Sommaire
L’IA peut combler l’angoisse de la page blanche, mais encore faut-il choisir le bon modèle IA (LLM).
Voici le classement des LLMs les plus fiables, basé sur leurs véritables capacités de rédaction.
On vous propose également une analyse sur sept tâches d’écriture différentes, pour vous donner un aperçu concret de leur style et de leur plume.

✨ Découvrez Muse — L’IA conçue pour les romanciers
Si vous avez toujours rêvé d’un LLM capable d’écrire avec de l’émotion, du rythme et une vraie personnalité, Muse de Sudowrite est fait pour vous. C’est le seul modèle entraîné exclusivement sur de la littérature et de la fiction de haute volée. Vos scènes, personnages et dialogues n’auront jamais paru aussi vivants.
Testé et chaudement recommandé par notre équipe !
*Aucune carte bancaire requise – ouvrez simplement Sudowrite et testez Muse.*
Notre méthode de classement
Pour dénicher les meilleurs modèles pour la rédaction, nous avons utilisé deux filtres : des données objectives et des mises en situation réelles.
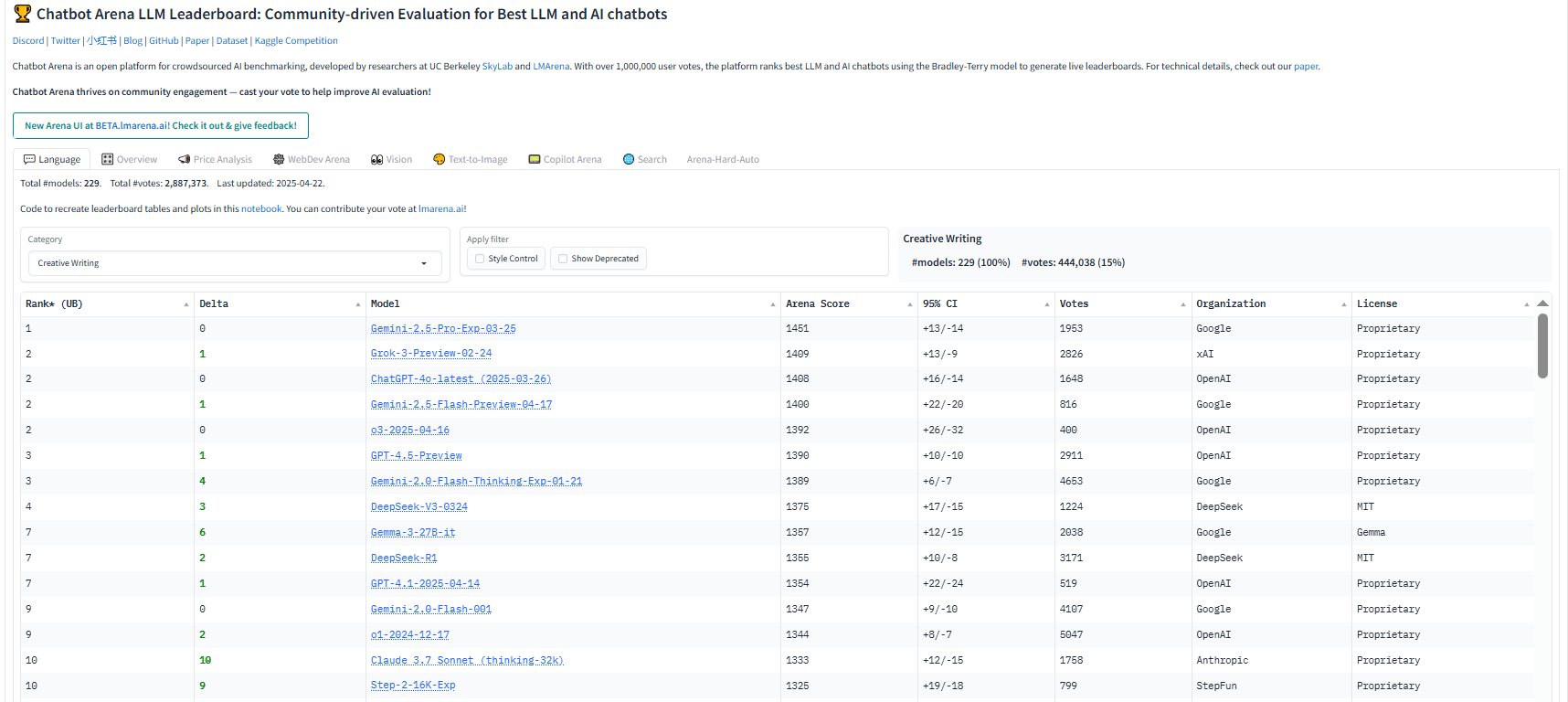
1. Les données de la Chatbot Arena
La Chatbot Arena est un classement participatif géré par LMSYS. Elle compare les LLM en fonction des préférences des utilisateurs sur de nombreuses tâches, dont la création littéraire.
Nous avons extrait les modèles figurant dans le classement « Creative Writing » (Rédaction Créative). Cela nous donne une base solide : quels sont les LLM qui s’en sortent le mieux lorsque de vrais humains évaluent la qualité de leur plume ?
Nous avons ensuite croisé ces résultats avec leurs performances générales. Si un modèle est bien mieux classé en rédaction qu’en moyenne générale, c’est le signe d’une véritable spécialisation (surtout pour les petits modèles).
2. Nos propres tests de terrain
Nous avons conçu sept exercices qui reflètent le quotidien des professionnels du contenu :
- Une scène de fiction (avec des contraintes créatives strictes)
- Un poème (respectant métrique, imagerie et chute)
- Un article de blog optimisé SEO (placement de mots-clés et structure logique)
- Une page de vente / Landing page (hiérarchisation de l’information et persuasion)
- Un essai au format court (thèse claire et références)
- Une note de recherche scientifique (citations et exactitude factuelle)
1. Claude (Opus 4.6)

