Sommaire
- Pourquoi envisager des alternatives à ChatGPT ?
- 1) La rédaction créative de ChatGPT est limitée
- 2) Une fenêtre de contexte restreinte
- 3) Ouverture, coût et contrôle (surtout pour les équipes)
- Les meilleures alternatives à ChatGPT parmi les outils de rédaction
- 1. Claude (Sonnet 4.5)
- 2. Gemini (2.5 Pro)
- 3. DeepSeek (open-source)
- 4. Grok (xAI)
- 5. Mistral (open-source, UE)
- 6. OpenRouter
Les dernières versions de ChatGPT sont devenus de plus en plus efficaces, mais aussi moins susceptibles de vous surprendre.
C’est pourquoi, en 2025, de plus en plus de rédacteurs explorent des alternatives.
Dans cet article, nous allons passer en revue les meilleures alternatives à ChatGPT pour les rédacteurs en 2025.
Pourquoi envisager des alternatives à ChatGPT ?
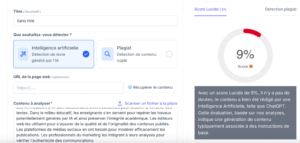
Si vous comptez sur l’IA pour rédiger des articles, des briefs ou des histoires, vous avez probablement remarqué quelque chose : aucun modèle n’est le meilleur en tout. Et ChatGPT ne fait pas exception à la règle.
1) La rédaction créative de ChatGPT est limitée
L’une des critiques les plus vives à l’encontre de ChatGPT, et en particulier de la dernière version (GPT-5), concerne la qualité des histoires et de la narration. Les rédacteurs soulignent des intrigues incohérentes, des métaphores étranges et des échecs logiques, même en utilisant des prompts avancés.
Les résultats de l’arène publique des LLM le confirment : sur des millions de votes participatifs, ChatGPT5, la dernière version, est moins bien classée que d’autres modèles de pointe à cet égard (Claude & Gemini) et même moins bien que les versions antérieures de ChatGPT (4o et 4.5). Cela ne signifie pas que ChatGPT est « mauvais », mais que vos chances d’obtenir le ton que vous souhaitez du premier coup sont peut-être plus élevées avec un modèle différent pour certains genres.
2) Une fenêtre de contexte restreinte
Lorsque vous rédigez de longs briefs, des revues de littérature ou des documents politiques, vous avez besoin d’un modèle capable de garder beaucoup de matériel source en mémoire de travail et de maintenir la cohérence des arguments sur des dizaines de pages. Le nouveau niveau « Thinking » de ChatGPT relève le plafond, mais il reste limité.
Deux problèmes apparaissent en pratique :
- Dérive des citations. Même avec une grande fenêtre, les LLM peuvent halluciner ou brouiller les sources lorsqu’ils résument de nombreux documents à la fois ; un long contexte ne garantit pas à lui seul un ancrage fidèle.
- Compression du contexte. Vous coupez les citations pour qu’elles rentrent, vous perdez des nuances, et le modèle oublie les contraintes initiales.
3) Ouverture, coût et contrôle (surtout pour les équipes)
Deux questions opérationnelles importent autant que la qualité brute du modèle : Où vivent nos données ? Jusqu’où pouvons-nous personnaliser ?
Rétention des données & confidentialité.
- Les pages entreprise d’OpenAI indiquent que les administrateurs de l’espace de travail contrôlent la rétention ; les discussions supprimées sont généralement purgées sous 30 jours, sauf en cas d’obligation légale. En 2025, un tribunal américain a ordonné à OpenAI de conserver les discussions des utilisateurs pour l’affaire du NYT (les niveaux grand public sont affectés ; les API Entreprise/Éducation et zéro-rétention sont exceptées), ce qui rappelle que la politique peut changer en cas de litige.
- Les clients API peuvent activer la Rétention Zéro Donnée (Zero Data Retention) ; OpenAI affirme que les journaux API sont supprimés après 30 jours en l’absence d’exigences légales. Certains partenaires cloud offrent des options de stockage régional ou de résidence des données.
Personnalisation & fine-tuning.
