every sentence is roughly equally predictable, burstiness is low — a red flag. If some sentences are more predictable and others are more surprising, that signals a more human rhythm.
- Besides probability variation, detectors may also look for variation in sentence length, clause structure, punctuation, syntax shifts, or shifts in style across paragraphs.
- Together, perplexity + burstiness help distinguish flat, uniform output from writing that varies in tone, complexity, and surprise.
Stylometric & Linguistic Feature Extraction
To go beyond raw token prediction, many detectors use stylometry : a branch of computational linguistics that quantifies writing style via features.
- They extract features such as vocabulary richness, type/token ratio, function word usage, sentence length distribution, punctuation frequencies, POS (part-of-speech) tag distributions, n-gram repetition, and syntactic patterns.
- Certain patterns (e.g. overuse of transitional adverbs like “furthermore,” unusually low use of contractions, repetitive structures) may correlate with AI-generated style.
- Detectors may also use embedding similarity or vector space comparisons: converting sentences or paragraphs into embeddings (semantic vectors) and comparing distance to known “AI clusters” or “human clusters.”
- Some detectors use classifiers (random forests, SVMs, neural networks) trained on labeled corpora (human text vs AI-generated text) with these stylometric features as input.
Watermarking / Hidden Signals
One more emerging technique: watermarking or hidden “fingerprints” embedded in AI-generated text.
- The idea is that the generation model intentionally biases token selection (in invisible ways) to embed a statistical watermark—like a weak signal in token distributions.
- At detection time, the watermark can be detected via checking expected token usage deviations. For example, some watermark schemes assign a “blacklist” subset of vocabulary at each step based on hashing of previous tokens, making those words less likely to appear (but subtly) during generation. At detection time, you compare actual usage vs expectation.
- Watermarking is attractive because it can give more deterministic detection. But it’s vulnerable to post-editing, paraphrasing, or reprocessing text, which may break or wash out the watermark.
Ensembles, Hybrid & Meta-Classifier Approaches
No single technique is foolproof. Most modern detectors use hybrid or ensemble methods, combining multiple signals into a final verdict.
- They feed features (perplexity scores, burstiness metrics, stylometry, watermark presence, embedding distances) into a higher-level meta-classifier (e.g. logistic regression, neural net).
- Recent research proposes weighting models by inverse perplexity: detectors built on multiple transformer models but giving more weight to the ones that find the text less predictable (i.e. lower perplexity gets higher weight) — an ensemble that adapts to text difficulty. The LuxVeri system (COLING 2025) uses precisely that technique to improve robustness across domains.
- Some detection models also incorporate adversarial training: they deliberately train on paraphrased or manipulated AI outputs so their classifiers become more robust to evasion.
- Others combine retrieval-based defenses: when a candidate text is suspicious, the detector searches a database of previously generated text to find near matches (indicating reuse or replication). If found, that raises the AI probability. The paraphrase evasion work suggests retrieval is one of the more reliable defenses.
- Some detectors calibrate thresholds or decision boundaries per genre, length, or domain (e.g. different cutoffs for academic essays vs blog posts).
Algorithmic Differences Between Common AI Detector Models
AI detectors’ techniques differ one from another. Below, I compare major detection systems (you can also check my top of the most reliable AI detectors based on the landmark RAID study)
GPTZero: The Statistical Starting Point + Deep Layers
GPTZero is often treated as a reference point in detection. Its early fame rests on combining perplexity + burstiness as a statistical “first layer.”
Core approach:
- GPTZero computes sentence-level perplexities using a language model (or surrogate) and then measures the variance (burstiness) across those sentences.
- That statistical layer gives a coarse signal: texts that are too predictable or too uniform are more suspicious.
But GPTZero doesn’t stop there. Over time, it layered on additional features and classifier methods:
- It integrates ML classification layers that consider multiple signals beyond mere uniformity or predictability.