S’il ne fallait retenir qu’une seule famille de LLM pour la rédaction aujourd’hui, mon choix se porterait sans hésiter sur Claude Opus 4.6.
La raison est simple : Claude insuffle de la vie dans ses phrases. Il surpasse la concurrence pour maintenir un ton constant, écrire des dialogues qui sonnent juste et porter une charge émotionnelle sur l’ensemble d’un texte, et pas seulement sur un paragraphe isolé.
Claude n’est pas toujours le plus scolaire des rédacteurs. Pour du contenu très technique (tutoriels) ou des sections SEO ultra-factuelles, Gemini peut parfois se montrer plus précis. Mais c’est le prix à payer pour l’avantage majeur de Claude : un rythme percutant, des tournures de phrases idiomatiques et l’absence quasi totale de ce « ton IA » professoral si agaçant.
Spécificités techniques (Claude Opus 4.6)
- Fenêtre de contexte (entrée) : 1 000 000 de tokens. Limite de sortie (par réponse) : jusqu’à 128 000 tokens. L’API d’Anthropic confirme l’intégration du raisonnement étendu (extended thinking) et cette généreuse limite de génération.
- Disponibilité : API Anthropic, Google Vertex AI, Amazon Bedrock.
- Hébergement local/privé : Impossible. Claude reste un modèle propriétaire, indisponible en « open-weights ».
Analyse de nos tests pratiques
- Écriture créative (nouvelle + sonnet) : C’est le terrain de jeu de Claude. Dialogues fluides, intentions des personnages crédibles, et un rythme impeccable en poésie. Le texte semble avoir été pensé, et non pas assemblé. Idéal pour le storytelling ou le copywriting de marque.
- Structure SEO et rédaction : Claude suit bien les consignes, mais a tendance à s’envoler vers un style un peu trop lyrique. Très bien pour le narratif, un peu moins pour l’intention de recherche pure. Il faut le cadrer avec des mots-clés stricts et des limites de mots.
- Essai argumentatif : C’est là que le duo Opus → Sonnet excelle. Opus 4.6 structure l’argumentation complexe à merveille, tandis que Sonnet 4.6 est redoutable pour les révisions rapides.
2. Gemini (3.1 Pro)

À mon sens, Gemini 3.1 Pro est l’outil parfait pour le « travail sérieux ». Sa force réside dans sa capacité de raisonnement, sa maîtrise des contextes kilométriques et sa rigueur factuelle.
Il brille particulièrement en rédaction SEO, dans la création de longs essais et pour les contenus nécessitant de digérer beaucoup de recherches documentaires sans perdre le fil.
Analyse de nos tests pratiques
- De l’outline SEO au brouillon : Il est excellent pour bâtir des hiérarchies H2/H3 propres et coller à l’intention de recherche. Gemini fait gagner un temps précieux en édition en évitant les digressions.
- Contenus longs et documentation : Avec son million de tokens de contexte, vous pouvez lui fournir toute votre charte éditoriale, vos notes et vos sources d’un coup. Le résultat est bluffant de synthèse.
- Exactitude factuelle : Il hallucine très peu. Pour le content marketing B2B, cela compte bien plus qu’une belle figure de style.
3. Grok (Grok 4.2)