OpenAI prend en charge le fine-tuning sur certains modèles (par ex. GPT-4o et les minis). C’est bien pour le ton, le format et la conformité au domaine, mais vous ne pouvez toujours pas auto-héberger ChatGPT ou l’entraîner de zéro ; la personnalisation vit à l’intérieur de leur plateforme (ou Azure).
Pour les flux de travail très réglementés, cela signifie que vous échangez le contrôle total contre la commodité gérée : des résultats plus rapides, moins d’infrastructure, et moins de souveraineté architecturale sur les mises à jour ou le routage.
Les meilleures alternatives à ChatGPT parmi les outils de rédaction
Avec un nombre croissant d’outils d’IA disponibles pour la création de contenu, il existe de nombreuses alternatives aux capacités de rédaction de ChatGPT. Voici un classement des substituts les plus prometteurs :
1. Claude (Sonnet 4.5)

Classement :
Claude a toujours été le modèle des écrivains. Dès ses premières itérations, il portait cette étincelle — une sensibilité littéraire distinctive, un goût pour le rythme et une intelligence émotionnelle discrète que la plupart des modèles n’ont jamais maîtrisée. Après une brève baisse de créativité à l’ère de Claude 3, Claude Sonnet 4.5 sonne comme un retour en grande forme. Sur la plupart des classements créatifs, il se situe désormais tout en haut pour la fiction, le dialogue et la poésie.
D’après ce que j’ai vu sur des centaines de prompts — nouvelles, essais et sonnets shakespeariens — Claude 4.5 Sonnet est facilement l’un des meilleurs partenaires d’écriture IA pour quiconque recherche l’imagination et l’authenticité.
Points forts :
- Un flux narratif naturel. Claude écrit avec du rythme et une dynamique. Sa fiction semble structurée mais vivante — les personnages bougent, les scènes respirent et la tension monte naturellement.
- Des dialogues au rythme authentique. Les conversations semblent crédibles. Les personnages s’interrompent, hésitent et réagissent — un détail que la plupart des modèles ratent encore.
- Maîtrise poétique. Quand vous lui demandez des vers, il ne se contente pas de rimer — il donne du sens. Ses sonnets semblent intentionnels, souvent avec des tournants émotionnels qui les font paraître écrits par un humain.
- Adaptation de la voix. Donnez à Claude deux ou trois paragraphes de votre propre texte, et il reflète votre cadence, la longueur de vos phrases et votre diction avec une précision impressionnante. Il saisit le ton plus rapidement que la plupart des LLM.
- Imagerie inventive. Claude évite systématiquement les analogies éculées. Il va chercher de petites images concrètes qui ancrent l’émotion — un écran de téléphone qui s’allume, une lettre à moitié pliée, un verre brisé sur un bureau.
- Équilibre entre logique et art. Le mode « réflexion » (thinking) l’aide à maintenir simultanément la cohérence narrative et le rythme émotionnel — un mélange rare.
- Excellent pour les essais et l’écriture réflexive. Les textes personnels, d’opinion ou de marque sortent plus nuancés qu’avec d’autres modèles ; il comprend le sous-texte et l’implicite.
Limites :
- Intensif en ressources. C’est un grand modèle ; les requêtes lourdes en contexte peuvent prendre plus de temps et coûter plus de tokens que des alternatives plus légères.
- La profondeur SEO et technique peut être légère. Dans les guides structurés ou les tâches denses en mots-clés, il survole parfois les détails. Vous aurez besoin d’un plan clair ou de prompts de suivi pour forcer la spécificité.
- Ton trop poli. La prose peut sembler trop lisse ou formelle si vous visez une texture brute et conversationnelle. Vous devrez peut-être casser des phrases, ajouter des fragments ou raccourcir les transitions.
- Garde-fous sur les sujets sensibles. Les filtres de sécurité d’Anthropic peuvent couper les formulations plus controversées ou expérimentales. Ne vous attendez pas à ce que Claude explore l’ironie, l’humour noir ou les positions politiques tranchées.
- Dérive occasionnelle du rythme. Dans les longues histoires, il résout parfois les conflits trop proprement ou coupe la tension trop tôt. Lui donner une direction explicite étape par étape aide à maintenir le suspense.