- It uses sentence-by-sentence classification and gives confidence scores and highlighting (flagging parts of a document more likely AI).
- GPTZero claims to train on a mixture of human and AI-generated texts to tune its detection logic.
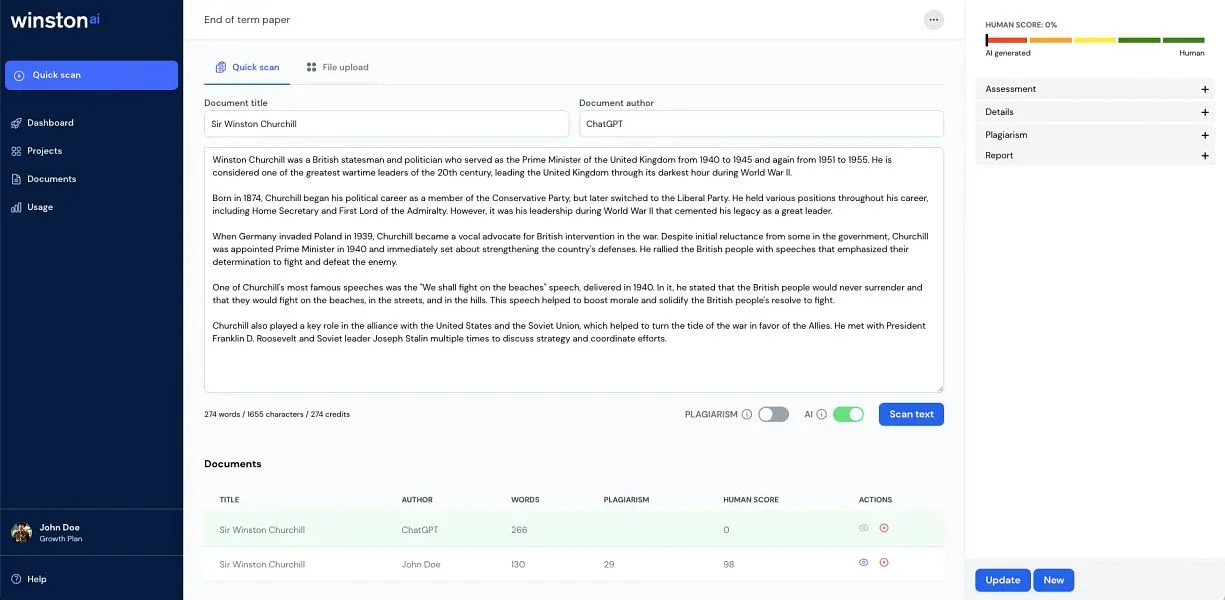
Turnitin’s AI Writing Detector: Hybrid & Embedded
Turnitin, a major player in academia, has introduced AI detection as part of its broader text analysis toolkit.
Core architecture and methods:
- Turnitin layers its AI detection module on top of its existing infrastructure (which handles plagiarism and similarity).
- It uses a model trained to detect generative AI usage in academic submissions. The “AI writing indicator model” examines “qualifying text” (long-form prose) for features typical of AI writing.
- Turnitin does not disclose full inner workings or threshold logic publicly; some elements are proprietary and opaque.
Approach differences vs GPTZero:
- Turnitin is more of a black box—while GPTZero publishes some transparency about its statistical foundations, Turnitin’s model is more embedded and less publicly explained.
- Turnitin’s model is designed to work at document scale in academic contexts. It flags “sections” within a text (not just whole documents) and provides percentages of text likely AI-generated.
- Turnitin’s reported accuracy claims include ~98% detection for AI content, though with caveats and disclaimers about false positives.
- Because Turnitin is tied to educational systems, it’s optimized for student essays and may struggle more outside those domains (blog posts, marketing content).
Originality AI: Holistic Classification + Pattern Recognition
Originality AI positions itself as a premium AI detection tool that combines classification and pattern analysis across multiple models and languages.
