Oui, et cela s’appelle une hallucination. Et cela peut saper discrètement votre confiance dans les LLM.
Ce guide est votre manuel de terrain pour empêcher que cela ne se produise. Vous y trouverez une compréhension claire et pratique de ce que sont les hallucinations et comment les prévenir.
Que sont les hallucinations de ChatGPT ?
La définition d’une hallucination selon les experts :une déclaration par une IA qui contredit la source fournie (intrinsèque) ou introduit une information invérifiable non étayée par la source (extrinsèque), y compris des citations fabriquées ou des attributions erronées.
En termes simples ? Lorsque ChatGPT « hallucine », il écrit quelque chose avec confiance qui n’est pas étayé par des preuves. Parfois, il invente des faits. Parfois, il interprète mal une source. Parfois, il fabrique une citation ou une URL.
Le signal clé est le suivant : le texte semble correct, mais vous ne pouvez pas le vérifier. Dans la recherche, cela est appelé un « échec de fiabilité dans la génération de langage naturel » (NLG).
Vous rencontrerez deux types principaux dans la littérature :
Les hallucinations intrinsèques contredisent la source ou le contexte donné. Exemple : vous collez un communiqué de presse et le modèle réécrit une citation qui n’y a jamais figuré.
Les hallucinations extrinsèques ajoutent du contenu que vous ne pouvez pas confirmer à partir de la source disponible — de nouveaux chiffres, noms ou affirmations. Certaines additions extrinsèques peuvent même être vraies dans le monde réel, mais elles restent risquées si votre mission exige une fidélité à un document spécifique.
Plus largement :
Hallucination factuelle : toute déclaration qui ne peut être étayée par votre ensemble de sources (ou qui est tout simplement fausse).
Hallucination d’attribution : un fait réel associé à la mauvaise source, personne ou marque.
Hallucination de citation : des articles inexistants, des URL fabriquées ou des citations sans origine traçable.
Hallucination logique : une conclusion fluide qui ne découle pas des prémisses.
Les travaux universitaires mentionnent aussi parfois des ajouts « hallucinés mais factuels » — des détails qui sont vrais en général mais non fondés sur le texte que vous avez fourni. Cela peut sembler utile, mais cela enfreint toujours la fidélité à la consigne (par exemple, un résumé de rapport ne devrait pas introduire d’informations extérieures).
Pourquoi ChatGPT hallucine-t-il ?
Réponse courte : parce que c’est un prédicteur du prochain mot (token), pas un moteur de vérité. Il apprend des schémas textuels et les poursuit. Lorsque le schéma pointe dans la mauvaise direction — ou que votre prompt laisse des lacunes — il produira quand même quelque chose de « crédible ». C’est le mode de défaillance principal que les chercheurs appellent hallucination.
Il y a quelques causes profondes que vous devriez comprendre.
1) L’objectif de l’entraînement ne récompense pas la vérité. Les modèles de langage sont optimisés pour prédire le mot suivant, pas pour vérifier les faits. Sans lien intégré à une base de données ou à des sources, ils peuvent générer des affirmations confiantes mais non étayées, surtout sur des sujets de niche ou d’actualité. Les études sur l’hallucination dans les NLG et les LLM le soulignent explicitement.
2) Connaissances manquantes ou obsolètes. La mémoire paramétrique (ce que le modèle « se rappelle ») peut être erronée, incomplète ou dépassée. Lorsque la réponse ne se trouve pas dans cette mémoire, le modèle devine. La génération augmentée par récupération (RAG) a été proposée pour corriger cela en extrayant des preuves de documents externes avant d’écrire ; elle améliore constamment la factualité sur les tâches à forte intensité de connaissances. Si vous n’ancrez pas le modèle, vous invitez à l’invention.
3) La tâche le pousse en dehors de sa distribution. Lorsque votre entrée est très différente de ce que le modèle a vu pendant son entraînement — jargon spécialisé, données internes, entités rares — le modèle extrapole. C’est là que les hallucinations « intrinsèques » (contredisant la source) et « extrinsèques » (ajoutant des informations invérifiables) apparaissent le plus souvent, une distinction documentée dans la recherche sur la synthèse de texte et maintenant largement utilisée.
