



Sommaire
- Que sont les détecteurs d’IA ?
- Sur quelles techniques algorithmiques les détecteurs d’IA reposent-ils
- Perplexité / Score de vraisemblance
- Burstiness / Variance de prévisibilité
- Extraction de caractéristiques stylométriques et linguistiques
- Watermarking / Signaux cachés
- Approches par ensembles, hybrides et méta-classifieurs
- Différences algorithmiques entre les modèles courants de détecteurs d’IA
- GPTZero : Le point de départ statistique + couches profondes
- Détecteur d’écriture IA de Turnitin : Hybride & Embarqué
- Originality AI : Classification holistique + Reconnaissance de formes
- Copyleaks : Méthodes hybrides + Explicabilité
- Les détecteurs d’IA sont-ils vraiment fiables ?
- Comment utiliser les détecteurs d’IA de manière responsable
Les détecteurs sont de plus en plus utilisés dans le monde éditorial & universitaire & marketing.
Le problème ? Les explications sur leur fonctionnement sont souvent soit vagues, soit surchargées de jargon.
Ce guide vous apporte cette clarté. Vous apprendrez ce que sont réellement les détecteurs d’IA et comment ils fonctionnent concrètement.
Que sont les détecteurs d’IA ?
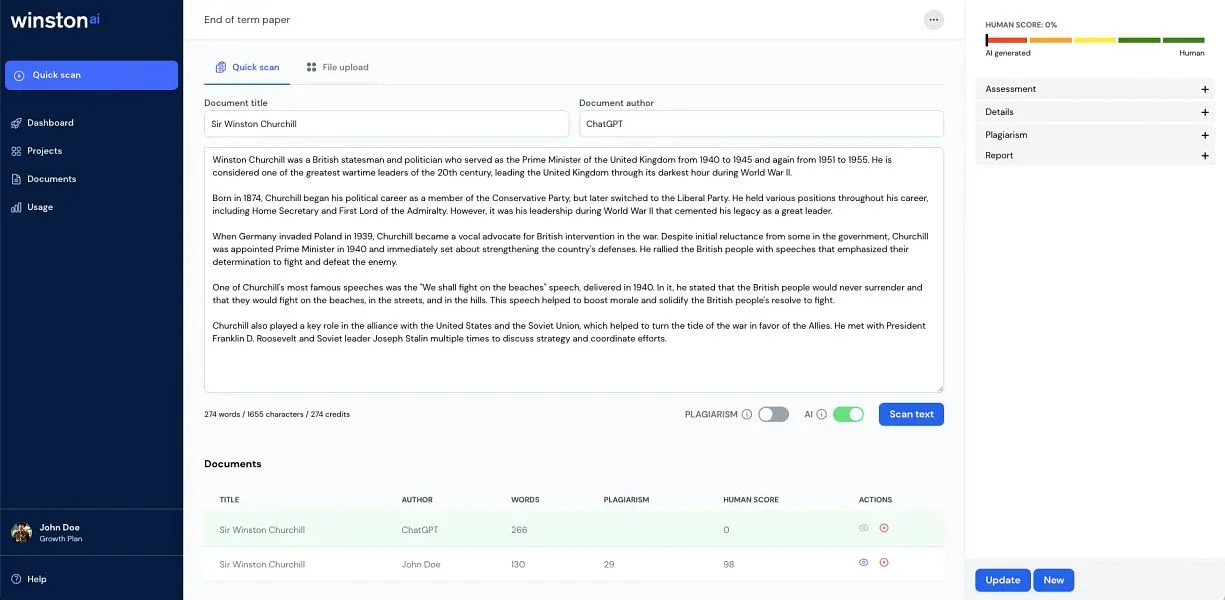
En termes simples, les détecteurs d’IA sont des outils conçus pour estimer si un texte donné a été généré (ou fortement assisté) par un modèle d’IA plutôt qu’entièrement rédigé par un humain.
Les développeurs de détecteurs d’IA partent du principe que le texte généré par l’IA laisse des empreintes statistiques. Habituellement, le résultat d’un LLM a tendance à être plus uniforme, moins variable ou plus « prévisible ».