Si je devais compléter le podium, Grok 4.2 y aurait sa place sans rougir.
Grok a de l’audace. Il n’a pas peur de prendre parti, de glisser des références inattendues et d’afficher un ton tranché. C’est l’IA idéale pour les billets d’humeur, les prises de parole de fondateurs (Thought Leadership) ou tout contenu nécessitant une vraie personnalité plutôt qu’un ton encyclopédique neutre.
Analyse de nos tests pratiques
- Créativité : Grok a été le modèle le plus imprévisible (dans le bon sens du terme). Il ose des retournements de situation surprenants. Ça ne fait pas toujours mouche, mais ce n’est jamais ennuyeux.
- Essais et tribunes : Il propose souvent des angles que les autres modèles ignorent, adoptant une approche plus piquante que consensuelle.
- Connexion web : Son accès en temps réel au web (via X) lui donne un vernis très ancré dans la culture actuelle, mais nécessite une bonne relecture factuelle par l’humain.
4. ChatGPT (GPT-5.4)
GPT-5.4 d’OpenAI reste un incontournable pour les essais, la vulgarisation et le SEO. Mais en matière de pure « plume », il reste au pied du podium.
Pourquoi ? À cause de sa texture créative. Bien que plus nuancé que ses prédécesseurs, GPT-5.4 produit encore des récits qui semblent parfois « fabriqués » algorithmiquement. C’est très propre, mais émotionnellement assez plat.
Analyse de nos tests pratiques
- Excellence SEO : Son respect de l’intention de recherche et sa structuration impeccable en font une machine à produire du contenu web efficace. Sa capacité à utiliser des outils (recherche web, analyse de fichiers) directement depuis l’interface le rend ultra productif.
- Ton corporate : C’est sa zone de confort. Si la voix de votre marque est neutre, claire et professionnelle, GPT-5.4 fera le job avec un minimum de retouches.
5. DeepSeek (V3.2-Exp / V3.1 / R1)
DeepSeek V3.1 est de loin le modèle open-source le plus polyvalent du marché. Il est bon partout (fiction, essais, SEO), sans être un virtuose dans un domaine précis.
Son atout majeur est sa nature ouverte : vous pouvez l’auto-héberger, l’affiner (fine-tuning) et échapper à l’emprise des géants de la tech. C’est une aubaine pour les entreprises soucieuses de la confidentialité de leurs données.
6. Qwen (Qwen 2.5-Max / Qwen 3)

Qwen est l’autre poids lourd de la catégorie open-source face à DeepSeek.
Il excelle particulièrement dans la création de documents très structurés (livres blancs, revues de littérature). S’il manque un peu de l’instinct narratif d’un Claude pour la fiction, sa rigueur d’organisation (grâce à ses modes de raisonnement poussés) en fait un allié de choix pour la non-fiction pointue.
7. Mistral (Medium 3 / Large 2.1)
Mistral reste la fierté européenne en matière d’IA open-source.
C’est le choix privilégié des entreprises souhaitant garantir la conformité RGPD de leurs flux de données. Niveau rédaction, il se situe dans la moyenne haute : structuré, prévisible et clair, quoiqu’un peu mécanique par moments. Sa plume créative manque de la chaleur de Claude, mais pour du copywriting ou du SEO, il livre une prestation très solide et facile à éditer.
8. Muse 1.5 (Sudowrite)
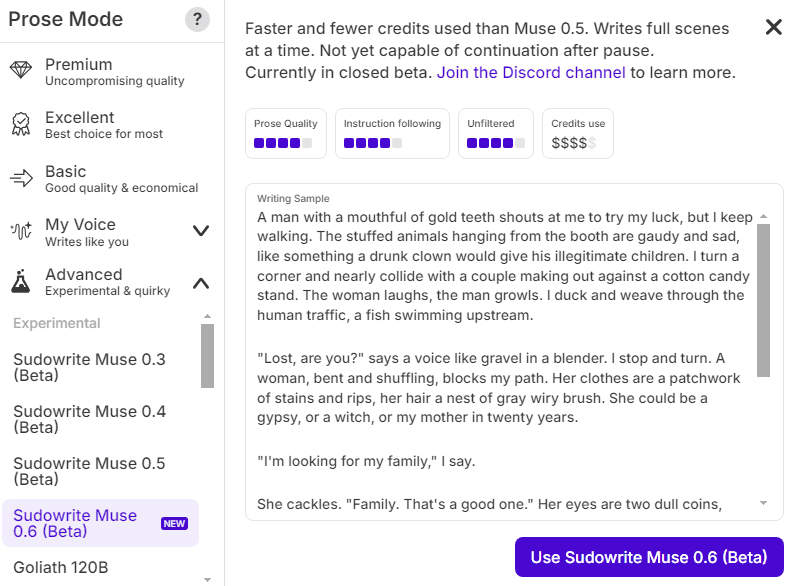
Muse est un ovni : c’est le seul LLM spécifiquement conçu par et pour les auteurs de fiction. Sa force de frappe narrative lui permet de tenir la distance sur un chapitre entier sans s’égarer. De plus, il n’applique pas les filtres de censure habituels sur la violence ou les thèmes matures, ce qui est crucial pour les auteurs de polars ou de dark fantasy.
Ses limites ? Il est exclusif à la plateforme Sudowrite et se révèle peu pertinent pour rédiger un article de blog SEO. Mais pour écrire un roman, c’est l’outil ultime.

Prompts gratuits et Ebook pour humaniser votre texte
Télécharger Maintenant
Buchert Jean-marc
Expert confirmé en processus de contenu IA. Par ses méthodes, il a aidé ses clients à générer du contenu de qualité qui correspond à leurs exigences éditoriales et aux attentes de leur public.
Tous les Articles