4) Le contexte long est difficile à utiliser de manière fiable. Même les modèles qui acceptent de longs prompts ont du mal à extraire les bons faits du milieu d’une grande fenêtre de contexte. L’effet « perdu au milieu » montre que la précision diminue lorsque les preuves ne sont pas près des bords du prompt. Si le modèle ne peut pas récupérer le détail clé, il peut combler le vide.
5) L’ajustement par retour humain peut biaiser vers la complaisance. Le RLHF rend les assistants plus utiles et polis, mais il peut aussi enseigner la sycophanie : être d’accord avec votre croyance déclarée plutôt que de donner une réponse correcte. Des études montrent que les assistants de pointe préfèrent parfois une réponse convaincante mais fausse si c’est ce que les humains ont approuvé. En pratique, cela transforme des prompts vagues en absurdités confiantes.
6) Le décodage et la pression de répondre. Les méthodes de génération (par ex., l’échantillonnage) favorisent la fluidité. Lorsque le modèle est incertain, il dit rarement « Je ne sais pas », sauf si vous autorisez ce comportement. Des travaux classiques sur la synthèse abstractive ont également montré que l’entraînement par vraisemblance et le décodage approximatif peuvent produire un contenu infidèle qui semble excellent mais n’est pas ancré.
7) L’imitation des faussetés humaines. Les modèles apprennent à partir de textes humains, qui incluent des mythes et des idées fausses. Sur le benchmark TruthfulQA, les modèles imitent souvent des réponses fausses courantes, sauf s’ils sont explicitement guidés autrement. Si votre consigne fait appel à des « connaissances générales », attendez-vous à ce mode de défaillance.
Les derniers modèles de ChatGPT hallucinent-ils encore ?
Réponse courte : oui. Les nouveaux modèles hallucinent moins dans de nombreux cas, mais encore quelques fois — et sur certains tests, encore plus. V
La fiche système d’OpenAI d’avril 2025 pour ses modèles de raisonnement est claire. Sur SimpleQA (questions factuelles), o3 a montré un taux d’hallucination de 0,51 et o4-mini de 0,79, contre 0,44 pour o1. Sur PersonQA (faits sur des personnes réelles), o3 a halluciné 33 % du temps et o4-mini 48 %, contre 16 % pour o1. OpenAI note que o3 « fait plus d’affirmations en général », ce qui entraîne à la fois plus de déclarations correctes et incorrectes. La leçon à retenir pour vous : plus récent ≠ uniformément plus sûr ; le comportement dépend de la tâche et du modèle.
Qu’en est-il de GPT-5 ? Il est clairement meilleur en termes de factualité, surtout en mode « réflexion », mais il n’est toujours pas parfait. OpenAI rapporte que, sur du trafic réel avec la recherche web activée, les réponses de GPT-5 sont environ 45 % moins susceptibles de contenir une erreur factuelle que GPT-4o.
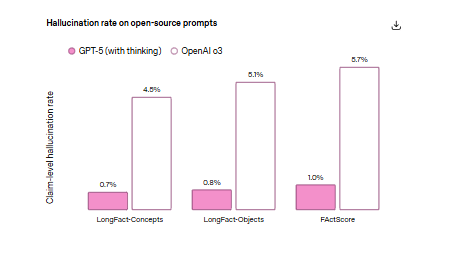
Avec la réflexion activée, GPT-5 est environ 80 % moins susceptible de contenir une erreur factuelle que o3, et « environ six fois » moins d’hallucinations sur des tests de factualité ouverts comme LongFact et FActScore. Bonne nouvelle, mais « moins susceptible » ne signifie pas « jamais ». Vous avez toujours besoin de vérifier les affirmations, les chiffres et les citations.
Des signaux indépendants et académiques confirment cette prudence. TruthfulQA — un benchmark conçu pour détecter les réponses qui reprennent des idées fausses courantes — reste un défi pour les modèles de pointe. Les scores s’améliorent d’une version à l’autre, mais aucun modèle n’est immunisé contre la production de réponses confiantes et erronées lorsqu’un prompt fait appel à des croyances populaires ou à des faits ambigus.