- Moins de précision analytique dans l’écriture basée sur la recherche. Comparé à Gemini 2.5 Pro ou ChatGPT 5, Claude peut privilégier le style à l’exhaustivité factuelle.
2. Gemini (2.5 Pro)
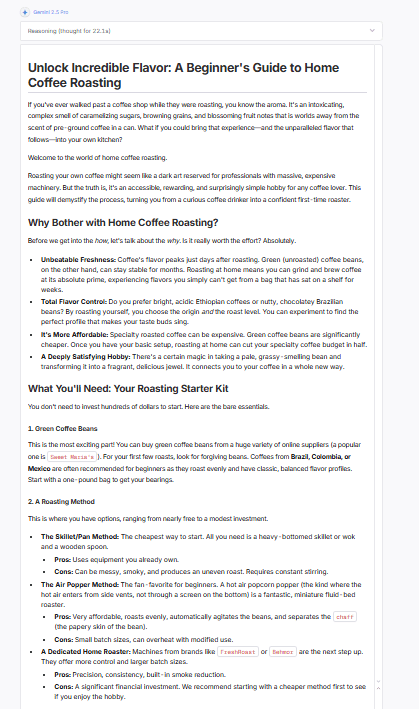
Classement :
Si Claude est le modèle de l’écrivain, Gemini 2.5 Pro est celui du chercheur. Il domine actuellement la plupart des classements publics, y compris les arènes de texte et de raisonnement de LMSYS, et se classe parmi les meilleurs LLM globaux tous usages confondus. L’avantage de Gemini réside dans l’échelle et la structure : sa fenêtre de contexte massive, sa précision factuelle et son raisonnement en plusieurs étapes le rendent idéal pour l’écriture non-fictionnelle, les flux de travail SEO et le contenu basé sur la recherche.
Points forts :
- Précision factuelle inégalée. Gemini se vérifie lui-même en cours de génération. Vous pouvez sentir qu’il croise les logiques au lieu de faire de l’association libre. La cohérence factuelle dans les essais et les guides techniques est excellente.
- Structure détaillée, étape par étape. Lorsque vous donnez à Gemini une tâche basée sur un processus (comme votre exemple de torréfaction de café), il la décompose en sections ordonnées et étiquetées avec des transitions nettes : méthode → équipement → processus → résultat. Vous avez rarement besoin de réorganiser ses brouillons.
- Fenêtre de contexte massive. Il gère confortablement les documents longs — parfait pour les audits de contenu, les revues de littérature et les projets de recherche de la taille d’un livre. Vous pouvez lui donner des PDF complets ou des notes de plusieurs pages et il maintient la cohérence.
- Puissant modèle de raisonnement. Gemini 2.5 Pro n’est pas seulement un modèle de texte ; c’est un modèle de raisonnement. Il suit les chaînes d’arguments, anticipe les contre-points et soutient les affirmations avec des preuves plus naturellement que la plupart des LLM.
- Fort en rédaction SEO. Il excelle dans les décompositions hiérarchiques : H2, listes à puces, encadrés et résumés qui s’alignent réellement sur l’intention de recherche. Il comprend ce que signifie « répondre à la requête ».
- Ton et diction équilibrés. Gemini écrit clairement, sans fioritures excessives. Il est idéal pour les blogs professionnels, les livres blancs et les explications marketing qui nécessitent de l’autorité sans emphase.
- Capacité de citation robuste. Lorsqu’on le lui demande correctement (« ajouter des sources numérotées ou des citations »), il ancre ses affirmations dans des références plausibles et un formatage cohérent — un grand atout pour les revues de littérature ou les articles de recherche.
- Stabilité sur le long format. Les essais de plus de 1 500 mots gardent une cohérence interne. Il suit la thèse, les sections et les preuves tout au long du texte, avec moins de lacunes logiques que les modèles comparables.
Limites :
- Bizarreries de formatage. Abuse parfois des listes à puces imbriquées ou des listes numérotées, donnant au brouillon l’apparence d’une documentation plutôt que d’une prose.
