Sommaire
- Techniquement, qu’est-ce qui définit l’exactitude d’un détecteur d’IA ?
- Les composantes de la précision
- Seuils et niveaux de confiance
- Les détecteurs d’IA actuels sont-ils vraiment fiables ?
- À quel niveau de précision devriez-vous vous attendre ?
- Comparaison de la précision des meilleurs détecteurs d’IA
- Originality.ai : Leader global + Forte résistance à la paraphrase
- GPTZero : Conservateur, résilient aux attaques, mais taux d’échec plus élevé
- Winston : Haute précision sur les modèles majeurs, mais couverture limitée
- Copyleaks
- Turnitin
Vous avez lu toutes ces promesses audacieuses : « Détection d’IA précise à 99 %. »
Mais la réalité est toute autre : Les détecteurs d’IA ne mesurent pas la « vérité », ils mesurent une probabilité. Et cette probabilité dépend de multiples facteurs.
Dans cet article, on décortique la fiabilité réelle à laquelle vous pouvez vous attendre.
Techniquement, qu’est-ce qui définit l’exactitude d’un détecteur d’IA ?

En termes simples, l’exactitude (accuracy) décrit la fréquence à laquelle un détecteur d’IA identifie correctly un texte comme étant humain ou généré par IA.
Mais l’histoire ne s’arrête pas là. Car la manière dont la précision est mesurée dépend fortement des données testées, de la façon dont les décisions ont été étiquetées et des seuils utilisés par le détecteur.
Imaginez que vous ayez 100 échantillons de texte — 50 humains, 50 générés par IA. Si votre détecteur en classe correctement 90, vous direz qu’il est précis à 90 %. Mais que se passe-t-il si les 10 erreurs sont des textes humains identifiés à tort comme provenant d’une IA ?
Les chiffres de précision mis en avant sur le marché ne reflètent que partiellement les performances réelles du détecteur dans le monde réel.
Ils sont souvent calculés dans des conditions de laboratoire contrôlées — de longs paragraphes propres, des exemples clairs d’écriture purement humaine ou purement IA. Les textes du monde réel sont plus désordonnés : hybrides, édités, paraphrasés et mélangeant différents tons.
C’est pourquoi nous devons examiner comment fonctionne réellement la précision de ces détecteurs.
Les composantes de la précision
Les détecteurs d’IA fonctionnent comme des classifieurs. Ils prennent un texte et prédisent : « humain » ou « IA ». Leur performance est suivie à l’aide d’une matrice de confusion — un tableau montrant à quelle fréquence ils obtiennent chaque prédiction correcte ou incorrecte.
À partir de là, on calcule :
- Exactitude (Accuracy) = proportion du total des décisions correctes.
(Par exemple, 90 correctes sur 100 = 90 % d’exactitude.) - Précision (Precision) = lorsque le détecteur dit « IA », à quelle fréquence il a raison.
- Rappel (Recall) = combien de textes IA le détecteur parvient à intercepter.
Voici pourquoi c’est important :
- Un détecteur avec une haute précision étiquette rarement à tort un texte humain, mais il peut manquer certaines productions d’IA.
- Un détecteur avec un haut rappel intercepte la plupart des textes IA, mais risque de sur-signaler les humains (faux positifs).
En raison de ce compromis, de nombreux chercheurs utilisent le score F1, une moyenne combinée de la précision et du rappel, pour mieux saisir l’équilibre global.
Seuils et niveaux de confiance
La plupart des détecteurs ne disent pas simplement « IA » ou « Humain ». Ils génèrent une probabilité (par ex. 0,84 de probabilité d’IA) puis appliquent un seuil — généralement autour de 0,5 ou 0,7. Tout ce qui est au-dessus est étiqueté IA ; tout ce qui est en dessous, humain.
Modifier ce seuil change l’équilibre de la performance :
- Des seuils plus bas capturent plus d’IA (rappel plus élevé) mais augmentent les faux positifs.