C’est pourquoi de nombreux détecteurs examinent des mesures internes comme la perplexité (à quel point chaque choix de mot est surprenant) et la burstiness (variation de style entre les phrases).
Qui utilise les détecteurs d’IA ?
- Les milieux universitaires les utilisent souvent pour vérifier la triche ou l’utilisation excessive de l’IA dans les dissertations des étudiants.
- Les éditeurs, les rédacteurs en chef et les plateformes de contenu peuvent les utiliser pour faire respecter les normes de qualité, d’authenticité ou d’originalité.
- Les marques et les spécialistes du marketing peuvent les employer pour valider le fait que les créateurs de contenu ou les agences produisent un travail qui « sonne humain ».
Les détecteurs d’IA se présentent sous différentes formes :
- Outils web autonomes ou tableaux de bord — vous collez du texte ou téléversez un fichier et obtenez un score, un pourcentage ou une étiquette (par ex. GPTZero, Originality.ai).
- Détecteurs intégrés — embarqués dans des plateformes, des LMS (systèmes de gestion de l’apprentissage), des systèmes de gestion de contenu ou des outils éditoriaux.
- Systèmes hybrides ou d’ensemble — utilisent plusieurs techniques de détection ensemble (statistiques + classifieurs de caractéristiques + détection de watermarks).
- API / services — des outils que vous pouvez appeler par programmation dans vos pipelines de contenu, afin que chaque sortie générée puisse être scannée.
Sur quelles techniques algorithmiques les détecteurs d’IA reposent-ils
Les détecteurs d’IA s’appuient sur un ensemble spécifique de méthodes algorithmiques et statistiques pour évaluer votre écriture.
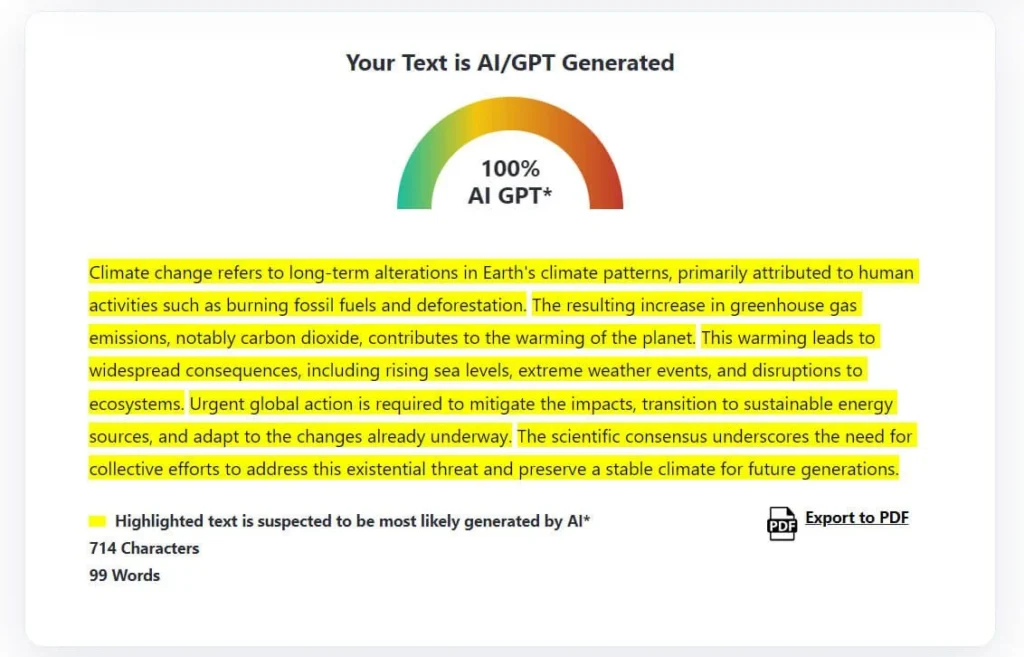
Perplexité / Score de vraisemblance
L’une des techniques de base de nombreux détecteurs est la perplexité (à quel point une séquence d’écriture est surprenante).