- Moins de chaleur créative. Gemini peut écrire de la fiction, mais ses histoires semblent calculées. Vous obtenez de la logique, pas de la spontanéité. Le dialogue peut sembler fonctionnel plutôt qu’émotionnel. Pour la voix narrative, Claude l’emporte toujours.
- Rigidité occasionnelle. Parce qu’il s’appuie sur la structure, Gemini ignore parfois le jeu stylistique. Vous devrez peut-être lui demander explicitement de varier le rythme, de raccourcir les lignes ou d’ajouter un langage sensoriel.
- Le formatage avant le style. Il a tendance à produire des sections propres mais stéréotypées (listes, titres, sous-étapes). C’est génial pour le SEO, moins pour les essais qui ont besoin de mouvement lyrique ou de métaphores.
- Ton sec dans les textes créatifs. Le texte marketing peut sembler trop corporatif, à moins que vous n’injectiez des directives de ton (« rendez cela conversationnel », « ajoutez une touche d’humour amical »).
- Réponse lente sur les grosses entrées. Sa chaîne de raisonnement augmente la latence. Avec des prompts très longs, il peut faire une pause en cours de génération ou prendre sensiblement plus de temps que ChatGPT ou Claude.
- Limites en fiction. Il peut construire une logique d’histoire solide mais manque d’étincelle — les métaphores restent superficielles et les arcs émotionnels semblent conçus plutôt que ressentis.
3. DeepSeek (open-source)
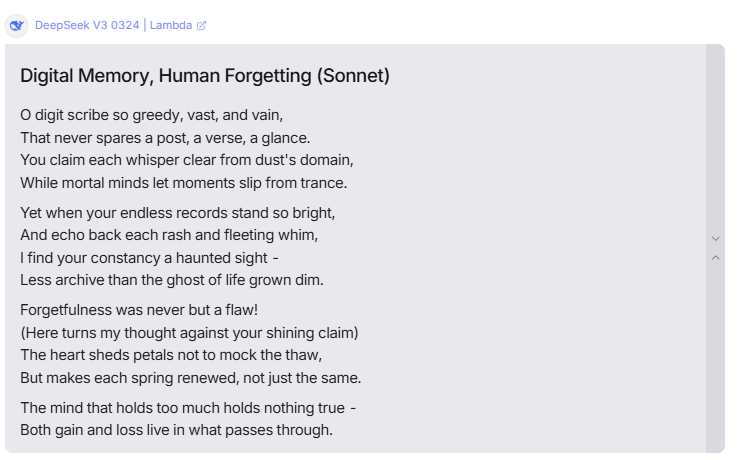
Classement :
En 2025, DeepSeek a fait un vrai buzz : un modèle open-source chinois de premier plan que la plupart des rédacteurs pouvaient essayer sans se ruiner. Pendant des mois, il s’est maintenu au sommet ou presque des classements open-source. Ce n’est pas toujours le meilleur sur un axe donné, mais à travers les échantillons, il fournit des brouillons fiables et utiles — et vous bénéficiez des libertés de l’open-source que les modèles fermés n’offrent pas.
Points forts :
- Ouvert et flexible. Vous pouvez exécuter DeepSeek localement, sur un serveur ou derrière votre propre API. Cela signifie confidentialité, contrôle et coûts prévisibles.
- Facile à fine-tuner. Si la voix de votre marque a besoin d’être plus tranchante ou d’un jargon de domaine, vous pouvez l’ajuster sur une poignée d’échantillons maison et verrouiller le ton plus rapidement qu’avec les modèles fermés.
- Instincts créatifs. Sur les prompts de fiction, DeepSeek montre un bon sens de l’histoire : un arc clair, des images spécifiques, une chute. Les tests de sonnets étaient propres — la rime tenait, le tournant fonctionnait.
- Résultat équilibré. Les essais, guides et articles de blog sortent structurés et lisibles. Il ne vous inondera pas de remplissage et reste plus souvent dans le brief que la moyenne.
- Efficacité des coûts. Pour les équipes qui produisent beaucoup de brouillons, les coûts des tokens plus l’hébergement local peuvent battre les prix propriétaires de loin.
