Table of Contents
- Why Consider Alternatives to ChatGPT?
- 1) ChatGPT creative writing is limited
- 2) Restricted context window
- 3) Openness, cost, and control (especially for teams)
- Top Writing Tools Alternatives to ChatGPT
- 1. Claude (Sonnet 4.5)
- 2. Gemini (2.5 Pro)
- 3. DeepSeek (open-source)
- 4. Grok (xAI)
- 5. Mistral (open-source, EU)
- 6. OpenRouter
As the newer ChatGPT versions evolved, they became better at being safe -less likely to go off-track, but also less likely to surprise you.
That’s why, in 2025, more and more writers are exploring alternatives.
In this article, we’ll walk through the best ChatGPT alternatives for writers in 2025
Why Consider Alternatives to ChatGPT?
If you rely on AI to draft articles, briefs, or stories, you’ve likely noticed something: no single model is best at everything. And ChatGPT doesn’t break this rule.
1) ChatGPT creative writing is limited
One of the sharpest critiques of ChatGPT and especially the latest version (GPT-5) is related to story and narrative quality. Writers points to incoherent plots, bizarre metaphors, and logical failures even when using advanced prompting.
The LLM Public arena results back this up: across millions of crowd votes, ChatGPT5, the latest version is ranked lower than other frontier models in this respect (Claude & Gemini) and even lower than earlier ChatGPT versions (4o and 4,5). That doesn’t mean ChatGPT is “bad”—it means your chance of getting the tone you want on the first pass may be higher with a different model for certain genres.
2) Restricted context window
When you write long briefs, literature reviews, or policy docs, you need a model that can hold a lot of source material in working memory and keep arguments straight over dozens of pages. ChatGPT’s newer “Thinking” tier raises the ceiling, but it’s still finite.
Two headaches show up in practice:
- Citation drift. Even with a large window, LLMs can hallucinate or blur sources when summarizing many documents at once; long-context alone doesn’t guarantee faithful grounding.
- Context squeeze. You trim citations to fit, lose nuance, and the model forgets early constraints.
3) Openness, cost, and control (especially for teams)
Two operational questions matter as much as raw model quality: Where does our data live? How much can we customize?
Data retention & privacy.
- OpenAI’s enterprise pages say workspace admins control retention; deleted chats are typically purged within 30 days—unless there’s a legal hold. In 2025, a U.S. court ordered OpenAI to preserve user chats for the NYT case (consumer tiers affected; Enterprise/Edu and zero-retention API excepted), which is a reminder that policy can change under litigation.
- API customers can enable Zero Data Retention; OpenAI says API logs are removed after 30 days absent legal requirements. Some cloud partners offer regional storage or data-residency options.
Customization & fine-tuning.
OpenAI supports fine-tuning on select models (e.g., GPT-4o and minis). That’s good for tone, format, and domain compliance, but you still can’t self-host ChatGPT or train from scratch; customization lives inside their platform (or Azure).
For tightly regulated workflows, that means you trade full control for managed convenience: faster results, less infra—and less architectural sovereignty over updates or routing.
Top Writing Tools Alternatives to ChatGPT
With a growing number of AI tools available for content creation, there are many alternatives to ChatGPT writing capabilities. Here’s a ranking of the most promising substitutes :
1. Claude (Sonnet 4.5)

Leaderboard:
Claude has always been the writer’s model. Since its first iterations, it carried that spark — a distinctive literary sensibility, a taste for rhythm, and a quiet emotional intelligence that most models never mastered. After a short creative dip in the Claude 3 era, Claude Sonnet 4.5 feels like a full return to form. On most creative leaderboards it now ranks at the very top for fiction, dialogue, and poetry. I
From what I’ve seen across hundreds of prompts — short stories, essays, and Shakespearean sonnets — Claude 4.5 Sonnet is easily one of the best AI writing partners for anyone chasing imagination and authenticity.
Strength:
- Natural storytelling flow. Claude writes with rhythm and momentum. Its fiction feels structured yet alive — characters move, scenes breathe, and tension builds naturally.
- Dialogue with genuine rhythm. Conversations sound believable. Characters interrupt each other, hesitate, and react — a detail most models still miss.