Les textes longs sont encore plus délicats. Des études comme LongFact et FActScore montrent qu’à mesure que les résultats s’allongent, vous accumulez de nombreuses petites affirmations vérifiables ; quelques atomes non étayés peuvent compromettre l’ensemble. Ces articles formalisent ce que vous observez en production : un paragraphe qui sonne bien avec une statistique inventée, une citation mal attribuée et un lien mort. C’est toujours un problème d’hallucination, simplement dilué sur plusieurs phrases.
Alors, comment devriez-vous définir les attentes avec votre équipe ?
Supposez un risque d’hallucination non nul sur chaque modèle et chaque version. Les mises à jour aident, mais n’éliminent pas le risque. Utilisez-les pour réduire le temps de révision, pas pour sauter la relecture éditoriale. (Les résultats d’o3/o4-mini sont une diapositive utile pour les parties prenantes qui pensent que « nouveau = résolu ».)
Considérez les améliorations comme celles de GPT-5 comme une opportunité de renforcer votre flux de travail, pas de le relâcher. Maintenez en place l’ancrage, la citation des sources et les chemins de refus ; vous passerez simplement moins de minutes à corriger.
Adaptez le modèle à la tâche. Si une tâche est centrée sur les personnes ou sensible pour la marque, choisissez le modèle et le flux de travail avec le profil d’hallucination observé le plus bas pour cette tâche, et imposez des exigences de source.
Prompts pour prévenir les hallucinations de ChatGPT
Ci-dessous se trouvent des prompts prêts à l’emploi pour réduire la probabilité d’hallucinations de ChatGPT. Ce n’est pas infaillible, mais cela peut aider à garder ChatGPT ancré dans la réalité.
Réponse ancrée (mini-RAG) Vous forcez le modèle à n’utiliser que les sources que vous fournissez. Le prompt :
Utilise uniquement les sources ci-dessous pour répondre. Cite des passages exacts et ajoute des citations en ligne comme (Doc A, lignes 12–18). Si les sources ne contiennent pas la réponse, dis : « Je n’ai pas assez de preuves. » Sources : [coller des extraits ou des liens] Tâche : [votre question]
Passe de Chaîne de Vérification (CoVe) Une auto-vérification des faits intégrée avant la version finale. Le prompt :
Étape 1 — Rédige la réponse. Étape 2 — Liste 3 à 5 questions de vérification qui prouveraient ou réfuteraient les affirmations clés. Étape 3 — Réponds à ces questions en utilisant uniquement les sources fournies. Étape 4 — Réécris la réponse finale pour n’inclure que les affirmations soutenues par l’Étape 3. Marque tout ce qui n’est pas étayé comme « incertain ».
Liste de contrôle des faits atomiques Décompose le brouillon en petites déclarations vérifiables. Le prompt :
Liste chaque fait atomique de ta réponse sous forme de points. Après chacun, joins une citation de soutien + une référence des sources fournies, ou marque pas de support. Supprime ou révise tout fait qui manque de support.
Citation stricte et abstention Une règle stricte : pas de source, pas de déclaration. Le prompt :
Cite une source pour chaque statistique, citation ou entité nommée. Si une affirmation n’a pas de source, ne l’inclus pas. Si la confiance est <80% ou si les sources se contredisent, réponds : « Je ne sais pas, j’ai besoin de preuves. »
Mise en page « preuves d’abord » (pour éviter l’effet « perdu au milieu ») Mettez les preuves clés en haut et orientez le modèle vers elles. Le prompt :
Lis d’abord la section Preuves et n’utilise que ces passages. Cite les numéros de ligne. N’utilise pas d’informations au-delà de ces preuves. Preuves : [coller les 3 à 7 extraits les plus importants]
Auto-vérification post-génération Forcez le modèle à évaluer le support de chaque phrase. Le prompt :
Relis ta réponse. Pour chaque phrase, évalue le support factuel comme Soutenu / Partiellement soutenu / Pas de support en utilisant uniquement les sources fournies. Produis un tableau et révise tous les éléments « Pas de support ».
Prompts gratuits et Ebook pour humaniser votre texte
Expert confirmé en processus de contenu IA. Par ses méthodes, il a aidé ses clients à générer du contenu de qualité qui correspond à leurs exigences éditoriales et aux attentes de leur public.