- Moduler les garde-fous. Selon le checkpoint que vous choisissez, vous pouvez desserrer ou resserrer les contraintes de style. C’est utile si la voix de votre marque penche vers le franc-parler ou l’originalité.
- Support solide de l’écosystème. Vous trouverez des adaptateurs, des serveurs d’inférence et des routeurs de prompts prêts à l’emploi. Moins de code de liaison. Configuration plus rapide.
- Bon avec les plans. Lorsque vous lui donnez des objectifs de section clairs, il respecte les étapes et garde les paragraphes concis.
Limites :
- Pas le meilleur absolu dans un domaine précis. En confrontation directe, Qwen ou Claude peuvent le battre sur la créativité pure ; Gemini peut le battre sur le raisonnement à long contexte.
- Lignes plates occasionnelles. Sans guide de style, DeepSeek peut glisser vers une formulation banale. Vous voudrez un prompt de guide de style pour garder une diction vive.
- Moins de métaphores « wow » d’emblée. Il construit des scènes solides, mais les lignes surprenantes sont moins fréquentes qu’avec Claude. Ajoutez une règle « une image fraîche par paragraphe » pour aider.
- Surcharge de configuration. Le déploiement local signifie que vous possédez la stack : choix du GPU, mises à jour, monitoring. Génial pour le contrôle, mais cela reste de l’administration système.
- Citations et sourcing. Il peut bien ébaucher une recherche, mais il a besoin d’instructions explicites pour ancrer les affirmations avec des sources et des liens.
- Variance des garde-fous. Différents checkpoints communautaires ont une sécurité et un ton différents. Vous devez choisir et tester le bon pour la production.
4. Grok (xAI)

Classement :
Grok est dans une catégorie à part. Là où d’autres modèles visent un poli sécurisé, Grok 4 penche vers le curieux, le rapide et un peu l’indiscipliné — dans le bon sens du terme. Il puise dans l’écosystème X pour un contexte à jour et fonctionne avec des garde-fous stylistiques plus légers, de sorte que la voix atterrit souvent avec plus de mordant. Dans les prompts de fiction, il prend des risques (nouveaux décors, métaphores plus étranges). Dans les essais, c’est celui qui est le plus susceptible de choisir un camp et de l’argumenter. Pour le SEO, il est correct — pas le plus exhaustif — mais il cernera l’intention et structurera une page que vous pourrez publier après une passe rapide.
Points forts :
- Ton audacieux et affirmé. Grok n’est pas timide. Les essais ne se contentent pas de résumer ; ils affirment une position, contrastent les points de vue et apportent des références que vous ne voyez pas ailleurs.
- Raisonnement + personnalité. Les derniers modèles Grok ajoutent un véritable contrôle du fil de la pensée. Vous sentez la progression : prémisse → contrepoint → synthèse. Toujours percutant.
- Prise de risque créative. Dans les nouvelles, il change de lieu et de point de vue plus librement, introduit des objets inattendus et ne se rabat pas sur les trois mêmes métaphores. Le coup du « Miami au lieu de N’importe où, USA » est typique — et ça marche.
- Instincts d’actualité. Avec un contexte informé par X, il est enclin à tisser des débats actuels, des personnalités publiques ou des exemples frais sans sonner comme une machine à résumer.
- Bon pour les cadres à contre-courant. Demandez un « steelman du côté perdant », et Grok s’exécutera. C’est utile pour les articles de réflexion, les « hot takes » et les éditoriaux qui ont besoin d’un point de vue.
- Transitions vives. Moins de « De plus/En outre » et des pivots plus naturels. Les paragraphes semblent conversationnels, pas corporatifs.
- Amusant pour les prompts avec une « vibe ». Si vous lui donnez une indication de style (« essai noir », « intro gonzo », « humour pince-sans-rire »), Grok suit le brief avec moins d’excuses.
Limites :
- La profondeur SEO est moyenne. Il ébauchera et placera les titres, mais les sous-étapes détaillées, les comparaisons outil par outil et les spécificités au niveau tableau nécessitent souvent une deuxième passe ou un modèle axé sur la recherche.
- L’audace avant la prudence. Ce penchant affirmé peut pousser le ton au-delà de certaines lignes directrices de marque. Si votre voix est conservatrice, vous devrez arrondir les angles.