- Le détecteur (ou un modèle de substitution) calcule la probabilité pour chaque token compte tenu de son contexte. Il additionne ensuite la probabilité logarithmique négative sur l’ensemble des tokens (ou fait la moyenne sur les phrases) pour calculer un score. Une surprise moyenne plus faible → une perplexité plus faible.
- Un texte trop prévisible (c’est-à-dire qu’un modèle de langage le trouve facile à deviner) est souvent signalé comme étant plus « de type IA ».
- De nombreux détecteurs décomposent également les scores au niveau de la phrase. Ils mesurent la perplexité par phrase, puis en dérivent des statistiques (moyenne, variance) à travers le document.
- Certains détecteurs utilisent également la courbure négative de la log-vraisemblance comme mesure affinée : à quelle vitesse les vraisemblances changent lors de petites perturbations du texte. Cela peut aider à identifier les points sensibles où le modèle est trop confiant.
Burstiness / Variance de prévisibilité
Une seconde technique complète la perplexité : la burstiness — mesurant la variation existante dans un texte en termes de prévisibilité, de structure ou de complexité.
- Après avoir calculé la perplexité au niveau de la phrase ou du bloc, les détecteurs examinent la variance (par ex. écart-type, coefficient de variation). Si chaque phrase est à peu près également prévisible, la burstiness est faible — un signal d’alarme. Si certaines phrases sont plus prévisibles et d’autres plus surprenantes, cela signale un rythme plus humain.
- Outre la variation de probabilité, les détecteurs peuvent également rechercher des variations dans la longueur des phrases, la structure des propositions, la ponctuation, les changements syntaxiques ou les changements de style entre les paragraphes.
- Ensemble, perplexité + burstiness aident à distinguer un résultat plat et uniforme d’une écriture qui varie en ton, complexité et surprise.
Extraction de caractéristiques stylométriques et linguistiques
Pour aller au-delà de la prédiction brute de tokens, de nombreux détecteurs utilisent la stylométrie : une branche de la linguistique computationnelle qui quantifie le style d’écriture via des caractéristiques.
- Ils extraient des caractéristiques telles que la richesse du vocabulaire, le ratio type/token, l’utilisation des mots fonctionnels, la distribution de la longueur des phrases, les fréquences de ponctuation, les distributions des étiquettes POS (partie du discours), la répétition des n-grammes et les schémas syntaxiques.
- Certains schémas (par ex. la surutilisation d’adverbes de transition comme « de plus », une utilisation inhabituellement faible des contractions, des structures répétitives) peuvent être corrélés avec un style généré par l’IA.
- Les détecteurs peuvent également utiliser la similarité des embeddings ou les comparaisons dans l’espace vectoriel : convertir des phrases ou des paragraphes en embeddings (vecteurs sémantiques) et comparer la distance à des « clusters IA » ou « clusters humains » connus.
- Certains détecteurs utilisent des classifieurs (forêts aléatoires, SVM, réseaux neuronaux) entraînés sur des corpus étiquetés (texte humain vs texte généré par l’IA) avec ces caractéristiques stylométriques comme entrée.
Watermarking / Signaux cachés
Une autre technique émergente : le watermarking ou les « empreintes digitales » cachées intégrées dans le texte généré par l’IA.
- L’idée est que le modèle de génération biaise intentionnellement la sélection des tokens (de manière invisible) pour intégrer un watermark statistique — comme un faible signal dans les distributions de tokens.
- Au moment de la détection, le watermark peut être détecté via la vérification des écarts d’utilisation attendus des tokens. Par exemple, certains schémas de watermarking attribuent un sous-ensemble de vocabulaire « liste noire » à chaque étape en fonction du hachage des tokens précédents, rendant ces mots moins susceptibles d’apparaître (mais subtilement) pendant la génération. Au moment de la détection, vous comparez l’utilisation réelle aux attentes.
- Le watermarking est séduisant car il peut offrir une détection plus déterministe. Mais il est vulnérable à la post-édition, à la paraphrase ou au retraitement du texte, ce qui peut briser ou effacer le watermark.