- Des seuils plus élevés protègent les textes humains (précision plus élevée) mais manquent les écrits d’IA subtils.
Les détecteurs bien calibrés visent à ce que ces probabilités correspondent aux probabilités réelles — un score de 80 % devrait signifier « environ 8 chances sur 10 d’avoir raison ». Un mauvais calibrage est l’une des raisons pour lesquelles des détecteurs similaires peuvent être en désaccord.
Les détecteurs d’IA actuels sont-ils vraiment fiables ?
On voit des outils de détection se vanter d’une précision de 90 %+, 98 %, voire « plus de 99 % ». Cela semble impressionnant, mais en pratique, tiennent-ils leurs promesses ?
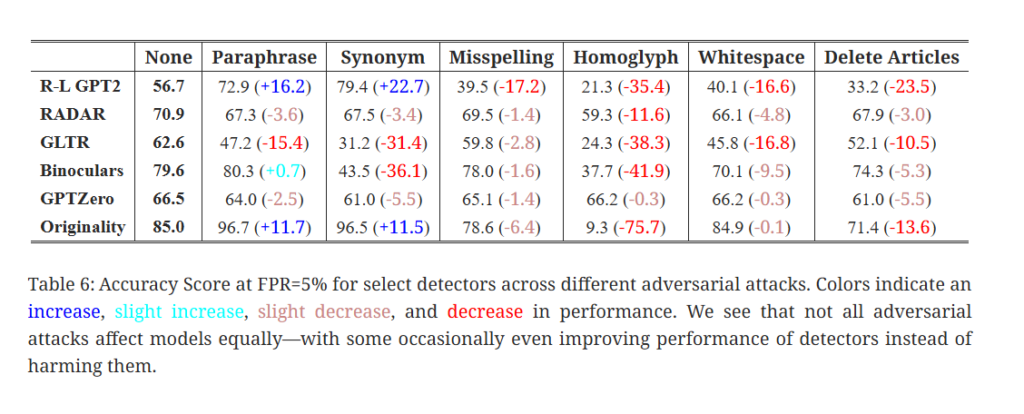
Le benchmark RAID (« Robust AI Detection ») est l’une des évaluations publiques les plus ambitieuses à ce jour. Il couvre plus de 6 millions de textes générés par 11 LLM différents, 8 domaines de contenu, 4 stratégies de décodage et 11 attaques adverses (adversarial attacks).
Les principales conclusions du RAID incluent :
- De nombreux détecteurs qui revendiquent « 99 % de précision » échouent lamentablement dans des conditions non standard (par ex. échantillonnage alternatif, répétition pénalisée, modèles inconnus).
- La performance chute considérablement lorsque les détecteurs sont confrontés à du texte modifié de manière adverse (paraphrase, substitution de synonymes, changement de structure). Même de petites perturbations réduisent la précision.
- Le benchmark RAID suggère qu’une exactitude de 85 % dans des contextes larges est plus réaliste que « 99 %+ partout ». Face à des textes adverses ou hors domaine, la performance tombe souvent dans la fourchette des 60 %.