- Discipline de citation. Grok puisera dans des idées extérieures, mais il a besoin d’instructions explicites pour formater et ancrer les affirmations (« ajouter des citations numérotées », « lier des études, pas des gros titres »).
- Contrôle lyrique incohérent. Il peut être brillant un paragraphe et un peu chaotique le suivant. Pour la poésie ou une métrique serrée, Claude est plus stable.
- Risque de dérive thématique. Avec ses instincts d’actualité, il court parfois après l’aparté intéressant au lieu du brief. Épinglez-le à un plan de section.
- Variance de sécurité vs besoins de la marque. Des garde-fous stylistiques plus légers signifient que vous devez appliquer vos propres lignes rouges (ton, sujets, formulations taboues) dans le prompt.
5. Mistral (open-source, UE)

Classement :
Mistral est rarement en tête des classements mondiaux ; il se situe généralement en milieu de peloton (pensez à la 10e-20e place selon le benchmark et le checkpoint). Mais il gagne sa place ici pour une raison simple : il est open-source, européen et fiable. Si vous vous souciez de la résidence des données, des contrôles de confidentialité ou d’éviter les fournisseurs fermés américains et chinois, Mistral est le choix pratique.
Dans les tâches d’écriture, il est stable, sinon spectaculaire. Le résultat peut sembler un peu formaté par endroits ; la fiction n’est pas aussi subtile que celle de Claude ou aussi audacieuse que celle de Grok. Pour le SEO et la non-fiction simple, cependant, il fait le travail avec une structure propre et sans chichis.
Points forts :
- Positionnement européen sur les données. Si vous avez besoin d’un hébergement européen et de garanties de conformité plus strictes, Mistral est le « oui » le plus facile. Moins d’obstacles politiques pour les équipes avec du matériel sensible.
- Contrôle open-source. Exécutez-le localement ou sur votre cloud, ajustez les garde-fous et décidez comment vos données circulent. Pas de surprises de boîte noire.
- Structure prévisible. Pour les briefs, les FAQ et le contenu « comment faire » de base, Mistral donne des titres nets, des paragraphes courts et des étapes logiques sans sur-expliquer.
- Peu de friction pour les ébauches SEO. Les décompositions H2/H3, les puces et les listes de contrôle sortent propres. Avec un prompt rapide pour les sous-étapes, vous obtenez rapidement des plans publiables.
- Adapté au fine-tuning. Un petit ensemble de données internes (échantillons de voix, règles de marque) va loin. Vous pouvez verrouiller la diction et la cadence mieux qu’avec de nombreux modèles fermés.
- Coût et latence. Les checkpoints légers fonctionnent rapidement et à bas prix. Idéal pour l’échelle lorsque vous expédiez beaucoup de listicles, de pages de fonctionnalités ou de documents d’aide.
- « Style maison » stable. Moins de dérive entre les sections. Si vous avez besoin d’un ton cohérent sur de nombreuses pages, les sorties conservatrices de Mistral aident.
- Écosystème d’outils. Fort support à travers les serveurs d’inférence ouverts, les stacks RAG et les outils d’orchestration. Facile à intégrer dans les pipelines existants.
Limites :
- Pas un modèle de raisonnement (par défaut). Sur les arguments longs en plusieurs étapes ou les revues de littérature, il peut manquer la nuance ou aplatir les contrepoints. Vous aurez besoin de prompts plus stricts ou de récupération (retrieval) pour garder de la profondeur.
- La fiction semble rigide. Les scènes fonctionnent, mais la prose peut sembler sage. Moins d’images surprenantes, moins de sous-texte dans les dialogues. Pour les histoires ou les textes lyriques, Claude l’emporte toujours.
- Cadence stéréotypée. Sans guide de style, il penche vers les phrases équilibrées et les transitions soignées. Vous voudrez peut-être injecter du rythme (fragments, temps courts) en post-production.
- Détails SEO superficiels. Il ébauche bien, mais les comparaisons d’outils, les statistiques et les pièges ont besoin d’être poussés. Demandez explicitement des « métriques, fourchettes et exemples » par sous-section.