Approches par ensembles, hybrides et méta-classifieurs
Aucune technique n’est infaillible. La plupart des détecteurs modernes utilisent des méthodes hybrides ou d’ensemble, combinant plusieurs signaux pour un verdict final.
- Ils fournissent des caractéristiques (scores de perplexité, métriques de burstiness, stylométrie, présence de watermark, distances d’embedding) à un méta-classifieur de plus haut niveau (par ex. régression logistique, réseau neuronal).
- Des recherches récentes proposent de pondérer les modèles par la perplexité inverse : des détecteurs construits sur plusieurs modèles transformers mais donnant plus de poids à ceux qui trouvent le texte moins prévisible (c’est-à-dire qu’une perplexité plus faible obtient un poids plus élevé) — un ensemble qui s’adapte à la difficulté du texte. Le système LuxVeri (COLING 2025) utilise précisément cette technique pour améliorer la robustesse dans tous les domaines.
- Certains modèles de détection intègrent également un entraînement contradictoire (adversarial) : ils s’entraînent délibérément sur des sorties d’IA paraphrasées ou manipulées afin que leurs classifieurs deviennent plus robustes à l’évasion.
- D’autres combinent des défenses basées sur la récupération (retrieval) : lorsqu’un texte candidat est suspect, le détecteur recherche dans une base de données de textes précédemment générés pour trouver des correspondances proches (indiquant une réutilisation ou une réplication). Si trouvée, cela augmente la probabilité d’IA. Les travaux sur l’évasion par paraphrase suggèrent que la récupération est l’une des défenses les plus fiables.
- Certains détecteurs calibrent les seuils ou les frontières de décision par genre, longueur ou domaine (par ex. des seuils différents pour les dissertations académiques et les articles de blog).
Différences algorithmiques entre les modèles courants de détecteurs d’IA
Les techniques des détecteurs d’IA diffèrent les unes des autres. Ci-dessous, je compare les principaux systèmes de détection (vous pouvez également consulter mon classement des détecteurs d’IA les plus fiables basé sur l’étude de référence RAID)
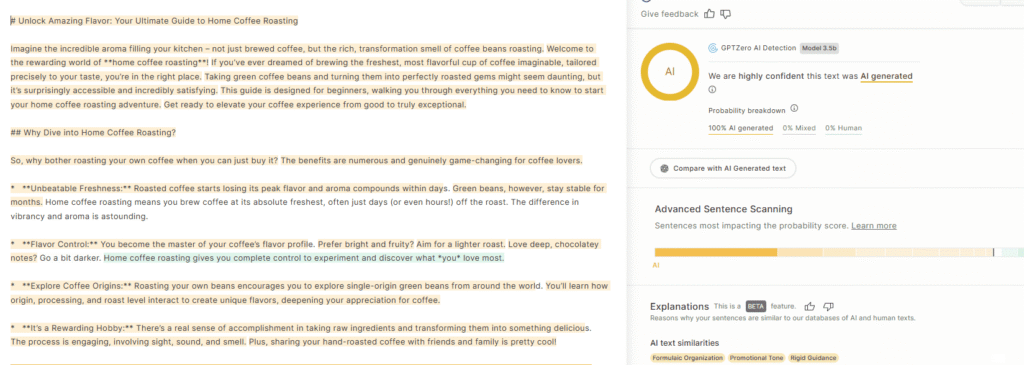
GPTZero : Le point de départ statistique + couches profondes
GPTZero est souvent traité comme un point de référence en détection. Sa renommée précoce repose sur la combinaison de la perplexité + burstiness comme « première couche » statistique.
Approche de base :
- GPTZero calcule les perplexités au niveau de la phrase à l’aide d’un modèle de langage (ou de substitution), puis mesure la variance (burstiness) entre ces phrases.
- Cette couche statistique donne un signal approximatif : les textes trop prévisibles ou trop uniformes sont plus suspects.
Mais GPTZero ne s’arrête pas là. Au fil du temps, il a superposé des fonctionnalités supplémentaires et des méthodes de classifieur :
- Il intègre des couches de classification ML qui prennent en compte plusieurs signaux au-delà de la simple uniformité ou prévisibilité.