Plusieurs facteurs contribuent à cet écart entre la précision revendiquée et la performance réelle :
- Contenu IA édité ou paraphrasé
Dès qu’un humain touche à un texte généré — en reformulant, ajoutant des nuances, changeant l’ordre des mots — les signaux clés sur lesquels les détecteurs s’appuient (par ex. prévisibilité, formulation uniforme) s’estompent ou disparaissent. Une grande expérience sur la détection GenAI (Perkins et al. 2024) a trouvé une exactitude de base de ~39,5 % dans les tâches de détection d’IA standard. Lorsque des modifications adverses ont été introduites (par ex. paraphrase, légères modifications), l’exactitude chutait à ~17,4 %. - Inadéquation du domaine et variation de style
Les détecteurs entraînés sur des données génériques académiques ou d’actualités peuvent avoir du mal avec les textes marketing, la poésie, l’argot ou le vocabulaire de niche. Si le style de votre contenu diverge de l’ensemble d’entraînement du détecteur, la précision en souffre. - Texte court ou fragments
La plupart des détecteurs nécessitent une quantité minimale de contexte textuel pour porter un jugement raisonnable. De courts paragraphes ou des phrases isolées peuvent ne pas présenter suffisamment de schémas ou de signaux. - Faux positifs sur des écrits humains « trop parfaits »
Des écrits humains très édités et raffinés (par des rédacteurs professionnels ou des éditeurs) peuvent ressembler à une production d’IA dans leur uniformité. Certains détecteurs signalent à tort de tels textes comme étant de l’IA. - Problèmes de seuil et de calibrage
Le seuil de « confiance » d’un détecteur (par ex. 0,5, 0,7) est souvent ajusté sur des données de laboratoire. Ce seuil peut ne pas se généraliser à votre texte, entraînant des erreurs de classification. De plus, certains détecteurs sont sur-confiants : leur probabilité interne ne correspond pas à la fréquence à laquelle ils ont raison en pratique. - Biais envers les non-anglophones : Les détecteurs d’IA peuvent faire preuve de biais, en particulier envers le contenu produit par des locuteurs non natifs de l’anglais, le classant souvent à tort comme généré par IA. Cela peut conduire à des situations où votre contenu authentique est signalé incorrectement.
- Impact de l’évolution des modèles : les progrès continus des modèles LLM font perdre aux détecteurs d’IA en précision et en fiabilité avec le temps. Par exemple, il y a toujours un écart de précision énorme dans la détection de GPT-3.5 par rapport à GPT-4 et Claude 3. Les détecteurs d’IA doivent constamment s’adapter pour rester pertinents.
À quel niveau de précision devriez-vous vous attendre ?
Compte tenu de toutes ces limites, quelle est une attente réaliste ?
- Pour des sorties d’IA pures et non éditées (directement issues des modèles), de nombreux détecteurs peuvent atteindre 70–90 % d’exactitude dans des tests contrôlés.
- Mais dès que vous introduisez de l’édition, des variations de domaine, de la paraphrase ou des échantillons courts, l’exactitude tombe souvent à 50–70 % ou moins.
- En présence de modifications adverses, certains détecteurs tombent sous les 20–40 % d’exactitude.
- Les taux de faux positifs sont particulièrement préoccupants : certains détecteurs signalent incorrectement des portions substantielles d’écrits humains, en particulier lorsqu’ils traitent des textes soignés ou formels.