Key algorithmic traits:
- It treats AI detection as a binary classification problem: for a given sentence or chunk, it estimates a probability that it was AI-generated. If the probability exceeds a threshold, it flags it.
- It claims to use multiple language models in its training and detection pipeline, including models like ChatGPT, Claude, Llama, and others. The idea is to recognize patterns across different AI vendors.
- Its detection score is presented as a “confidence” percentage (e.g. “60% Original, 40% AI”)—but the score is not a literal split between human and AI content; it’s a probabilistic assessment.
Copyleaks: Hybrid Methods + Explainability
Copyleaks is better known for plagiarism detection, but its AI detection module is robust and increasingly visible in content cycles. Here’s how they approach it:
Core algorithmic strategies:
- Copyleaks claims to use statistical patterns like perplexity, burstiness, repetitive phrasing, and other linguistic irregularities in its detection pipeline.
- The AI Detector is integrated with a “AI Logic” feature: it surfaces signals (e.g. “AI Phrases”) that show which parts of the text triggered suspicion. This gives you more insight into why something was flagged.
- It also uses a source match component: it checks whether parts of the text resemble known AI-generated content that already exists (published or in their database).
- Copyleaks emphasizes high accuracy and broad model support, claiming it detects content from ChatGPT, Gemini, Claude, and more.
Are AI Detectors Really Reliable?

Every AI detector is essentially guessing, a well-educated guess, backed by data, but still a guess. So they are definitely not 100% reliable.
The underlying challenge is that AI and human writing now overlap more than ever. Large language models are trained on vast amounts of human text. They don’t produce robotic gibberish anymore; they replicate human rhythm, variation, and tone. That overlap shrinks the margin detectors rely on.
For example:
- A well-written human blog post can be flagged as “likely AI” simply because it’s structured and fluent. That’s what False positives are (when human writing is misclassified as AI). And it’s perhaps the biggest issue for marketers and educators.
- Conversely, an AI-written text that’s slightly rephrased or rearranged by a human may slip through undetected. That’s what we call false negative. Studies show that simple paraphrasing can cut detection accuracy by over 60 %. Precisely why reliability cannot mean certainty.
Bias & Limitations
Even more than that, AI detectors show inherent biases & inconsistencies :
- Non-english speaker bias: AI detectors can display bias, particularly against content produced by non-native English speakers, often misclassifying it as AI-generated. This can lead to situations where your genuine content is flagged incorrectly.
- Impact of model evolutions: the continuous advancement of LLM models makes AI detectors lose accuracy and reliability over time. For example, there’s still a huge gap of accuracy considering the detection of GPT-3,5 compared to GPT-4 and Claude 3. AI detectors need to constantly adapt to stay relevant.
- Formal writing: more formal and structured writing might be more likely to be flagged as AI content by AI detectors. That’s why some tools like Originality.AI warn users to only review more informal writing.
How to Use AI Detectors Responsibly
Based on all of this, you want to handle AI detectors’ conclusions with caution :
- Use multiple detectors. Cross-check results (e.g., GPTZero + Originality AI + Copyleaks). If all agree, you can be more confident. If they diverge, investigate.
- Read the explanation layer. Tools like Copyleaks’ AI Logic or GPTZero’s highlights show where the algorithm found “AI-like” phrasing. Review those lines manually.
- Balance signal with context. A 60 % AI score on a short paragraph doesn’t mean plagiarism. Consider text length, genre, and prompt context before deciding.
- Edit strategically. When detectors flag text, adjust rhythm, vary phrasing, and insert concrete details. It’s usually enough to lift burstiness.
- Avoid over-optimization. Don’t write for the detector; write for clarity and readers. Ironically, human-centered writing naturally scores better.
- Educate stakeholders. If clients or editors rely on detector scores, help them understand the limits. Share credible studies showing error margins.

Free Prompts and Ebook to Humanize Your Text
Download Now
Buchert Jean-marc
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.
All Posts