- Il utilise une classification phrase par phrase et donne des scores de confiance et un surlignage (signalant les parties d’un document les plus susceptibles d’être de l’IA).
- GPTZero affirme s’entraîner sur un mélange de textes humains et générés par l’IA pour affiner sa logique de détection.
Détecteur d’écriture IA de Turnitin : Hybride & Embarqué
Turnitin, un acteur majeur du monde universitaire, a introduit la détection d’IA dans le cadre de sa boîte à outils d’analyse de texte plus large.
Architecture et méthodes de base :
- Turnitin superpose son module de détection d’IA à son infrastructure existante (qui gère le plagiat et la similarité).
- Il utilise un modèle entraîné pour détecter l’utilisation de l’IA générative dans les soumissions académiques. Le « modèle indicateur d’écriture IA » examine le « texte qualifiant » (prose longue) à la recherche de caractéristiques typiques de l’écriture IA.
- Turnitin ne divulgue pas publiquement l’intégralité de son fonctionnement interne ou de sa logique de seuil ; certains éléments sont propriétaires et opaques.
Différences d’approche par rapport à GPTZero :
- Turnitin est davantage une boîte noire — alors que GPTZero publie une certaine transparence sur ses fondements statistiques, le modèle de Turnitin est plus intégré et moins expliqué publiquement.
- Le modèle de Turnitin est conçu pour fonctionner à l’échelle du document dans des contextes académiques. Il signale des « sections » dans un texte (pas seulement des documents entiers) et fournit des pourcentages de texte probablement généré par l’IA.
- Les affirmations de précision rapportées par Turnitin incluent ~98% de détection pour le contenu IA, bien qu’avec des mises en garde et des avertissements concernant les faux positifs.
- Parce que Turnitin est lié aux systèmes éducatifs, il est optimisé pour les dissertations d’étudiants et peut avoir plus de difficultés en dehors de ces domaines (articles de blog, contenu marketing).
Originality AI : Classification holistique + Reconnaissance de formes
Originality AI se positionne comme un outil de détection d’IA premium qui combine la classification et l’analyse de formes à travers plusieurs modèles et langages.
Traits algorithmiques clés :
- Il traite la détection d’IA comme un problème de classification binaire : pour une phrase ou un bloc donné, il estime une probabilité qu’il ait été généré par l’IA. Si la probabilité dépasse un seuil, il le signale.
- Il affirme utiliser plusieurs modèles de langage dans son pipeline d’entraînement et de détection, y compris des modèles comme ChatGPT, Claude, Llama et d’autres. L’idée est de reconnaître des schémas à travers différents fournisseurs d’IA.
- Son score de détection est présenté comme un pourcentage de « confiance » (par ex. « 60% Original, 40% IA ») — mais le score n’est pas une répartition littérale entre contenu humain et IA ; c’est une évaluation probabiliste.
Copyleaks : Méthodes hybrides + Explicabilité
Copyleaks est plus connu pour la détection du plagiat, mais son module de détection d’IA est robuste et de plus en plus visible dans les cycles de contenu. Voici comment ils l’abordent :
Stratégies algorithmiques de base :
- Copyleaks affirme utiliser des schémas statistiques comme la perplexité, la burstiness, les formulations répétitives et d’autres irrégularités linguistiques dans son pipeline de détection.
- Le détecteur d’IA est intégré à une fonctionnalité « AI Logic » : il fait remonter des signaux (par ex. « Phrases IA ») qui montrent quelles parties du texte ont déclenché la suspicion. Cela vous donne plus d’informations sur pourquoi quelque chose a été signalé.
- Il utilise également un composant de correspondance de source : il vérifie si des parties du texte ressemblent à du contenu connu généré par l’IA qui existe déjà (publié ou dans leur base de données).
- Copyleaks met l’accent sur une grande précision et un large support de modèles, affirmant qu’il détecte le contenu de ChatGPT, Gemini, Claude, et plus encore.