- Poetic control. When you ask for verse, it doesn’t just rhyme — it lands meaning. Its sonnets feel intentional, often with emotional turns that make them feel human-written.
- Voice adaptation. Feed Claude two or three paragraphs of your own text, and it mirrors your cadence, sentence length, and diction with impressive precision. It catches tone faster than most LLMs.
- Inventive imagery. Claude consistently avoids tired analogies. It reaches for small, concrete visuals that anchor emotion — a ticking phone screen, a half-folded letter, a broken glass on a desk.
- Balance between logic and art. The “thinking” mode helps it maintain narrative coherence and emotional pacing simultaneously — a rare mix.
- Excellent for essays and reflective writing. Personal, opinionated, or brand pieces come out more nuanced than from other models; it understands subtext and implication.
Limitations:
- Resource intensity. It’s a large model; context-heavy requests may take longer and cost more tokens than leaner alternatives.
- SEO and technical depth can be light. In structured guides or keyword-dense tasks, it sometimes glosses over detail. You’ll need a clear outline or follow-up prompts to force specificity.
- Over-polished tone. The prose can sound too smooth or formal if you’re aiming for raw, conversational texture. You might need to break sentences, add fragments, or shorten transitions.
- Guardrails on edgy topics. Anthropic’s safety filters can clip more controversial or experimental phrasing. Don’t expect Claude to lean into irony, dark humor, or strong political stances.
- Occasional pacing drift. In long stories, it sometimes resolves conflict too neatly or cuts tension early. Giving it explicit beat-by-beat direction helps maintain suspense.
- Less analytical precision in research-heavy writing. Compared to Gemini 2.5 Pro or ChatGPT 5, Claude can favor style over factual completeness.
2. Gemini (2.5 Pro)
Leaderboard:
If Claude is the writer’s model, Gemini 2.5 Pro is the researcher’s. It currently tops most public leaderboards, including LMSYS’s text and reasoning arenas, and ranks among the highest overall LLMs across use cases. Gemini’s advantage lies in scale and structure: its massive context window, factual precision, and multi-step reasoning make it ideal for non-fiction writing, SEO workflows, and research-based content.
Strength:
- Unmatched factual precision. Gemini checks itself mid-generation. You can sense it cross-referencing logic instead of free-associating. The factual consistency in essays and technical guides is excellent.
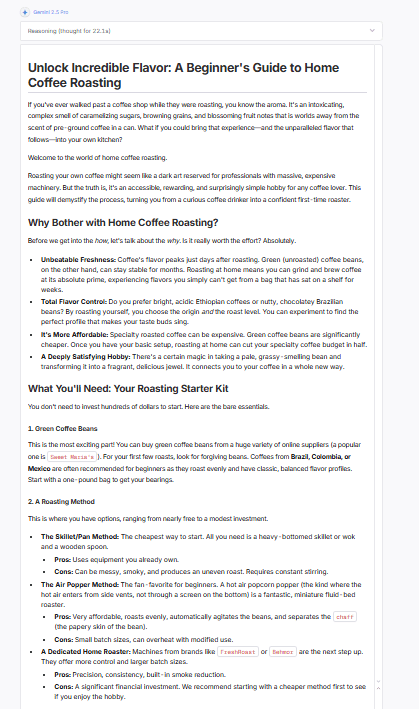
- Detailed, step-by-step structure. When you give Gemini a process-driven task (like your coffee-roasting example), it breaks it into ordered, labeled sections with crisp transitions — method → equipment → process → result. You rarely need to re-organize its drafts.
- Massive context window. It comfortably handles long documents — perfect for content audits, literature reviews, and book-length research projects. You can feed it full PDFs or multi-page notes and it still holds coherence.
- Powerful reasoning model. Gemini 2.5 Pro isn’t just a text model; it’s a reasoning model. It follows argument chains, anticipates counter-points, and supports claims with evidence more naturally than most LLMs.
- Strong SEO writing. It excels at hierarchical breakdowns: H2s, bullet lists, callouts, and summaries that actually align with search intent. It understands what “answering the query” means.