Ainsi, l’affirmation « 98 % de précision » que vous voyez dans les publicités doit être lue avec scepticisme — et comprise comme reflétant des conditions idéales, et non votre contenu quotidien.
Comparaison de la précision des meilleurs détecteurs d’IA
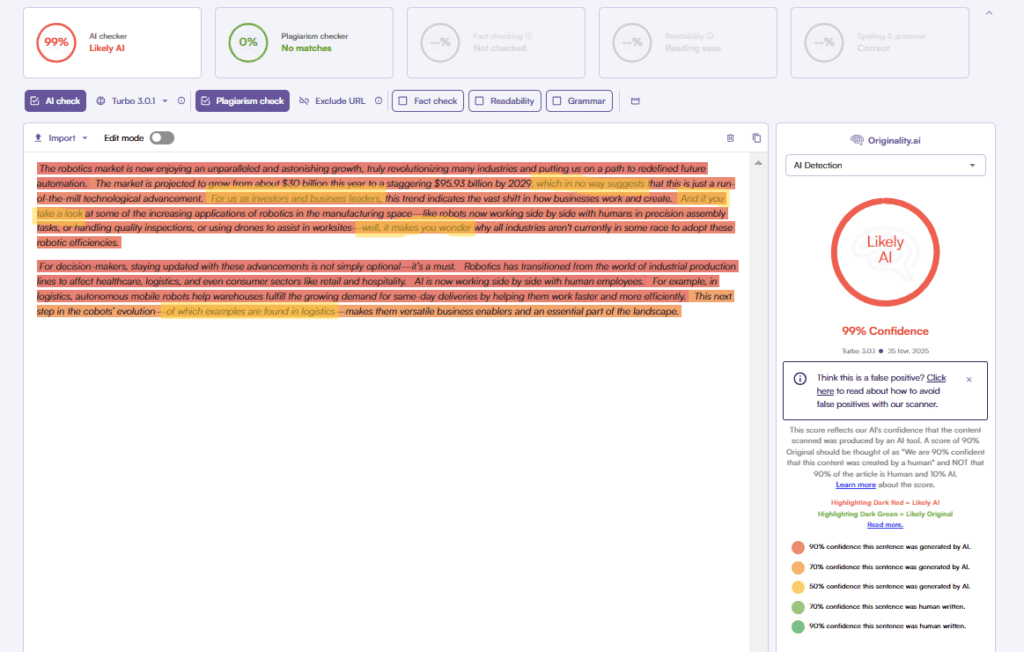
La précision des détecteurs d’IA varie d’un outil à l’autre. Nous comparons ici le taux de précision réel des principaux outils de détection d’IA sur le marché, sur la base de l’étude RAID et d’autres articles (vous pouvez également consulter notre classement des détecteurs d’IA les plus fiables ici).
Originality.ai : Leader global + Forte résistance à la paraphrase
Performance globale
- Dans les données de base (non adverses) de RAID, Originality.ai s’est classé premier au total avec ~85 % d’exactitude à un seuil de 5 % de faux positifs.
- Sur le contenu IA paraphrasé (obfusqué), il a atteint 96,7 % d’exactitude, bien au-dessus de la moyenne de ~59 % des autres détecteurs du benchmark.
- Dans les tests adverses (11 types d’attaques), Originality.ai s’est classé 1er dans 9 attaques, et 2e dans une autre, indiquant une robustesse face à de nombreuses stratégies d’obfuscation.
Forces et faiblesses
- Sa force réside dans la détection de texte IA paraphrasé, une technique d’évasion courante.
- Cependant, il a montré une robustesse plus faible contre certaines attaques de niche : homoglyphes (remplacement de caractères par des sosies) et insertions de caractères de largeur nulle.
- Ses affirmations de très haute précision (par ex. « 98,2 % de précision sur le contenu ChatGPT ») font référence à un sous-ensemble plus étroit (spécifiquement les sorties de ChatGPT), et non à l’ensemble des modèles.
- Parce que le test est calibré à un seuil de 5 % de faux positifs, sa performance dépend de ce seuil. Si vous modifiez les seuils (autorisez plus de faux positifs), la performance peut changer.
GPTZero : Conservateur, résilient aux attaques, mais taux d’échec plus élevé
Performance globale
- L’exactitude rapportée de GPTZero dans RAID (sur tous les modèles) est significativement inférieure à celle d’Originality.ai — environ 66,5 %, ce qui signifie qu’il ne détecte pas ~33–35 % des sorties d’IA dans ce contexte. (Note : votre point de données s’alignant sur 66,5 % est proche des évaluations publiquement discutées.)
- Face aux manipulations adverses, l’exactitude de GPTZero ne baisse que légèrement — par ex. sous des attaques d’homoglyphes, il voit très peu de déclin (parfois ~0,3 % de baisse), montrant une résilience aux astuces au niveau des caractères qui perturbent d’autres détecteurs.
Forces et faiblesses
- Il a un très faible taux de faux positifs à des seuils stricts (c’est-à-dire qu’il étiquette rarement à tort un texte humain clair comme IA dans des réglages à faible FPR). Il surpasse parfois Originality.ai dans la minimisation des faux positifs.
- Parce que GPTZero met l’accent sur la perplexité et la « burstiness » (variation/salve), des modifications mineures ou des obfuscations qui ne changent pas la prévisibilité globale peuvent ne pas le tromper facilement — c’est l’une des raisons de sa stabilité relative sous attaque adverse.