Les détecteurs d’IA sont-ils vraiment fiables ?

Chaque détecteur d’IA fait essentiellement une supposition, une supposition éclairée, étayée par des données, mais une supposition quand même. Ils ne sont donc absolument pas fiables à 100 %.
Le défi sous-jacent est que l’écriture de l’IA et l’écriture humaine se chevauchent plus que jamais. Les grands modèles de langage sont entraînés sur de vastes quantités de texte humain. Ils ne produisent plus de charabia robotique ; ils répliquent le rythme, la variation et le ton humains. Ce chevauchement réduit la marge sur laquelle les détecteurs s’appuient.
Par exemple :
- Un article de blog humain bien écrit peut être signalé comme « probablement IA » simplement parce qu’il est structuré et fluide. C’est ce que sont les faux positifs (lorsque l’écriture humaine est mal classifiée comme IA). Et c’est peut-être le plus gros problème pour les marketeurs et les éducateurs.
- Inversement, un texte écrit par l’IA qui est légèrement reformulé ou réarrangé par un humain peut passer inaperçu. C’est ce que nous appelons un faux négatif. Des études montrent qu’une simple paraphrase peut réduire la précision de la détection de plus de 60 %. C’est précisément pourquoi fiabilité ne peut pas signifier certitude.
Biais & Limites
Plus encore, les détecteurs d’IA présentent des biais et des incohérences inhérents :
- Biais envers les non-anglophones : Les détecteurs d’IA peuvent afficher des biais, en particulier à l’encontre du contenu produit par des locuteurs non natifs de l’anglais, le classifiant souvent à tort comme généré par l’IA. Cela peut conduire à des situations où votre contenu authentique est signalé à tort.
- Impact des évolutions des modèles : l’avancement continu des modèles LLM fait perdre aux détecteurs d’IA en précision et en fiabilité avec le temps. Par exemple, il y a encore un écart énorme de précision concernant la détection de GPT-3.5 par rapport à GPT-4 et Claude 3. Les détecteurs d’IA doivent constamment s’adapter pour rester pertinents.
- Écriture formelle : une écriture plus formelle et structurée pourrait être plus susceptible d’être signalée comme du contenu IA par les détecteurs d’IA. C’est pourquoi certains outils comme Originality.AI avertissent les utilisateurs de ne revoir que l’écriture plus informelle.
Comment utiliser les détecteurs d’IA de manière responsable
Sur la base de tout cela, vous devez traiter les conclusions des détecteurs d’IA avec prudence :
- Utilisez plusieurs détecteurs. Vérifiez les résultats de manière croisée (par ex., GPTZero + Originality AI + Copyleaks). S’ils sont tous d’accord, vous pouvez être plus confiant. S’ils divergent, enquêtez.
- Lisez la couche d’explication. Des outils comme AI Logic de Copyleaks ou les surlignages de GPTZero montrent où l’algorithme a trouvé des formulations « de type IA ». Révisez ces lignes manuellement.
- Équilibrez le signal avec le contexte. Un score de 60 % d’IA sur un court paragraphe ne signifie pas plagiat. Considérez la longueur du texte, le genre et le contexte du prompt avant de décider.
- Éditez stratégiquement. Lorsque les détecteurs signalent du texte, ajustez le rythme, variez les formulations et insérez des détails concrets. C’est généralement suffisant pour augmenter la burstiness.
- Évitez la sur-optimisation. N’écrivez pas pour le détecteur ; écrivez pour la clarté et les lecteurs. Ironiquement, l’écriture centrée sur l’humain obtient naturellement de meilleurs scores.
- Éduquez les parties prenantes. Si des clients ou des éditeurs se fient aux scores des détecteurs, aidez-les à comprendre les limites. Partagez des études crédibles montrant les marges d’erreur.

Prompts gratuits et Ebook pour humaniser votre texte
Télécharger Maintenant
Buchert Jean-marc
Expert confirmé en processus de contenu IA. Par ses méthodes, il a aidé ses clients à générer du contenu de qualité qui correspond à leurs exigences éditoriales et aux attentes de leur public.
Tous les Articles