- Balanced tone and diction. Gemini writes clearly, without over-embellishment. It’s ideal for professional blogs, whitepapers, and marketing explainers that need authority without flourish.
- Robust citation ability. When prompted correctly (“add numbered sources or citations”), it anchors its claims in plausible references and consistent formatting — a big win for literature reviews or research pieces.
- Long-form stability. Essays above 1,500 words keep internal consistency. It tracks thesis, sections, and evidence through the entire piece, with fewer logical gaps than comparable models.
Limitations:
- Formatting quirks. Sometimes overuses nested bullets or numbered lists, making the draft look like documentation rather than prose.
- Less creative warmth. Gemini can write fiction, but its stories feel calculated. You get logic, not spontaneity. Dialogue may sound functional rather than emotional. For narrative voice, Claude still wins.
- Occasional rigidity. Because it leans on structure, Gemini sometimes ignores stylistic play. You might have to ask it explicitly to vary rhythm, shorten lines, or add sensory language.
- Formatting over style. It tends to produce clean but formulaic sections (lists, headings, sub-steps). That’s great for SEO, less so for essays that need lyrical movement or metaphor.
- Dry tone in creative copy. Marketing text can sound too corporate unless you inject tone directives (“make this sound conversational,” “add friendly humor”).
- Slow response on huge inputs. Its reasoning chain increases latency. With very long prompts, it may pause mid-generation or take noticeably longer than ChatGPT or Claude.
- Fiction limitations. It can construct solid story logic but lacks spark — metaphors stay surface-level, and emotional arcs feel engineered rather than felt.
3. DeepSeek (open-source)
Leaderboard:
In 2025, DeepSeek earned real buzz: a frontier-level, Chinese open-source model that most writers could try without breaking the budget. For months it sat at or near the top of open-source rankings. It’s not always the single best on any one axis, yet across samples it delivers reliable, useful drafts—and you get the open-source freedoms that closed models don’t offer.
Strength:
- Open and flexible. You can run DeepSeek locally, on a server, or behind your own API. That means privacy, control, and predictable costs.
- Easy to fine-tune. If your brand voice needs sharper edges or domain jargon, you can tune on a handful of house samples and lock in tone faster than with closed models.
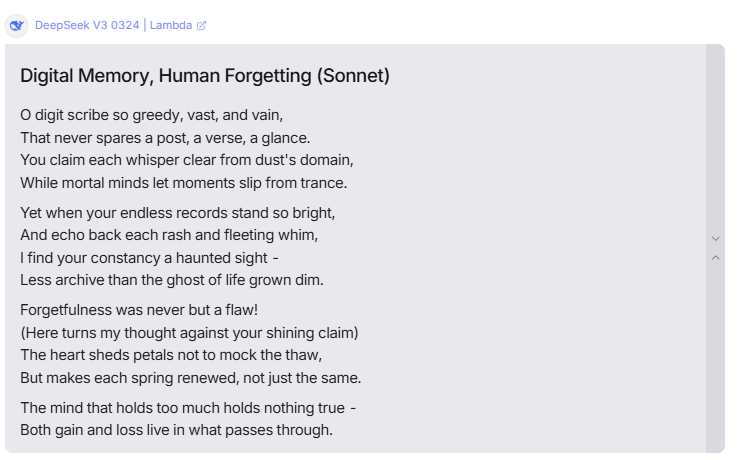
- Creative instincts. On fiction prompts, DeepSeek shows good story sense: a clear arc, specific images, a payoff. The sonnet tests were clean—rhyme held, the turn landed.
- Balanced output. Essays, guides, and blog posts come out structured and readable. It won’t flood you with fluff, and it stays inside the brief more often than not.
- Cost efficiency. For teams shipping lots of drafts, token costs plus local hosting can beat proprietary pricing by a wide margin.
- Modding the guardrails. Depending on the checkpoint you choose, you can loosen or tighten style constraints. That’s useful if your brand voice leans candid or off-beat.
- Strong toolchain support. You’ll find adapters, inference servers, and prompt routers ready to go. Less glue code. Faster setup.
- Good with outlines. When you feed it clear section goals, it hits the beats and keeps paragraphs tight.