- Mais sa sensibilité est plus faible : il manque de nombreux textes IA, en particulier dans les cas difficiles ou obfusqués. Son exactitude globale est plus faible.
- Il a également des difficultés avec les textes courts ou les extraits — lorsque vous lui donnez des passages très brefs, il renvoie souvent « informations insuffisantes » ou des prédictions à faible confiance. (Ceci est connu de par l’utilisation large de l’outil, bien que pas toujours mesuré dans RAID.)
- En raison de sa conception conservatrice, GPTZero est plus sûr dans les contextes où les faux positifs (accuser à tort un texte humain) sont coûteux (par ex. le milieu universitaire), mais au prix de manquer du contenu IA.
Winston : Haute précision sur les modèles majeurs, mais couverture limitée
Performance globale
- Dans RAID, il est rapporté que Winston atteint une haute exactitude sur le contenu généré par GPT-3.5 / GPT-4, atteignant parfois ~90 % d’exactitude de classification dans ces sous-ensembles (bien que ne battant pas Originality.ai au total).
- Cependant, sur tous les modèles d’IA testés dans RAID, l’exactitude globale de Winston est plus faible (souvent citée ~71 %), car il performe faiblement sur les modèles ouverts ou les styles de génération moins courants.
Forces et faiblesses
- Il est plus optimisé ou « réglé » sur les schémas des modèles grand public ; lorsqu’il est confronté à des modèles non familiers ou moins représentés, il généralise mal.
- Sa capacité à intercepter les sorties de modèles bien connus (en particulier de GPT-3.5/4) est forte — bonne pour de nombreux cas d’utilisation courants.
- Il gère raisonnablement bien le texte IA édité dans certains scénarios, ce qui signifie que si vous humanisez modérément le contenu IA, Winston en signale toujours une grande partie.
- Mais Winston a des taux de faux positifs plus élevés par rapport à GPTZero et Originality.ai, en particulier sous des seuils plus lâches (~1 % ou plus).
Copyleaks
Résultats indépendants ou critiques
- Une analyse de Webspero a trouvé l’exactitude de Copyleaks autour de 53,4 % dans certains tests mixtes ou cas limites, bien inférieure à ce qui est revendiqué. Webspero Solutions
- Certains rapports d’utilisateurs et commentaires de forums suggèrent que Copyleaks peut mal classifier le texte humain, en particulier lorsque l’écriture est soignée. Reddit
- Dans une analyse, l’exactitude de Copyleaks a chuté de manière significative (de 100 % à ~50 %) lorsqu’il est passé par un outil de paraphrase comme QuillBot. Winston AI
Turnitin
Résultats indépendants et critiques
- L’étude Game of Tones a montré que les enseignants utilisant Turnitin signalaient 54,5 % des soumissions expérimentales, soulignant que la détection est partielle, et non absolue.
- Dans l’étude plus large sur la détection GenAI, lorsque les détecteurs étaient confrontés à du texte manipulé (adverse), l’exactitude des outils de type Turnitin chutait de ~39,5 % à ~17,4 %.
- Certains rapports suggèrent que le détecteur de Turnitin est biaisé envers les locuteurs non natifs de l’anglais, car leurs structures de phrases plus simples ressemblent plus souvent à l’IA aux yeux du détecteur.
Turnitin est largement utilisé — en particulier dans le milieu universitaire — et dispose d’une infrastructure robuste. Mais ses performances doivent être interprétées avec prudence, en particulier dans les cas nuancés ou adverses. Il ne remplace pas l’évaluation par un enseignant.

Prompts gratuits et Ebook pour humaniser votre texte
Télécharger Maintenant
Buchert Jean-marc
Expert confirmé en processus de contenu IA. Par ses méthodes, il a aidé ses clients à générer du contenu de qualité qui correspond à leurs exigences éditoriales et aux attentes de leur public.
Tous les Articles