- Citations sur demande uniquement. Il n’ancrera pas les affirmations à moins que vous ne le demandiez. Ajoutez une règle de sourcing dans chaque brief.
- La dispersion des modèles compte. Différents checkpoints Mistral varient en capacité. Vous devrez tester et standardiser celui que vous mettez en production.
6. OpenRouter
Classement :
OpenRouter n’est pas un modèle comme les autres de ce classement. C’est en fait une plateforme qui vous connecte à tous les principaux LLM en un seul endroit. Vous pouvez tester Claude, Gemini, DeepSeek, Grok, Mistral, Qwen, et d’autres côte à côte sans ouvrir de nouveaux comptes ou jongler avec différentes API.
Cela rend OpenRouter non seulement pratique, mais véritablement puissant pour les rédacteurs. Il vous donne le contrôle et la flexibilité. Vous pouvez comparer le même prompt sur plusieurs modèles, voir quel ton ou quelle structure correspond le mieux à votre marque, puis décider quoi garder comme configuration d’écriture principale.
Points forts :
- Accès multi-modèles. Vous pouvez basculer instantanément entre les meilleurs modèles — Claude pour la fiction, Gemini pour les essais, DeepSeek ou Mistral pour les brouillons open-source — le tout dans un seul chat.
- Comparaison en temps réel. Parfait pour tester le même prompt sur différents LLM. Vous pouvez voir instantanément les différences de ton et de profondeur, ce qui aide lorsque vous voulez une certaine « vibe » dans votre écriture.
- Choix et flexibilité. Vous pouvez router les prompts automatiquement. Par exemple, les briefs SEO vont à Gemini, les plans d’histoire à Claude, et les mises à jour de blog à Mistral.
- Accès anticipé aux nouveaux modèles. OpenRouter ajoute généralement les dernières versions rapidement, often avant qu’elles n’atteignent d’autres plateformes.
- Tarification transparente. Vous pouvez voir combien coûte chaque modèle avant de l’utiliser, et planifier votre flux de travail en conséquence.
- Un compte, plusieurs voix. Vous pouvez tester des idées sur plusieurs modèles, comparer les résultats, et même mélanger les styles en affinant les sorties de plusieurs moteurs.
- Journalisation fiable. Chaque prompt et réponse reste enregistré dans votre tableau de bord, ce qui facilite l’analyse et la comparaison de vos expériences plus tard.
- Parfait pour les équipes. Si vous gérez une équipe de rédaction ou un studio de contenu, OpenRouter aide à standardiser les tests — tout le monde peut utiliser la même structure de prompt et comparer les résultats facilement.
Limites :
- Ce n’est pas un modèle en soi. La qualité de votre sortie dépend toujours du LLM que vous choisissez à l’intérieur d’OpenRouter. La plateforme n’améliorera pas les mauvais prompts.
- Garde-fous différents par modèle. Certains sont fortement modérés (comme Claude), tandis que d’autres sont plus libres (comme Grok). Vous remarquerez la différence de ton lors des tests.
- Latence variable. Chaque modèle a son propre temps de réponse et sa propre charge de serveur. Certains peuvent sembler rapides, d’autres peuvent caler en fonction de la demande.
- Petites bizarreries de compatibilité. Le formatage ou le style de sortie peut différer légèrement entre les modèles, ce qui signifie que vous devrez toujours ajuster les prompts ici et là.
- Les coûts peuvent s’additionner. Exécuter le même test sur plusieurs modèles brûle des tokens rapidement si vous ne surveillez pas l’utilisation.
- La politique de données dépend du modèle. Bien qu’OpenRouter centralise l’accès, vos données sont toujours gérées par les fournisseurs de modèles individuels. Vérifiez toujours leurs conditions.
À vous de choisir l’outil qui répond à vos exigences !

Prompts gratuits et Ebook pour humaniser votre texte
Télécharger Maintenant
Buchert Jean-marc
Expert confirmé en processus de contenu IA. Par ses méthodes, il a aidé ses clients à générer du contenu de qualité qui correspond à leurs exigences éditoriales et aux attentes de leur public.
Tous les Articles