Limitations:
- Not the absolute best at any one thing. In head-to-heads, Qwen or Claude can edge it on pure creativity; Gemini can edge it on long-context reasoning.
- Occasional flat lines. Without style guidance, DeepSeek can slip into plain phrasing. You’ll want a style guide prompt to keep diction crisp.
- Fewer “wow” metaphors out of the box. It builds solid scenes, but surprise lines are less frequent than with Claude. Add a “one fresh image per paragraph” rule to help.
- Setup overhead. Local deployment means you own the stack: GPU choice, updates, monitoring. Great for control, but it’s still ops.
- Citations and sourcing. It can outline research well, yet it needs explicit instructions to anchor claims with sources and links.
- Guardrail variance. Different community checkpoints have different safety and tone. You must pick and test the right one for production.
4. Grok (xAI)

Leaderboard:
Grok sits in a different lane. Where other models aim for safe polish, Grok 4 leans curious, fast, and a little unruly—in a good way. It draws on the X ecosystem for timely context and runs with lighter stylistic guardrails, so the voice often lands with more bite. In fiction prompts, it takes chances (new settings, stranger metaphors). In essays, it’s the one most likely to pick a side and argue it. For SEO, it’s fine—not the most exhaustive—but it will still map intent and structure a page you can ship after a quick pass.
Strength:
- Edgy, opinionated tone. Grok isn’t shy. Essays don’t just summarize; they stake a claim, contrast viewpoints, and bring in references you don’t see elsewhere.
- Reasoning + personality. The latest Grok models add genuine line-of-thought control. You feel the progression: premise → counterpoint → synthesis. Still punchy.
- Creative risk-taking. In short stories, it changes place and POV more freely, introduces unexpected objects, and doesn’t default to the same three metaphors. The “Miami instead of Anywhere, USA” move is typical—and it works.
- Timely instincts. With X-informed context, it’s prone to weave in current debates, public figures, or fresh examples without sounding like a recap machine.
- Good at contrarian frames. Ask for a “steelman of the losing side,” and Grok will oblige. It’s useful for think-pieces, hot takes, and editorial copy that needs a point of view.
- Snappy transitions. Less “Moreover/Additionally” and more natural pivots. Paragraphs feel conversational, not corporate.
- Fun for prompts with vibe. If you give it a style cue (“noir essay,” “gonzo intro,” “deadpan humor”), Grok follows the brief with fewer apologies.
Limitations:
- SEO depth is mid. It will outline and hit headings, but detailed sub-steps, tool-by-tool comparisons, and table-level specifics often need a second pass or a research-first model.
- Heat over caution. That opinionated swing can push tone beyond some brand guidelines. If your voice is conservative, you’ll be trimming edges.
- Citation discipline. Grok will draw on outside ideas, but it needs explicit instructions to format and anchor claims (“add numbered citations,” “link studies, not headlines”).
- Inconsistent lyrical control. It can be brilliant one paragraph and a little chaotic the next. For poetry or tight meter, Claude is steadier.
- Risk of topical drift. With current-event instincts, it sometimes chases the interesting aside instead of the brief. Pin it to a section outline.
- Safety variance vs. brand needs. Lighter stylistic guardrails mean you must enforce your own red lines (tone, topics, taboo phrasing) in the prompt.
5. Mistral (open-source, EU)

Leaderboard:
Mistral rarely tops the global charts; it usually sits mid-pack (think 10th–20th range depending on the benchmark and checkpoint). But it earns a spot here for a simple reason: it’s open-source, European, and dependable. If you care about data residency, privacy controls, or avoiding both U.S. and Chinese closed vendors, Mistral is the practical pick.
In writing tasks, it’s steady if not spectacular. Output can feel a bit formatted in places; fiction isn’t as subtle as Claude or as bold as Grok. For SEO and straightforward non-fiction, though, it does the job with clean structure and minimal fuss.
Strength:
- EU data posture. If you need European hosting and stricter compliance stories, Mistral is the easiest “yes.” Fewer policy hurdles for teams with sensitive material.
- Open-source control. Run it locally or on your cloud, tune guardrails, and decide how your data moves. No black-box surprises.
- Predictable structure. For briefs, FAQs, and basic how-to content, Mistral gives tidy headings, short paragraphs, and logical steps without over-explaining.
- Low friction for SEO scaffolds. H2/H3 breakdowns, bullets, and checklists come out clean. With a quick prompt for sub-steps, you get publishable outlines fast.
- Fine-tuning friendly. A small in-house dataset (voice samples, brand rules) goes a long way. You can lock in diction and cadence better than with many closed models.
- Cost and latency. Lightweight checkpoints run fast and cheap. Great for scale when you’re shipping lots of listicles, feature pages, or help docs.
- Stable “house style.” Less drift between sections. If you need consistent tone across many pages, Mistral’s conservative outputs help.
- Tooling ecosystem. Strong support across open inference servers, RAG stacks, and orchestration tools. Easy to drop into existing pipelines.
Limitations:
- Not a reasoning model (by default). On long, multi-step arguments or literature reviews, it can miss nuance or flatten counterpoints. You’ll need tighter prompts or retrieval to keep depth.
- Fiction feels square. Scenes land, but the prose can read safe. Fewer surprising images, less subtext in dialogue. For stories or lyrical copy, Claude still wins.
- Formulaic cadence. Without a style guide, it leans into balanced sentences and neat transitions. You may want to inject rhythm (fragments, short beats) in post.
- Shallow SEO details. It outlines well, but tool comparisons, stats, and pitfalls need prodding. Ask explicitly for “metrics, ranges, and examples” per subsection.
- Citations on request only. It won’t anchor claims unless you ask. Add a sourcing rule in every brief.
- Model spread matters. Different Mistral checkpoints vary in capability. You’ll need to test and standardize the one you ship to production.
6. OpenRouter
Leaderboard:
OpenRouter isn’t a model like the others in this ranking. It’s actually a platform that connects you to all the major LLMs in one place. You can test Claude, Gemini, DeepSeek, Grok, Mistral, Qwen, and others side by side without opening new accounts or juggling different APIs.
That makes OpenRouter not just convenient, but genuinely powerful for writers. It gives you control and flexibility. You can compare the same prompt across models, see which tone or structure fits your brand better, and then decide what to keep as your main writing setup.
Strength:
- Multi-model access. You can switch between top models instantly — Claude for fiction, Gemini for essays, DeepSeek or Mistral for open-source drafts — all in one chat.
- Real-time comparison. Perfect for testing the same prompt across different LLMs. You can see tone differences and depth instantly, which helps when you want a certain “vibe” in your writing.
- Choice and flexibility. You can route prompts automatically. For example, SEO briefs go to Gemini, story outlines to Claude, and blog updates to Mistral.
- Early access to new models. OpenRouter usually adds the latest releases fast, often before they reach other platforms.
- Transparent pricing. You can see how much each model costs before you use it, and plan your workflow accordingly.
- One account, many voices. You can test ideas across models, compare results, and even blend styles by refining outputs from multiple engines.
- Reliable logging. Every prompt and response stays recorded in your dashboard, making it easier to analyze and compare your experiments later.
- Perfect for teams. If you manage a writing team or content studio, OpenRouter helps standardize tests — everyone can use the same prompt structure and compare outcomes easily.
Limitations:
- It’s not a model itself. The quality of your output still depends on which LLM you choose inside OpenRouter. The platform won’t “improve” bad prompts.
- Different guardrails per model. Some are heavily moderated (like Claude), while others are freer (like Grok). You’ll notice the difference in tone when testing.
- Varying latency. Each model has its own response time and server load. Some can feel fast, others may stall depending on demand.
- Small compatibility quirks. Formatting or output style may differ slightly between models, which means you’ll still need to adjust prompts here and there.
- Costs can add up. Running the same test across multiple models burns tokens quickly if you’re not watching usage.
- Data policy depends on the model. While OpenRouter centralizes access, your data is still handled by the individual model providers. Always check their terms.
Now your turn to choose the tool that meets your requirements !

Free Prompts and Ebook to Humanize Your Text
Download Now
Buchert Jean-marc
Confirmed AI content process expert. Through his methods, he has helped his clients generate LLM-based content that fit their editorial standards and audiences expectations.
All Posts